Nella seconda parte di questa rassegna sui branch predictor ho illustrato i fondamentali e gli schemi di base, che pur nella loro semplicità possono ottenere prestazioni relativamente elevate (anche superiori al 90%). Tuttavia i processori in generale, e quelli superscalari in particolare, possono ottenere grossi benefici da predittori ancora più precisi: ogni aumento di precisione può far sia aumentare le prestazioni (perchè si può estrarre parallelismo tra istruzioni in più blocchi base diversi) che ridurre il consumo energetico (perchè si eseguono meno istruzioni nel ramo sbagliato).
La letteratura in merito è sterminata e la ricerca nel campo continua, proprio perchè l’argomento è così importante per costruire processori ad alte prestazioni. In questa terza parte mostrerò alcune tecniche avanzate che permettono di sfruttare certe regolarità che sfuggono (o non vengono sfruttate in modo efficiente) dai predittori visti la volta scorsa, senza scendere molto in dettaglio in ognuno (sia perchè non è il mio campo, sia perchè a voler scendere in dettaglio seriverebbero qualche decina di articoli dedicati!)
Gli esempi sono presi da Shen, Lipasti, “Modern processor design – Fundamental of superscalar processors”, uno dei testi di riferimento fondamentali per i Computer Architect.
Gshare Predictor
Il predittore gshare è una variante del predittore basato sulla storia globale del salto (Global History 2-Level Predictor) visto nello scorso articolo. Questo predittore ha avuto un grande successo, essendo stato utilizzato in una forma o nell’altra in processori progettati da Alpha, IBM, Intel e AMD (cioè più o meno tutti!).
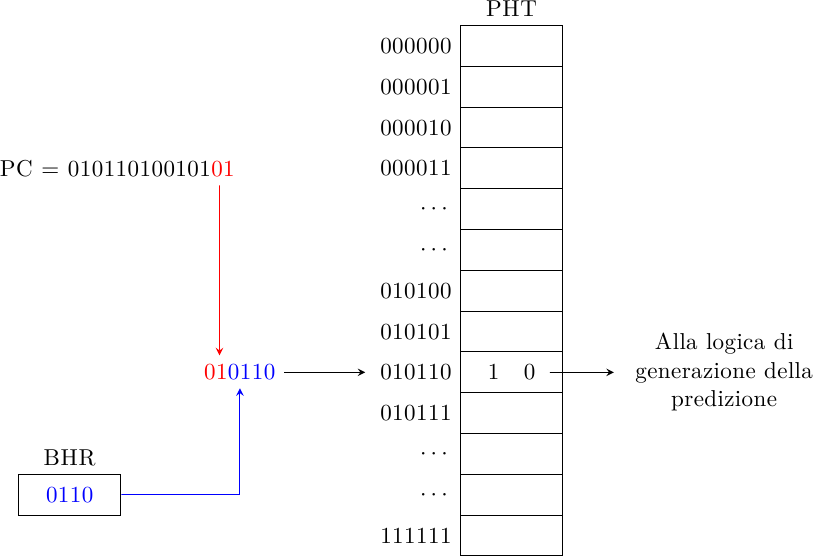
Il Global History 2-Level Predictor contiene una tabella di macchine a stati che generano la predizione di salto (la Pattern History Table) che viene indicizzata tramite una concatenazione della storia globale del salto (BHR) con parte dell’indirizzo del salto stesso:
Con l’aumento della frequenza di funzionamento dei processori si ha a disposizione sempre meno tempo per generare la predizione, che va generata il più in fretta possibile. Idealmente vorremmo generare una predizione ogni ciclo di clock con una latenza di un ciclo di clock: per un processore che gira a 3-4 GHz significa accedere al PC e al BHR, concatenarli, usare il risultato per accedere alla PHT, estrarre il valore dalla PHT e “manovrare” i MUX nella direzione prevista… in un paio di centinaia di picosecondi! C’è ben poco tempo da scialare!
Dato che la PHT è il pezzo di memoria più grosso del predittore, per farla veloce è cruciale farla piccola (SRAM più piccole sono più veloci da accedere, sia perchè l’indirizzo da decodificare è composto da meno bit, sia perchè le linee di interconnessione all’interno della memoria sono più corte). Ma una PHT più piccola ha meno informazione sulla storia dei salti (che porta a predizioni meno precise) e aumenta l’aliasing tra i salti, con possibile aumento di intereferenze distruttive e ulteriore perdita di precisione.
