
-
 Alessio Di Domizio
Alessio Di Domizio - Tutti gli Appunti Digitali
- 11 Marzo 2011
La Cina verso l’autarchia tecnologica
È dagli anni '90 che, da dietro gli scranni e le scrivanie delle stanze del…

-
Pleg
- Grafica & Silicio
- 24 Febbraio 2011
Kepler, Maxwell, Denver, Tegra: dove va NVidia?
In una luminosa mattina californiana del novembre 2010, Jensen Huang, fondatore, presidente e CEO di…
-
Pleg
- Processori & Design
- 7 Febbraio 2011
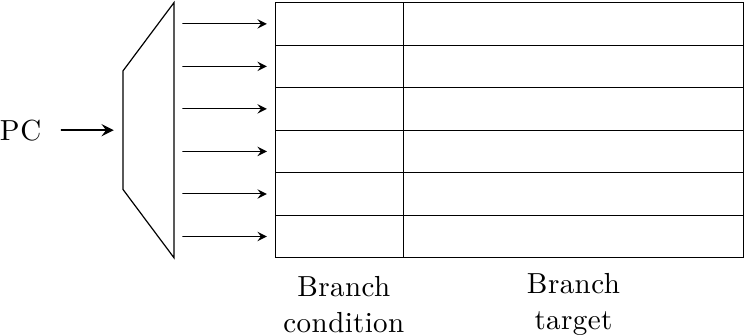
Branch prediction (parte seconda): Predittori semplici
Nello scorso articolo abbiamo visto perchè la Branch Prediction è una componente essenziale dei processori…

-
Felice Pescatore
- Nostalgia Informatica
- 7 Gennaio 2011
European MS DOS 4
Sul web è facile farsi un’idea di quelli che, temporalmente, sono i principali sistemi operativi…
-
Pleg
- Processori & Design
- 3 Gennaio 2011
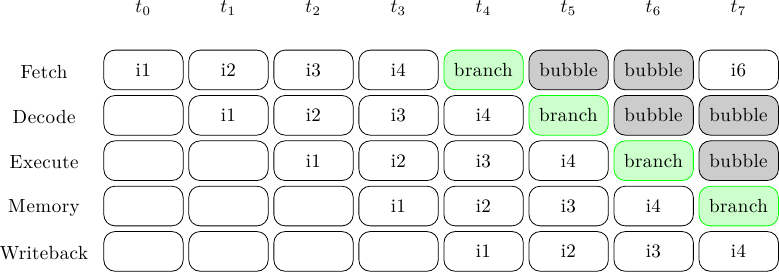
Processori superscalari out-of-order: Branch prediction (parte prima)
Dopo una lunghissima pausa (causa tapeout) eccoci di nuovo qui con una nuova puntata sull'architettura…

-
Felice Pescatore
- Nostalgia Informatica
- 22 Ottobre 2010
Faggin premiato da Obama
Abbiamo approfonditamente parlato di Federico Faggin e della nascita del primo microprocessore della storia in…
-
Pleg
- Processori & Design
- 17 Settembre 2010
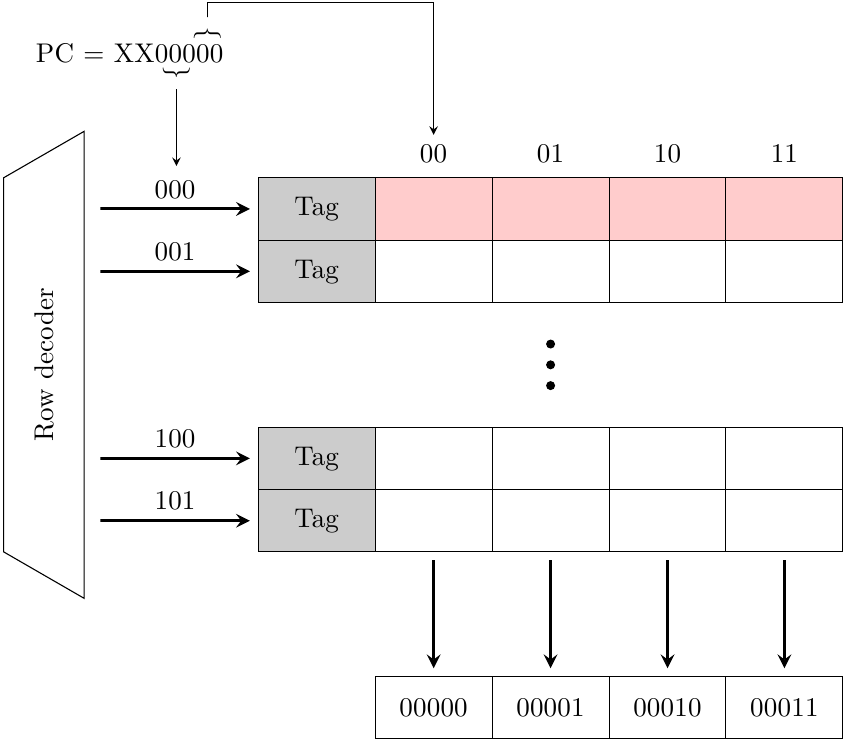
Processori superscalari out-of-order: lo stadio di fetch
In-order o out-of-order, superscalare o meno, il viaggio delle istruzioni all'interno di qualsiasi CPU comincia…

