-
 Cesare Di Mauro
Cesare Di Mauro - Pensieri da Coder
- 11 Luglio 2024
Photonic CPUs still have a lot to clarify (and be expected)
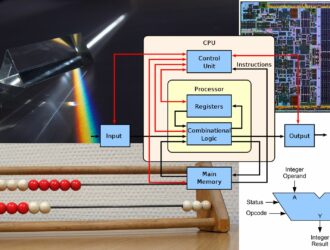
A scientific publication has recently appeared concerning what is being hailed as a revolution in…
-
Cesare Di Mauro
- Pensieri da Coder
- 11 Luglio 2024
Le CPU fotoniche hanno ancora parecchio da chiarire (e da farsi aspettare)
Di recente è apparsa una pubblicazione scientifica riguardo ciò che viene decantata come una rivoluzione…

-
Cesare Di Mauro
- Pensieri da Coder
- 25 Gennaio 2024
NEx64T – 9: conclusions
The series dedicated to the new NEx64T architecture has come to an end, after being…
-
Cesare Di Mauro
- Pensieri da Coder
- 25 Gennaio 2024
NEx64T – 9: conclusioni
La serie dedicata alla nuova architettura NEx64T è arrivata al capolinea, dopo averla confrontata con…

-
Cesare Di Mauro
- Pensieri da Coder
- 11 Gennaio 2024
NEx64T – 8: comparison with other architectures
The previous article completed the overview of NEx64T, so it is now possible to have…
-
Cesare Di Mauro
- Pensieri da Coder
- 10 Gennaio 2024
NEx64T – 8: confronto con altre architetture
Il precedente articolo ha completato la panoramica di NEx64T, per cui è adesso possibile disporre…

-
Cesare Di Mauro
- Pensieri da Coder
- 27 Dicembre 2023
NEx64T – 7: the new SIMD/vector unit
With the hot potato of the x86/x64 legacy out of the way, let us now…
-
Cesare Di Mauro
- Pensieri da Coder
- 27 Dicembre 2023
NEx64T – 7: la nuova unità SIMD/vettoriale
Tolta di mezzo la patata bollente dell'eredità di x86/x64, passiamo adesso a esaminare la nuova…

-
Cesare Di Mauro
- Pensieri da Coder
- 20 Dicembre 2023
NEx64T – 6: the legacy of x86/x64
Legacy is an inescapable concept when it comes to x86 and x64 architectures, so after…
-
Cesare Di Mauro
- Pensieri da Coder
- 20 Dicembre 2023
NEx64T – 6: il legacy di x86/x64
Il legacy è un concetto imprescindibile quando si parla delle architetture x86 e x64, per…
In Appunti Digitali cerchiamo di esprimere punti di vista informati su questioni che conosciamo, materie che pratichiamo professionalmente o passioni seguite a lungo e con metodo. Nei limiti del poco tempo che possiamo dedicare alla scrittura di articoli, speriamo di aiutarvi a costruirvi un’opinione su materie complesse, informarvi e se possibile divertirvi. I conti del server li paghiamo di tasca nostra e ci riserviamo perciò di moderare i commenti a nostra discrezione.