Possiamo ottenere prestazioni migliori mantenendo inalterato quasi tutto il design e cambiando solo la funzione di “fusione” del BHR col PC: invece di una concatenazione, possiamo fare uno hash dei due (di fatto uno XOR, che è molto veloce):
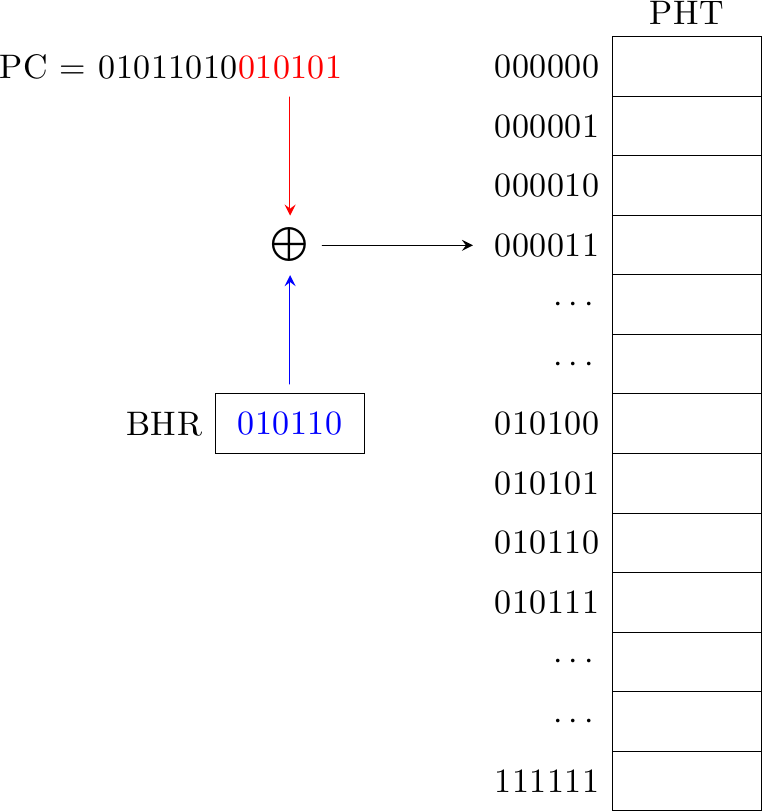
Uno hash ci permette di creare un indice più “significativo”, cioè che contiene più informazione, rispetto ad una concatenazione, perchè in ingresso alla funzione di “fusione” abbiamo più bit (ad esempio, avendo N bit di indice possiamo prendere N bit di PC e N bit di BHR, invece che X bit di PC e (N-X) bit di BHR). Questa semplice modifica aumenta la probabilità di avere meno interferenza e ci dà quindi più precisione.
Bi-Mode Predictor
La Pattern History Table vista finora è in sostanza una cache direct-mapped, ma senza tag per differenziare gli indirizzi (ed è per questo che è soggetta ad aliasing). Come per tutte le cache, i miss possono essere divisi in 3 categorie:
- compulsory (o cold) miss: la prima volta che incontriamo un salto non abbiamo storia su cui basarci e quindi non possiamo generare una predizione; questo per fortuna succede molto di rado, visto che in genere i programmi restano a lungo in una certa sezione di codice
- capacity aliasing: questo succede se la PHT è troppo piccola per il working set corrente, cioè la sezione di codice su cui stiamo lavorando ha più branch di quanti ce ne stanno nella PHT
- conflict aliasing: quello che si ha quando diverse combinazioni di Program Counter e BHR generano lo stesso indice
Per i cold miss l’unica cosa da fare è aggiungere degli hint da compilatore, in modo che la prima volta che un branch esegue la CPU ha già un valore più probabile della direzione che prenderà; questo però richiede il supporto dell’ISA. Per i capacity miss la soluzione è aumentare la dimensione della PHT, ma come visto prima aumentare la dimensione rende la PHT più lenta, e il risultato finale potrebbe essere un processore più lento invece che più veloce.
Per i conflict aliasing la soluzione standard nelle cache è aumentare l’associatività. Avere dei set richiede però di avere delle tag per distinguere i set: se anche avessimo solo 2 bit di tag, dato che le FSM nella PHT hanno in genere 2 bit significherebbe raddoppiare la dimensione della PHT! A questo punto sarebbe probabilmente più conveniente abbandonare le tag e semplicemente raddoppiare il numero di entry disponibili, per ridurre sia i problemi di capacity che di conflict.
Ma dato che stiamo parlando di branch predictor e non di cache normali, abbiamo a disposizione più spazio di manovra: quello che in effetti ci interessa non è diminuire l’aliasing, ma diminuire l’aliasing distruttivo! Se due branch vanno nella stessa direzione (entrambi presi o non presi) il fatto che mappino nella stessa entry nella PHT non modifica la precisione del predittore: questo è un caso di interferenza neutra (se non addirittura costruttiva: nel caso in cui i due salti si comportino allo stesso modo, possono contribuire entrambi al training dei bit di predizione, popolando le tabelle con dati validi più in fretta). Quello che ci interessa ridurre quindi è semplicemente l’interferenza distruttiva, cioè due salti che vanno in direzioni opposte e che mappano sulla stessa entry.
