Per trent’anni, prima che il raggiungimento del power wall terminasse la “corsa ai GHz” e iniziasse la “corsa ai core”, il modo più semplice e gettonato per aumentare le prestazioni dei processori è stato l’aumento della frequenza operativa, raggiungibile tramite pipeline più profonde e processi produttivi più raffinati.
Aumentare il numero di stadi di pipeline ha un doppio impatto sul front-end del processore (fetch e branch prediction):
- da un lato, avere più stadi aumenta la branch misprediction, riducendo le prestazioni; questo rende necessario l’adozione di strategie di predizione più sofisticate per aumentare la precisione delle predizioni
- dall’altro, il tempo di accesso alla cache (almeno di primo livello) e il tempo necessario per generare le predizioni deve diminuire, che significa che le dimensioni delle cache e dei predittori deve diminuire; questo causa un aumento dei cache miss e un peggioramento dell’accuratezza delle predizioni
In questo settimo (e ultimo!) articolo sulla branch prediction vedremo un paio di tecniche per risolvere questi problemi.
Line & way predictor
Che cosa significa predire il bersaglio di salto? Significa forse predire l’indirizzo che viene generato dall’istruzione di salto? Credo che tutti noi risponderemmo “ovviamente sì, che altro?! Se il salto va all’indirizzo 0x12345678, il predittore deve generare il valore 0x12345678”.
Questo sicuramente funzionerebbe… ma potrebbe non essere la cosa migliore da fare. Innanzitutto, quell’indirizzo è in genere un indirizzo virtuale, che deve essere tradotto per ottenere l’indirizzo fisico con cui la cache è indicizzata; il processo per accedere alla cache sarebbe quindi:
- il predittore genera l’indirizzo virtuale
- si esegue la traduzione nell’indirizzo fisico, accedendo alla TLB
- si usa questo indirizzo per accedere alla cache
Ecco che per accedere alla cache istruzioni dobbiamo accedere prima ad un’altra cache! e il numero di cicli necessari ad prelevare la prossima istruzione cresce a dismisura, rendendo il front-end della pipeline molto inefficiente e abbattendo le prestazioni del processore.
Non solo, ma a pensarci bene quello che ci interessa è predire un’istruzione solo se questa si trova nel primo livello di cache. Se anche riuscissimo a predire con successo un’istruzione solo per scoprire che questa si trova in una pagina che al momento è in RAM e dobbiamo aspettare centinaia di cicli di clock per potervi accedere, la predizione è completamente inutile e potevamo semplicemente eseguire il salto e risparmiare l’energia spesa per fare la predizione.
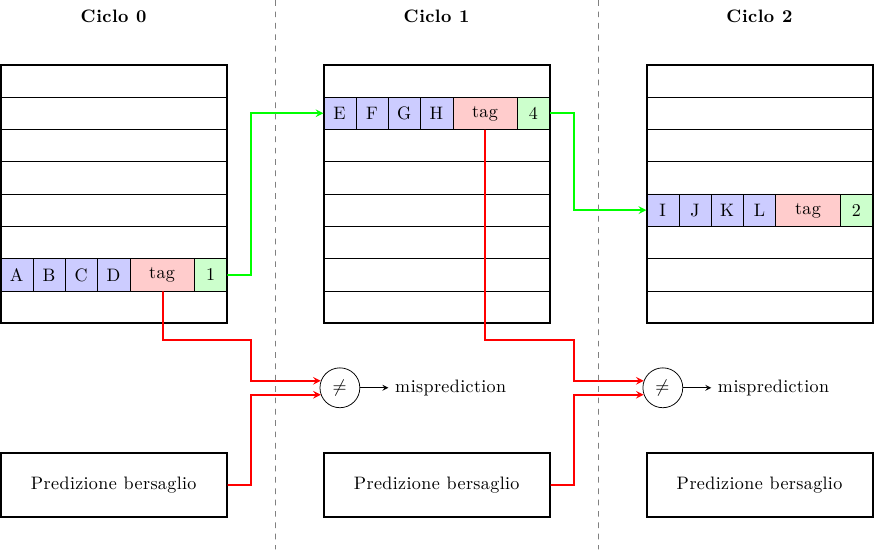
Queste due considerazioni ci suggeriscono che non è particolarmente importante predire l’indirizzo assoluto della prossima istruzione, bensì qual è la sua posizione nella cache L1. Quello che possiamo fare è quindi una cosa del genere:
dove ogni cache line ha, oltre ai dati, una tag e un puntatore alla prossima cache line, sempre all’interno della cache L1. In questo modo ad ogni accesso possiamo prelevare contemporaneamente i dati e la posizione della prossima linea di cache. A lato possiamo comunque avere un predittore più sofisticato (e lento) che predice anche lui il bersaglio del prossimo salto e controlla (ad esempio al ciclo successivo) che la linea predetta dalla cache stessa fosse quella giusta, controllando la tag.
