
-
 Pleg
Pleg - Grafica & Silicio
- 17 Maggio 2012
AMD e NVidia: l’evoluzione della specie (parte 2)
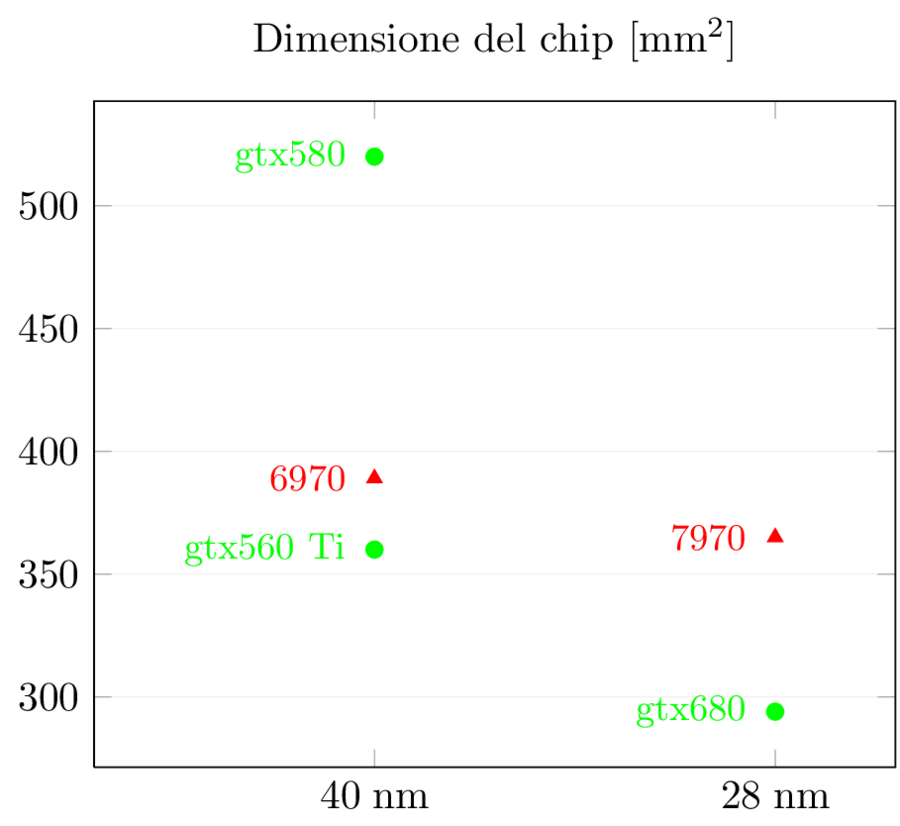
Dopo aver visto i numeri di base e le prestazioni per area delle nuove GPU…
-
Pleg
- Grafica & Silicio
- 2 Maggio 2012
AMD e NVidia: l’evoluzione della specie (parte 1)
Questi anni di rapide e dirompenti innovazioni tecnologiche stanno regalando grandi emozioni a tutti noi…

-
Pleg
- Tutti gli Appunti Digitali
- 24 Novembre 2011
Notizie semi-accurate o semi-inventate?
Disclaimer: l'autore di questo pezzo lavora per una parte chiamata in causa dall'articolo che commenta,…
-
Pleg
- Processori & Design
- 10 Novembre 2011
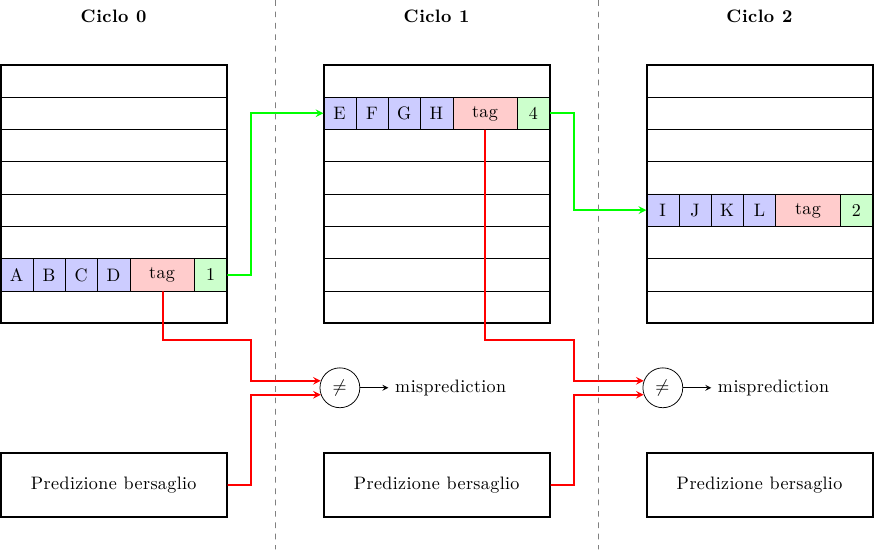
Branch prediction (parte settima): High-frequency fetch
Per trent'anni, prima che il raggiungimento del power wall terminasse la "corsa ai GHz" e…
-
Pleg
- Processori & Design
- 20 Ottobre 2011