Possiamo sfruttare questa intuizione per costruire un oggetto del genere:
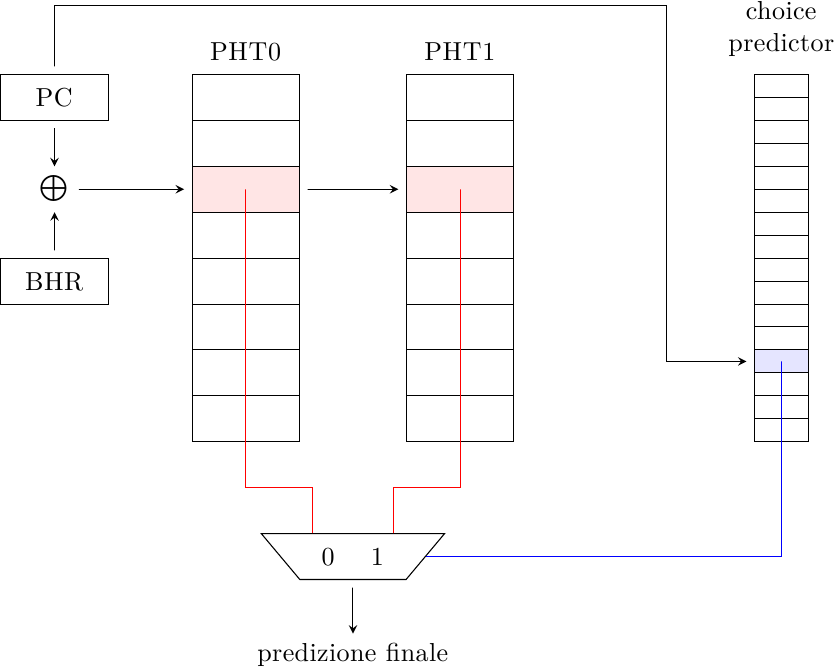
Invece di una singola tabella ne abbiamo due, PHT0 e PHT1, con stessa dimensione e indicizzate in modo gshare. In più abbiamo un choice predictor che decide quale delle due tabelle usare per generare la predizione finale, indicizzato invece usando solo il Program Counter. L’idea è quella di mettere tutti i salti a predominanza taken in una tabella e quelli a predominanza non-taken nell’altra, in modo da ridurre l’interferenza distruttiva: quando si verifica aliasing tra due branch è probabile che i due salti vadano nella stessa direzione, e quindi la predizione sarà comunque corretta.
Le regole di aggiornamento delle tabelle sono più complesse, e seguono una politica di aggiornamento parziale:
- la PHT selezionata viene sempre aggiornata con la vera direzione del salto, una volta che questo è stato eseguito; questo è il normale comportamento di una PHT
- la PHT non selezionata non viene aggiornata (in modo da eliminare l’interferenza distruttiva)
- il choice predictor è aggiornato con la vera direzione del salto a meno che la sua scelta fosse errata ma la predizione finale si sia rivelata comunque giusta (in questo caso è non c’è abbastanza informazione per capire qual è il modo migliore di aggiornare le tabelle, e quindi è meglio non aggiornare nulla)
Nonostante la quantità di memoria presente nel predittore sia triplicata il predittore non è molto più lento di prima, perchè entrambe le PHT e il choice predictor possono essere accedute in parallelo: l’unico ritardo addizionale è dato dalle interconnessioni più lunghe e dal MUX finale, ma è certamente inferiore a quello di una singla PHT di dimensioni triple.
Questo trucco permette di aumentare le prestazioni ad un costo contenuto ed è piuttosto popolare: è usata ad esempio nell’ultima architettura Intel, Sandy Bridge.
