
Il titolo è, ovviamente, provocatorio, in quanto, come risulterà evidente, l’adozione di architetture multicore non è dettata da mere scelte modaiole e il loro utilizzo porta non pochi benefici. Sarebbe il caso, però, di indagare sui motivi che hanno spinto i progettisti ad abbandonare la strada della rincorsa alle frequenze e delle architetture superpipelined per imboccare quella del multichip o del multicore.
In questo articolo, avevo fatto cenno ad alcuni dei problemi ai quali si va incontro nei processi di scaling e ad una parte dei limiti che si stanno incontrando con le attuali tecnologie. In quest’altro articolo, si era fatto cenno a come si sviluppa l’idea di architettura pipelined ma anche a quali possono essere i principali svantaggi a cui si va incontro nel momento in cui si esaspera il concetto di pipeline e si cerca di ridurre il più possibile la dimensione degli stadi, aumentandone il numero e la frequenza di funzionamento. Infine, in quest’altro articolo, erano state messe a confronto le varie architetture ed era stata fatta una breve disamina delle caratteristiche di alcune di esse.
Sintetizzando, la corsa alle frequenze nasce dall’esigenza di aumentare il parallelismo interno dei chip: la prima strada intrapresa a tal fine, è stata quella di frammentare gli stadi di una pipeline, aumentando il numero di blocchi in grado di eseguire la stessa istruzione. In figura, il confronto tra la pipeline del pentium III e quella del pentium 4 willamette:
Come si vede nello schema, la pipeline del P4 ha il doppio degli stadi di quella del PIII e gli stadi sono di dimensioni notevolmente inferiori. La riduzione delle dimensioni degli stadi ha come conseguenze la frammentazione delle istruzioni e la riduzione del ciclo della singola istruzione. Nelle due immagini successive, sono poste a confronto un’architettura di tipo pipelined ed una di tipo superpipelined.
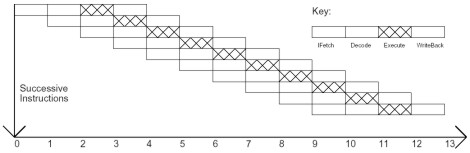
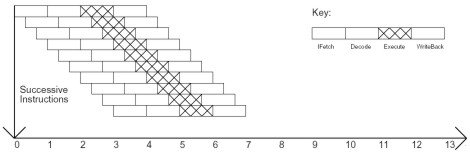
Come si può vedere, nel secondo caso la durata del ciclo relativo alla singola istruzione è decisamente più breve e nello stesso intervallo di tempo necessario a inizializzare una istruzione in un’architettura di tipo pipelined, si ha la possibilità di inizializzarne più di una (3 nell’esempio) in un’architettura superpipelined.
Con l’avvento del core Prescott, gli stadi furono portati a 31, raggiungendo il massimo per l’architettura netburst.
Questo tipo di soluzione comporta una serie di problemi, gran parte dei quali elencati negli articoli linkati in precedenza. In particolare, introduce delle criticità sui dati, con stalli più frequenti, sul controllo, con un maggior numero di stadi su cui annullare l’esecuzione, sulla gestione della dissipazione termica e della potenza richiesta. Nella successiva figura, è riportato l’andamento del rapporto tra frequenza e potenza dissipata, per una cpu della serie opteron64, per variazioni di frequenza con step pari a 200 MHz
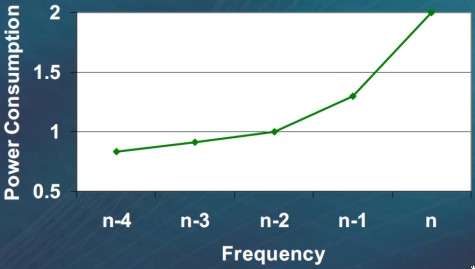
Come si vede, è sufficiente una diminuzione di 400 MHz di frequenza sul core per avere un quasi dimezzamento della potenza dissipata.
Da tener presente che ad ogni aumento di circa l’1% di performance, corrisponde un incremento pari a circa il 2-3% di potenza da dissipare e che, mediamente, la potenza di leakage subisce un incremento del 500% tra due scaling di tipo full node.
Queste considerazioni portano al risultato che un Athlon fx62 (2800 MHz), a parità di processo produttivo, dissipa circa il doppio della potenza del singolo core di un Athlon X2 4800+ (2400 MHz) con prestazioni complessive mediamente inferiori del 20%.