In questo modo abbiamo costruito un sistema con multipli livelli di controllo e correzione:
- ogni cache line genera immediatamente una predizione alla prossima cache line
- un predittore più preciso e lento genera una predizione più accurata e controlla la predizione della cache
- l’esecuzione dell’istruzione di salto (che deve sempre e comunque essere portata a termine) funziona da “ultima linea di difesa”, controllando che tutti i meccanismi precedenti abbiano funzionato e assicurando la correttezza nell’esecuzione del programma
Nell’esempio mostrato la cache è direct-mapped, ma è possibile applicare lo stesso principio anche ad una cache set-associativa, cioè con più vie (ways). Queste cache hanno un miss-rate minore ma un tempo di accesso maggiore: invece di accedere ad una singola linea bisogna accedere a più linee e poi capire qual è quella giusta. Usando lo stesso meccanismo possiamo predire non solo la linea ma anche la via della prossima cache line; se la via è predetta correttamente possiamo accedere ad una cache set-associativa con la stessa latenza di una cache direct-mapped, altrimenti dovremo inserire una bolla nella pipeline e fare un altro accesso.
Override predictor
Come spiegato prima, esiste un compromesso tra la velocità a cui possiamo generare una predizione e la sua accuratezza: più il predittore è complesso più è preciso ma più cicli di clock servono per generare la predizione. Un predittore di tipo override combina due diversi predittori: uno lento ma preciso e uno veloce ma meno preciso. Il predittore veloce è in grado di generare una predizione in un ciclo di clock in modo da ridurre al minimo la latenza del front-end, mentre il predittore lento serve a validare le predizioni di quello veloce:
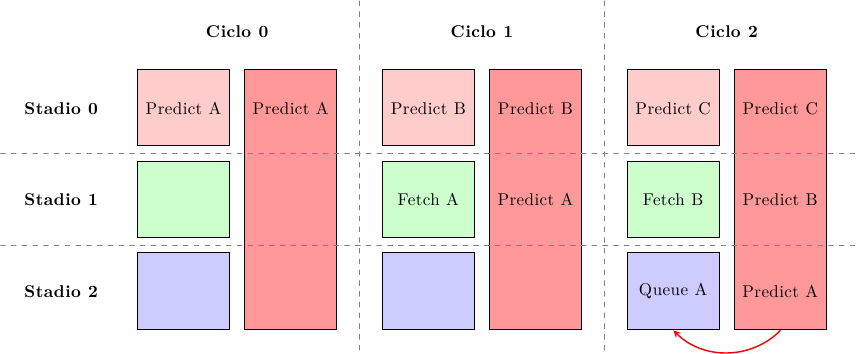
Al primo ciclo, il predittore veloce (a sinistra) fa una predizione iniziale che viene usata per accedere alla cache; nello stesso tempo il predittore lento comincia a generare la sua predizione, che sarà disponibile solo 2 cicli più tardi. Entrambi hanno un throughput di una predizione per ciclo di clock: quello veloce perchè un ciclo è tutto quello che gli serve per generare le sue predizioni, quello lento perchè è pipelinizzato.
Al terzo ciclo il predittore lento ha generato il suo valore e si procede a confrontarlo con quello del predittore veloce: se sono in accordo, la predizione veloce ha avuto successo e si è riusciti a procedere alla massima velocità; altrimenti le istruzioni fetchate vengono cancellate (cioè si inseriscono bolle nella pipeline) e si riprende a fare il fetch dall’istruzione predetta dal predittore lento:
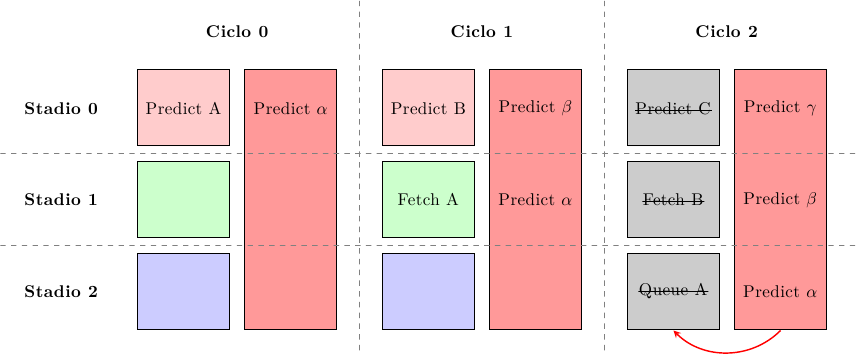
Ci sono quattro possibili combinazioni:
- i due predittori hanno predetto correttamente: nessuna bolla viene iniettata nella pipeline e il processore procede alla massima velocità
- il predittore veloce ha sbagliato ma quello lento ha predetto correttamente: alcune bolle vengono iniettate nella pipeline (override), pari alla differenza di stadi tra i due predittori (2 nell’esempio) ma è comunque un prezzo piccolo da pagare rispetto ad un intero flush della pipeline
- entrambi i predittori hanno sbagliato: il risultato è un pipeline flush, che è lo stesso prezzo da pagare per la misprediction di qualsiasi altro schema di predizione
- il predittore veloce ha predetto correttamente ma quello lento ha sbagliato: in questo caso la misprediction penalty è peggiore, perchè è somma del secondo e terzo caso (override + flush); questo però molto più raro del secondo caso e quindi il risultato netto è un aumento di prestazioni
Conclusioni
Con questo articolo ci siamo finalmente liberati di fetch e branch prediction; ora che siamo riusciti a prelevare le istruzioni dalla cache possiamo mandarle al decoder, che vedremo nel prossimo articolo.