Gskewed Predictor
Invece di minimizzare l’impatto dell’aliasing raggruppando nella stessa PHT i salti che vanno (perlopiù) nella stessa direzione, il predittore gskewed cerca di minimizzare direttamente l’aliasing ma senza ricorrere a tag. L’idea è quella di avere predittori multipli con indici diversi e un voto a maggioranza:
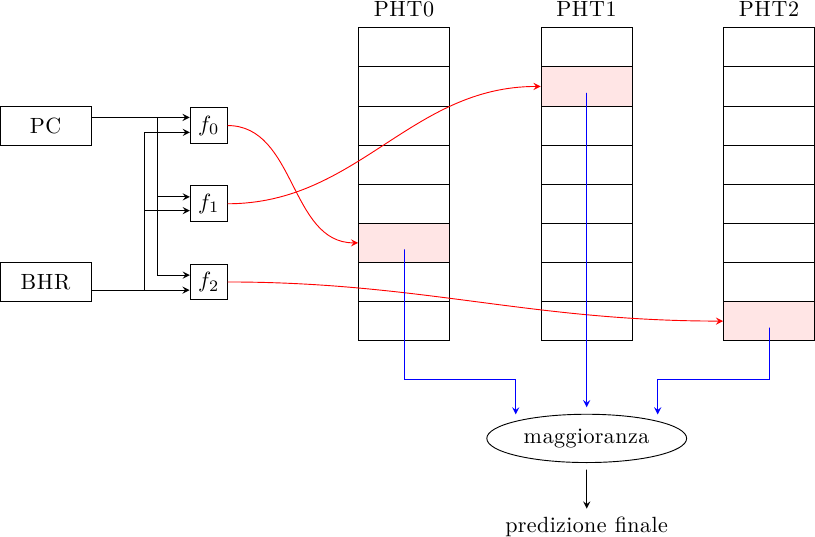
Ogni PHT è indicizzata tramite una funzione diversa; le funzioni sono costruite in modo tale che se due indirizzi generano aliasing in una PHT, essi non vanno in conflitto nelle altre PHT: nel caso di aliasing negativo, questo può essere ignorato dal voto a maggioranza se le altre due PHT generano la predizione corretta:
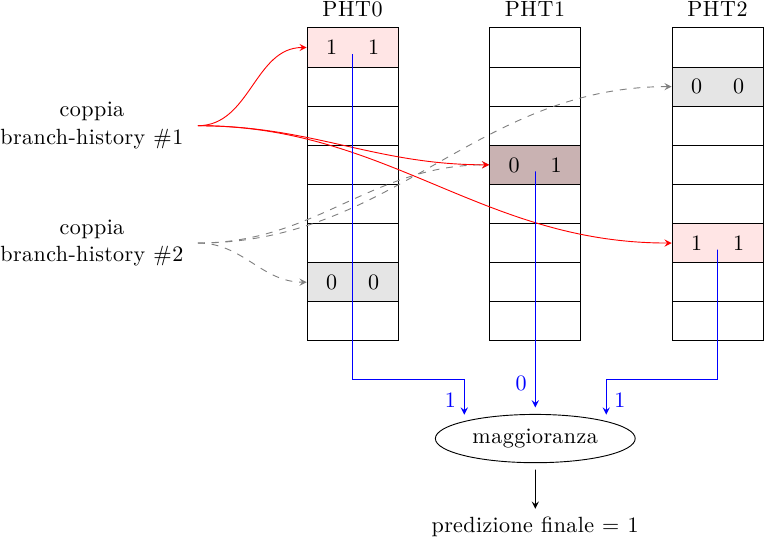
Ci sono due diversi modi di aggiornare le tabelle una volta che la direzione del salto è nota:
- aggiornamento totale: tutte le PHT vengono aggiornate col risultato del salto
- aggiornamento parziale: se uan PHT ha predetto sbagliato, ma la predizione finale era giusta, quella PHT non viene aggiornata; in questo modo si permette a quella PHT di fornire la predizione giusta ad un altro branch che mappa nella stessa entry
Esistono molte varianti di questo schema, alcune delle quali analizzate qui.