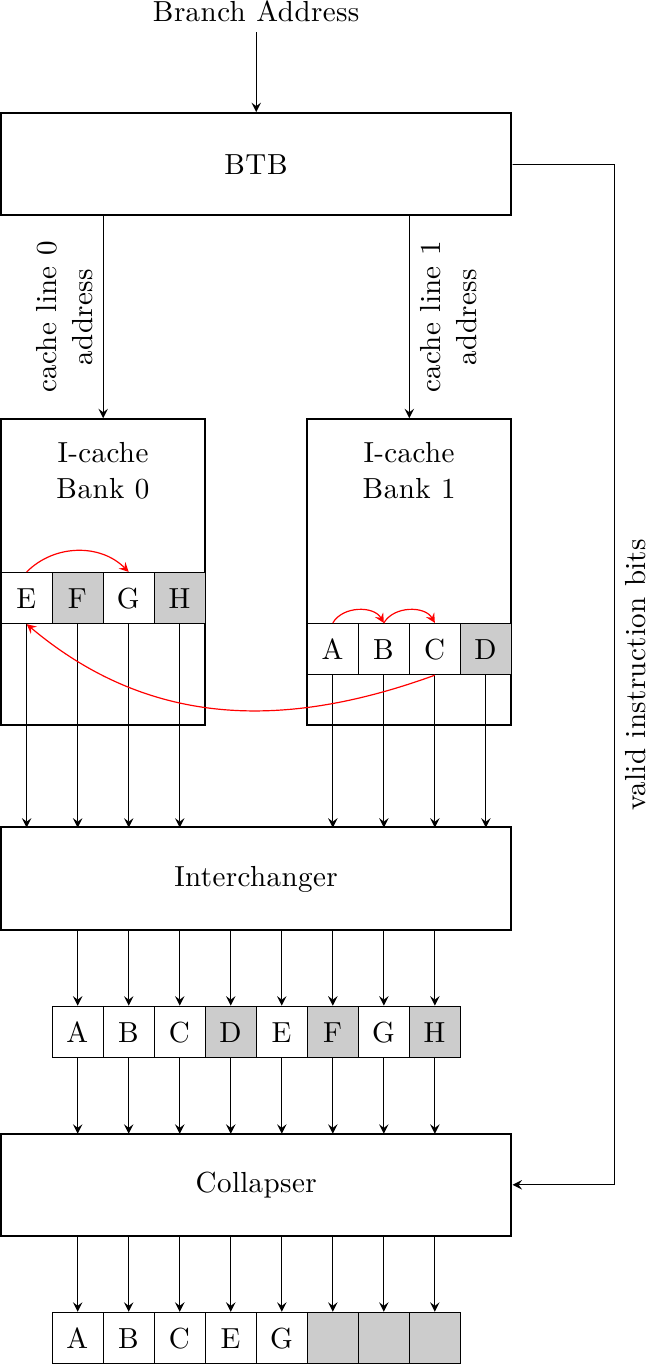
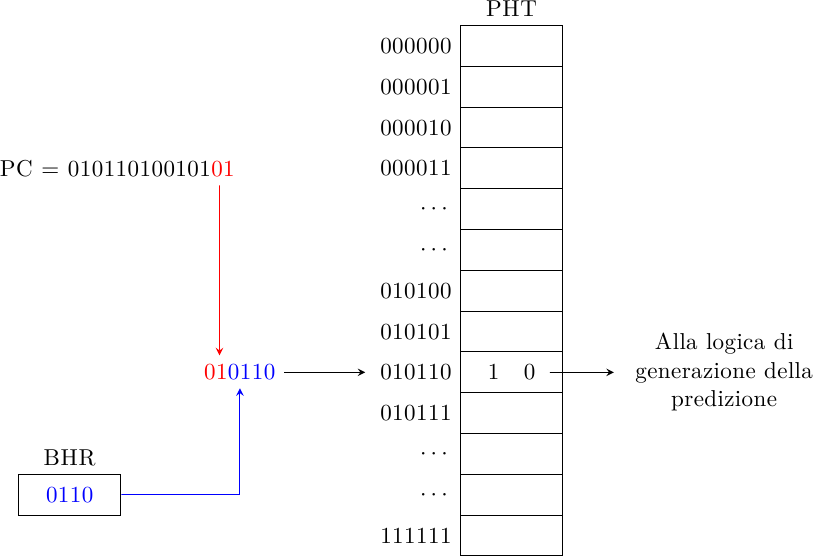
Branch prediction (parte sesta): High-bandwidth fetch
In tutta la discussione sui meccanismi di branch prediction (e siamo ormai alla sesta puntata!)…
-
Pleg
- Processori & Design
- 6 Ottobre 2011
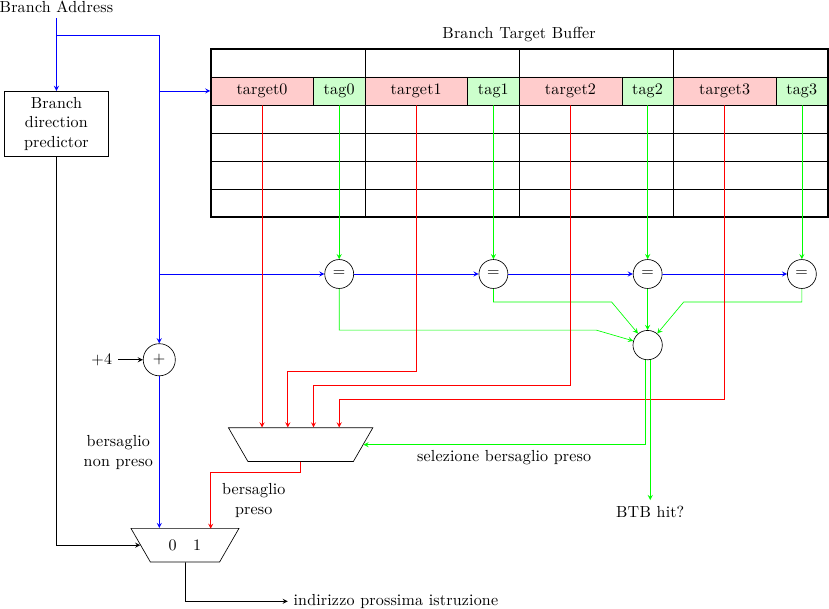
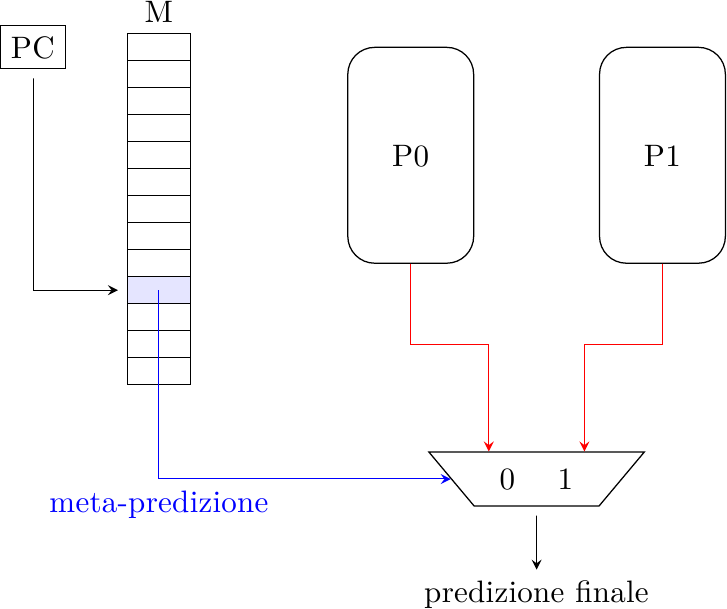
Branch prediction (parte quinta): Predizione del bersaglio
Negli scorsi articoli abbiamo visto alcune tecniche utilizzate dai processori moderni per predire la direzione…
-
Pleg
- Processori & Design
- 29 Giugno 2011
Branch prediction (parte quarta): Predittori ibridi
Nei precedenti due articoli (qui e qui) ho brevemente descritto alcuni schemi di branch prediction,…

-
Pleg
- Processori & Design
- 1 Giugno 2011
Intel come GlobalFoundries: una strada tutta da scoprire
Qualche giorno fa è comparsa su Reuters una strana e intrigante notizia a proposito di…
-
Pleg
- Processori & Design
- 14 Aprile 2011
Branch prediction (parte terza): Predittori piu’ complessi
Nella seconda parte di questa rassegna sui branch predictor ho illustrato i fondamentali e gli…

-
Pleg
- Grafica & Silicio
- 24 Febbraio 2011
Kepler, Maxwell, Denver, Tegra: dove va NVidia?
In una luminosa mattina californiana del novembre 2010, Jensen Huang, fondatore, presidente e CEO di…
In Appunti Digitali cerchiamo di esprimere punti di vista informati su questioni che conosciamo, materie che pratichiamo professionalmente o passioni seguite a lungo e con metodo. Nei limiti del poco tempo che possiamo dedicare alla scrittura di articoli, speriamo di aiutarvi a costruirvi un’opinione su materie complesse, informarvi e se possibile divertirvi. I conti del server li paghiamo di tasca nostra e ci riserviamo perciò di moderare i commenti a nostra discrezione.