-
Felice Pescatore
- Nostalgia Informatica
- 10 Settembre 2010
Un pezzo d’Italia nei Microprocessori
Siamo abituati ad attribuire le grandi innovazioni del settore informatico ad aziende e a tecnici…
-
Pleg
- Processori & Design
- 16 Agosto 2010
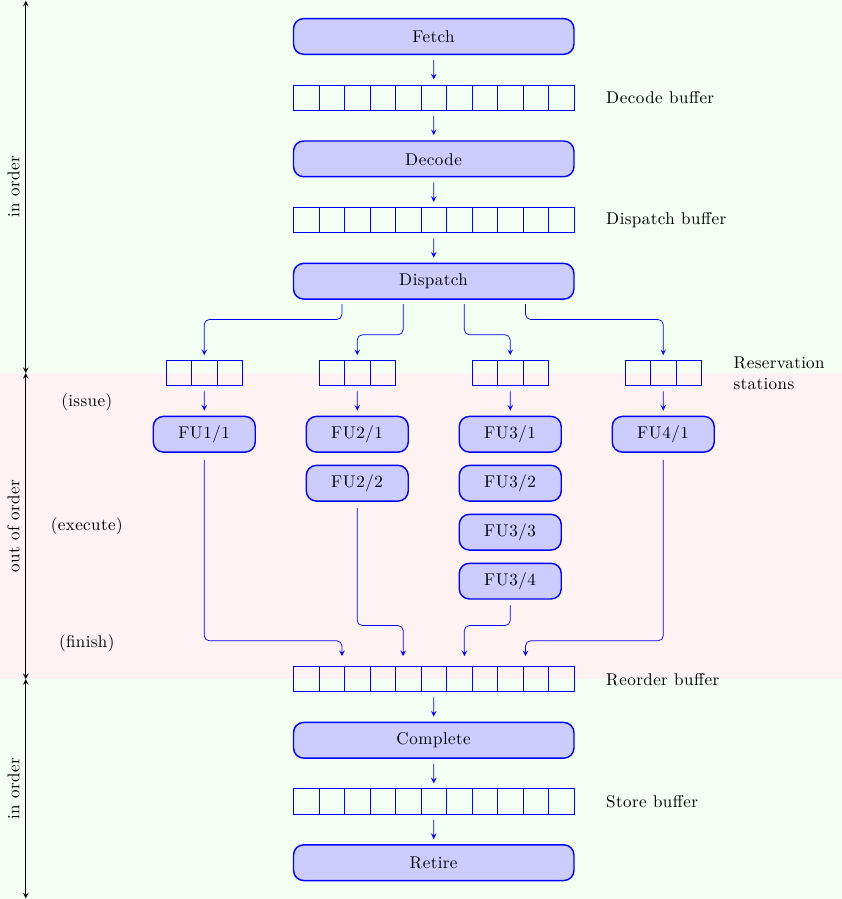
Processori superscalari out-of-order: una vista d’insieme
Finalmente, dopo una lunga peregrinazione tra pipeline semplici e diversificate, oggi comincia una nuova serie…
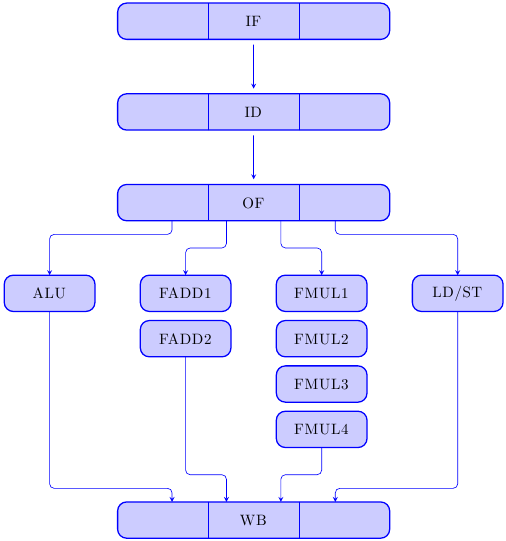
-
Pleg
- Processori & Design
- 2 Luglio 2010
Oltre la pipeline semplice: le pipeline diversificate
Nello scorso articolo abbiamo visto come pipeline profonde diventino rapidamente inefficienti a causa dell'aumento del…
In Appunti Digitali cerchiamo di esprimere punti di vista informati su questioni che conosciamo, materie che pratichiamo professionalmente o passioni seguite a lungo e con metodo. Nei limiti del poco tempo che possiamo dedicare alla scrittura di articoli, speriamo di aiutarvi a costruirvi un’opinione su materie complesse, informarvi e se possibile divertirvi. I conti del server li paghiamo di tasca nostra e ci riserviamo perciò di moderare i commenti a nostra discrezione.