Agree Predictor
La maggior parte dei salti è fortemente polarizzata, il che significa che le macchine a stati presenti nelle entry delle PHT (in pratica dei contatori a saturazione) sono in genere o a 00 o a 11; in altre parole, i salti fortemente presi cercano sempre di aumentare il valore del contatore fino al valore massimo, mentre i salti fortemente non presi cercano di diminuirlo fino a 0. Quando due salti che vanno in direzioni opposte mappano sulla stessa entry, il rischio è che:
- uno dei due salti è più “forte” dell’altro (cioè eseguito più spesso) e quindi imporrà il valore al contatore: questo significa che lui otterrà la predizione giusta, mentre il salto “debole” otterrà la predizione sbagliata
- i due salti sono “forti uguali” (ad esempio se eseguono in alternanza, primo l’uno poi l’altro in un loop): questo caso può essere ancora peggio, perchè il contatore potrebbe continuare ad oscillare tra gli stati 01 e 10 col risultato che nessuno dei due salti ottiene la predizione corretta
L’agree predictor cerca di risolvere questo problema reinterpretando la PHT: invece di generare la predizione, la PHT dice se è d’accordo o meno con la predizione fornita da un biasing bit, che dice semplicemente se il salto è fortemente preso o non preso:
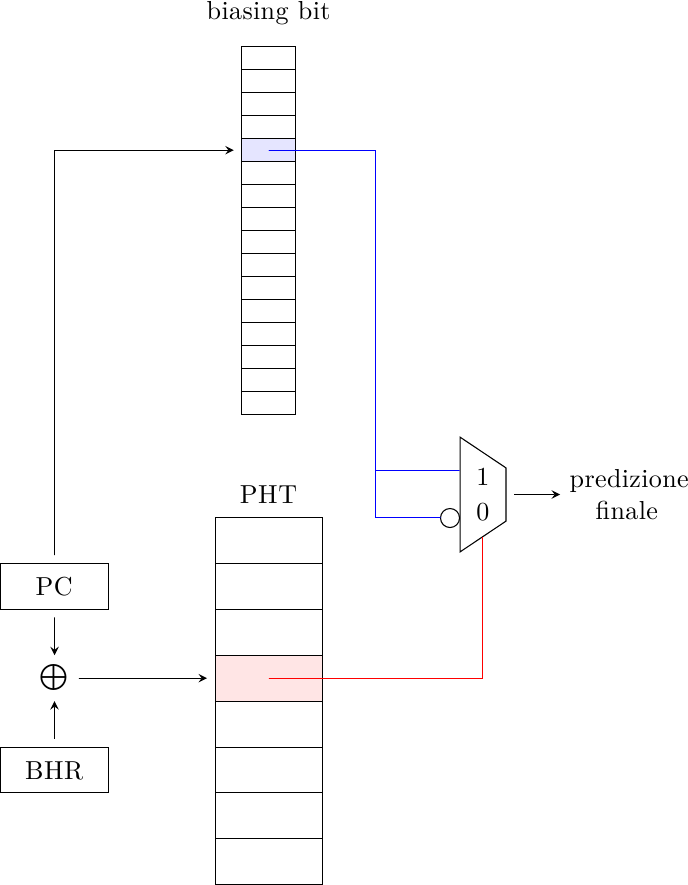
Il biasing bit dipende unicamente dal salto e può sia essere generato dinamicamente che essere fornito dal compilatore (magari assistito da un profiler). La PHT decide se bisogna prendere la direzione data dal biasing bit, oppure l’altra.
In questo modo due salti con direzione opposta possono mappare nella stessa entry della PHT e ottenere comunque la predizione corretta, se sono entrambi fortemente polarizzati. Dato che la maggior parte dei salti lo è, la probabilità di conflitto è più bassa rispetto al caso in cui la PHT fornisce direttamente la predizione di salto, portando a predizioni più accurate.
Questo schema è stato usato nel PA-RISC 8700, con un biasing bit determinato a compile-time.
YAGS predictor
Il Bi-Mode Predictor separa i salti in due tabelle (presi / non presi) per ridurre l’aliasing distruttivo, mentre l’Agree Predictor sfrutta il fatto che la maggior parte dei salti è fortemente polarizzata.
Il predittore Yet Another Global Scheme (c’è chi ha senso dell’umorismo :) usa entrambe queste idee: usa il choice predictor del predittore Bi-Mode sia per generare la predizione di salto “di default” (come il biasing bit dell’Agree predictor) sia per accedere a due tabelle (la Taken Cache e la Non-Taken Cache) che contengono i salti che NON sono in accordo con la predizione di default, in modo da usare lo spazio nelle tabelle in modo più efficiente. In altre parole, il choice predictor fornisce la “regola”, mentre le cache forniscono le “eccezioni alla regola”.
Per farlo, però, è necessario aggiungere alle tabelle delle tag (anche parziali) in modo da distinguere i salti tra loro: a parità di spazio, quindi, queste tabelle contengono molte meno entry rispetto alle PHT del Bi-Mode Predictor.
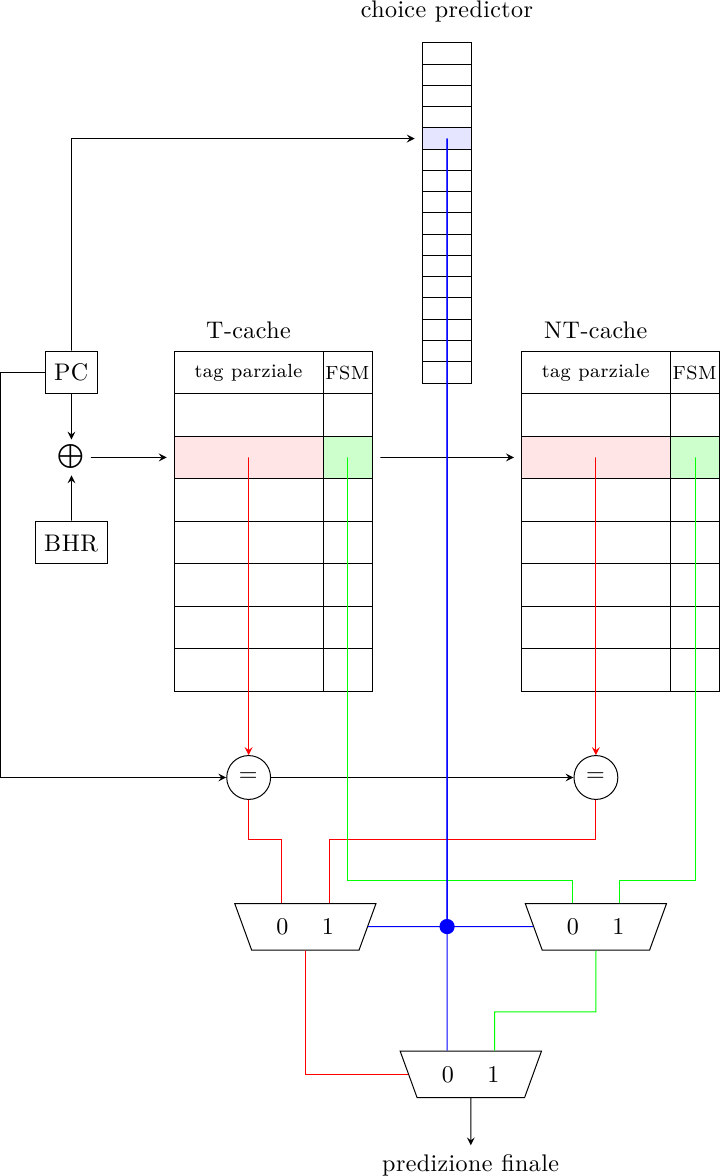
Il predittore funziona in questo modo: il choice predictor viene acceduto tramite il solo indirizzo di salto (perchè dipende dal salto, non dalla sua storia) e produce la predizione principale. Se questa PHT predice Taken, allora viene consultata la Non-Taken Cache, con un indice che dipende sia dal salto che dalla sua storia (in modo gshare). Se c’è un tag match, allora la predizione “di default” viene scartata e viene usata la predizione fornita dalla cache. Il sistema funziona in modo analogo per il caso opposto.
Una volta che il salto è eseguito, le tabelle vengono aggiornate con lo stesso schema parziale del Bi-Mode Predictor.
Branch Filtering
Anche questo predittore sfrutta il fatto che molti salti sono fortemente polarizzati costruendo un filtro che filtri via questi salti polarizzati dalla PHT, che viene quindi usata solo per predire i salti meno polarizzati, riducendo l’aliasing.
Per ogni salto c’è un contatore che tiene traccia di quante volte il salto è andato nella stessa direzione. Quando il contatore satura al massimo il salto smette di aggiornare la PHT e la sua predizione viene fornita dal contatore stesso. Se la direzione cambia, il contatore viene resettato e il processo di addestramento ricomincia.
Questo sistema è utile per filtrare tutti quei salti che non vengono mai presi in condizioni normali (come i check delle condizioni d’errore) o quasi mai presi (condizioni di terminazione di cicli molto lunghi), per lasciare spazio nella PHT a tutti gli altri salti dal comportamento più complesso.
Alloyed History Predictor
I predittori usano dei meccanismi di pattern-matching per identificare comportamenti ripetitivi nei salti (il cosiddetto “contesto”) in modo da applicarli in futuro nel caso lo stesso pattern dovesse ripresentarsi. Ma qual è il pattern migliore? Il salto dipende dalla storia globale o locale? O tutte e due? O dipende dal modo in cui hanno eseguito i salti vicino a lui? Quanti bit di storia bisogna mantenere?
I predittori visti finora cercano di ridurre il problema dell’aliasing negativo, ma usano tutti tecniche di global/local history o gshare per l’indirizzamento nella PHT. Altri predittori cercano di construire un contesto migliore accumulando più informazione di tipo diverso. Ad esempio, il predittore alloyed history utilizza sia la storia globale che la storia locale del salto (merged history) per generare l’indirizzo di accesso alla PHT:
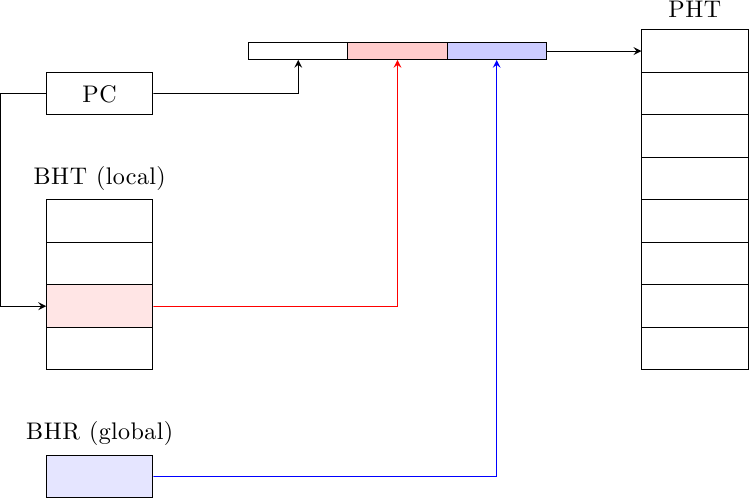
Il meccanismo a due livelli è uguale a quello dei global/local history 2-level predictors, ma usando entrambi i tipi di storia del salto allo stesso tempo (forniti dal BHR per la storia globale e dal BHT per la storia locale). Schemi simili posso essere applicati per costruire predittori mshare (merged history gshare) o mskewed (merged history gskewed).
Path History Predictor
Esistono casi in cui percorsi di codice diversi condividono un tratto della stessa sequenza di istruzioni, compresi i branch e la loro storia, prima di tornare a divergere. Consideriamo questo esempio:
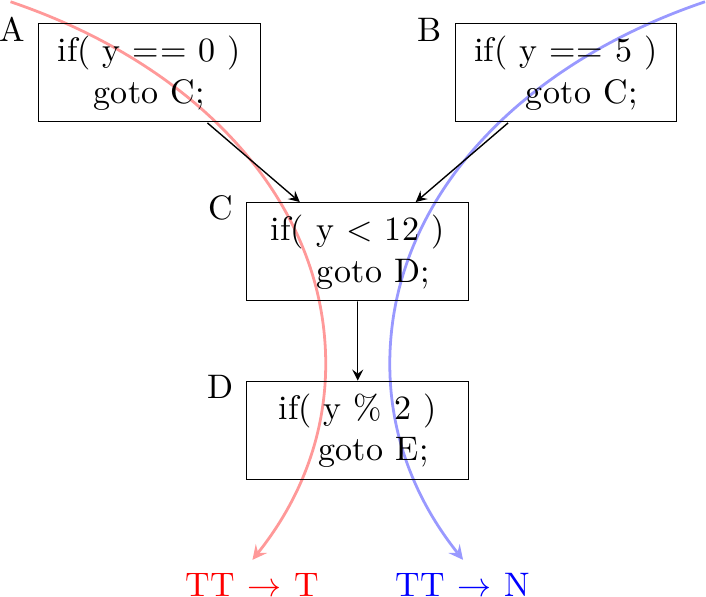
Il programma può raggiungere il salto nel blocco D sia attraverso il cammino ACD che attraverso il cammino BCD. A seconda del percorso seguito il salto valuterà in modo diverso, ma sia l’indirizzo che la storia di salto {taken, taken} sono gli stessi. Se i due percorsi mappano nella stessa entry nella PHT essi interferiranno distruttivamente, riducendo drasticamente l’efficienza di predizione del salto in D.
Per risolvere questo problema, il Path History Predictor mantiene nel suo Branch History Register (anzi, Path History Register) non il risultato degli ultimi n salti, ma k bit dell’indirizzo degli ultimi n salti, in modo da identificare il cammino seguito; questi vengono combinati con l’indirizzo del salto corrente per generare l’indice a cui accedere nella PHT e generare la predizione:
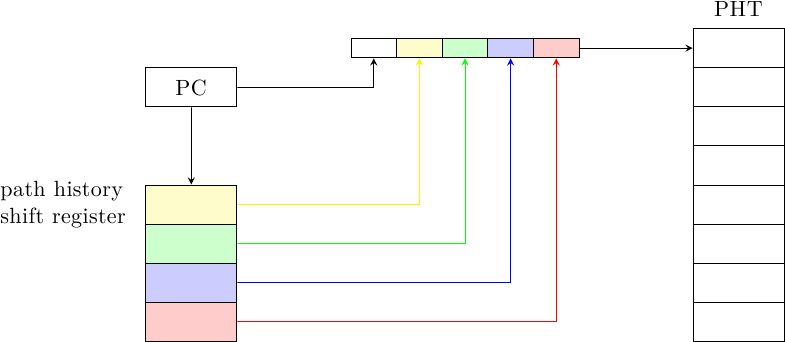
Ad ogni nuovo salto, i k bit del salto più vecchio escono dallo shift register e i k bit del salto più recente vengono accodati.
Se per generare l’indice vengono usati m bit dell’indirizzo del salto corrente, la PHT deve avere 2^(nk+m) celle: la memoria necessaria per la PHT cresce molto rapidamente coi valori di n, k e m. Per ridurre la dimensione della PHT, invece di usare la concatenazione possiamo usare un qualche tipo di hash (come per gshare) per comprimere il numero di bit e riportare la quantità di memoria usata a dimensioni accettabili.
Loop counting predictor
I loop sono una delle strutture di controllo più comuni e una buona parte di essi eseguono per lo stesso numero di iterazioni ogni volta che sono chiamati. Questo rende molti loop completamente prevedibili, eppure nessuno dei predittori visti finora fa un buon lavoro con essi. Il problema è che avendo a disposizione n bit di storia è possibile catturare solo loop che eseguono per n cicli o meno, e n deve essere piccolo altrimenti le dimensioni della PHT (che cresce come 2^n) diventano proibitive. Inoltre, il comportamento del loop è “spalmato” su molte entry nella PHT (fino ad n), che saranno soggette ad aliasing con altri branch, facendo perdere precisione nella predizione di qualcosa che è spesso molto regolare (e quindi predicibile al 100%).
Questo è vero a meno che non si usino quegli n bit per contare esplicitamente le iterazioni del loop: in questo caso, n bit possono contare fino a 2^n cicli; inoltre, se usiamo questo predittore per analizzare solo i loop e nient’altro, la probabilità di aliasing è molto ridotta. Un loop branch è definito come un branch che esegue per n volte in una direzione ed 1 volta nella direzione opposta, per poi ripetersi (assumendo che sia regolare). Questa struttura permette di catturarne il comportamento in modo efficiente:
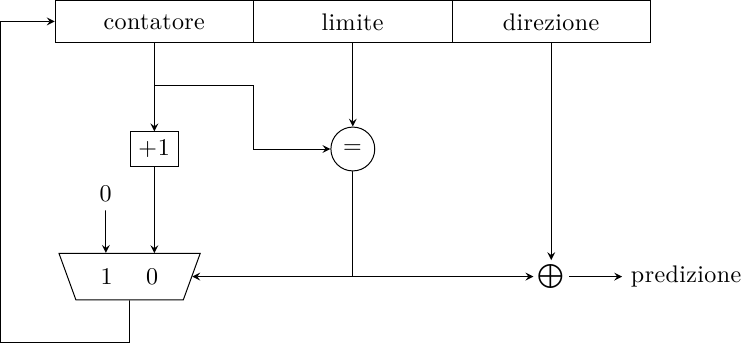
Il campo limite contiene il numero di iterazioni che il loop ha eseguito la volta precedente; se il loop è regolare (come ad esempio negli algoritmi di moltiplicazione tra matrici, o in algoritmi di grafica dove la stessa operazione viene eseguita 4 volte per ogni pixel per le componenti {R, G, B, A}, e infiniti altri casi) e il numero di iterazioni è inferiore a 2^n, questo predittore avrà una precisione del 100%: è capace di predire tutte le volte che il loop è preso e anche la condizione di uscita.
Una cosa curiosa da notare è che, usando questo predittore, i loop eseguono… due volte! Consideriamo questo esempio:
for( int i = 0; i < n; ++i ) { ... }
Il loop aumenta ad ogni iterazione la variabile i: l’operazione viene eseguita nello stadio di esecuzione in una delle ALU intere, interessa i registri architetturali, ed è ovviamente visibile al software. Contemporaneamente, il predittore sta eseguendo lo stesso ciclo, aumentando la sua copia shadow del contatore i, ma in testa alla pipeline (intorno allo stadio di fetch) in modo nascosto al software. In un certo senso stiamo spostando l’operazione sul contatore del loop dallo stadio di esecuzione allo stadio di fetch, in modo da ridurre la latenza con cui la condizione di controllo del loop diventa nota alla logica che deve accedere alla cache per prelevare le istruzioni successive.
Questo predittore ha fatto al sua comparsa nelle CPU col Pentium-M. Dal Core2 Intel ha introdotto il Loop Stream Detector (LSD per gli amici :) che fonde l’idea del Loop Counting Predictor con una cache di microistruzioni già decodificate (come fanno certi DSP) col doppio fine di aumentare le prestazioni e ridurre il consumo di energia, spegnendo gli stadi di fetch e decode quando il processore può essere alimentato con u-ops direttamente dal LSD.
Questo predittore funziona molto bene per loop regolari, ma molto male per branch generici. È utile se usato non da solo ma insieme ad altri predittori.
Conclusione
In questo articolo abbiamo visto alcune tecniche più sofisticate che vengono utilizzate in processori reali per costruire branch predictor molto accurati. Nel prossimo articolo illustrerò dei meccanismi usati per combinare queste tecniche per costruire predittori ibridi ancora più precisi.