Interessante, per terminare con le considerazioni sul rapporto tra performance per watt, dare un’occhiata a questo grafico (fonte AMD) sul suddetto rapporto relativamente a single, dual e quad core
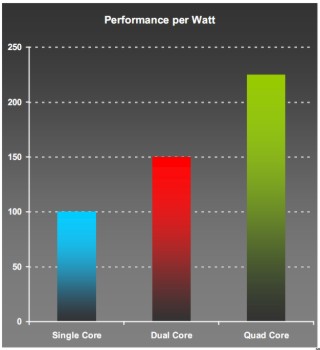
Dalle considerazioni sin qui fatte e dai grafici mostrati, risulta evidente come quella del multicore sia una scelta dettata, tra le altre motivazioni, dal tentativo di ovviare all’inconveniente del continuo aumento delle frequenze con relativa impennata delle potenze e conseguente insorgere di problemi legati a fenomeni parassiti indotti da temperature e correnti in gioco. La costante ricerca del parallelismo spinge, dunque, a migrare dalle architetture superpipelined a quelle di tipo superscalare, VLIW o SMT, che avessero la capacità di inizializzare più istruzioni o di avviare più thread in parallelo.
Nel campo delle GPU, abbiamo visto che l’evoluzione ha subito condotto verso architetture di tipo SIMD; per le CPU, invece, le cose sono andate in maniera differente, in quanto un’architettura SIMD non è ottimale per un impiego di tipo general purpose, in cui, al parallelismo dei dati si privilegia quello delle istruzioni.
Un’architettura MIMD di tipo single core risulterebbe estremamente complessa a livello progettuale e comporterebbe linee di trasmissione eccessivamente lunghe. Al contrario, la scelta di dividere una singola unità in tante unità più piccole, permette di semplificare notevolmente il layout del chip, di ridurre drasticamente la lunghezza delle linee di trasmissione e di spostare la complessità dal progetto singolo core a quello del sistema di comunicazione e di bilanciamento dei carichi tra i vari core. Infine, nel complesso, anche nelle applicazioni che richiedono parallelismo dei dati, un’architettura MIMD di tipo multicore risulta, complessivamente, più efficiente di una superscalare o di una SMT di tipo single core, come mostra il grafico seguente:
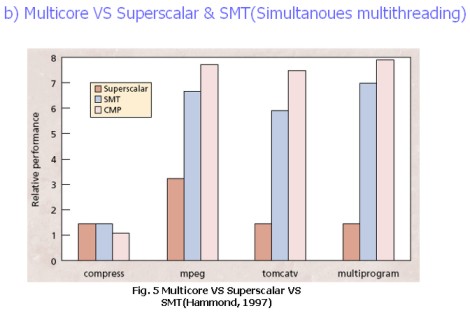
Quindi, la scelta del multicore è dettata da questioni di carattere “energetico”, da una maggiore efficienza assoluta e relativa, qualora si faccia una comparazione delle performance per watt, e dalla necessità di semplificare la fase di progettazione e di testing di chip che stanno diventando sempre più complessi.
I vantaggi delle architetture multicore, però, non si esauriscono qui: sempre sul piano energetico, avendo a disposizione più core indipendenti risulta più semplice decidere di spegnere parte del processore non utilizzato da quella particolare applicazione. Spegnere uno o più core è più facile che fare la stessa cosa con i circuiti interni di un chip ricorrendo a meccanismi di clock gating.
Infine, finora abbiamo considerato l’ipotesi di core di tipo simmetrico, ma un’architettura multicore può anche essere pensata con core asimmetrici, ognuno dei quali dedicato ad un particolare compito. In tal caso,i vantaggi, sia dal punto di vista delle prestazioni che dell’efficienza energetica, possono addirittura aumentare.
Infine una breve considerazione su multicore vs multichip; tra le due, il vero vantaggio della prima è, ancora una volta relativo al risparmio energetico: ormai, circa il 35-40% della potenza dissipata da un chip, è impiegata per le operazioni di I/O ed avere un singolo processore con un unico circuito di I/O, permette di avere vantaggi non indifferenti dal punto di vista del risparmio.
Ora che abbiamo visto il motivo che sta alla base della scelta delle architetture multicore, vediamo brevemente cosa è opportuno integrare e cosa è meglio lasciare fuori.
L’integrazione del memory controller, permette di ridurre le latenze relative agli accessi alla memoria e riduce la necessità di avere cache di grandi dimensioni. Abbinato al MC, conviene integrare un ring o un crossbar switch che permetta la connessione dei vari core e un qualsiasi link a dispositivi ad elevato transfer rate (come il canale dedicato alle comunicazioni tra due GPU, oppure bus come l’hyperstransport di AMD, ad esempio).
Il prossimo passo sarà quello di integrare funzioni grafiche o, per meglio dire un intero core grafico, creando, di fatto, una soluzione multicore di tipo asimmetrico. Quindi, quello che conviene integrare è tutto ciò che necessità di elevati valori di transfer rate (elementi atti a gestire e permettere la comunicazione con la ram con gli altri core e con un eventuale chip grafico), mentre è opportuno lasciar fuori tutto il resto, per evitare di intasare inutilmente i canali di comunicazione interni al chip.
Ovviamente, anche le architetture multicore presentano delle criticità tra cui, ad esempio, il northbridge che può costituire un collo di bottiglia se non si bilanciano in maniera corretta il numero di core con il numero e le dimensioni delle cache interne al chip e se non si programma opportunamente il MC. Questo perché la ram è il canale di I/O sono due degli elementi contesi tra tutti i possibili utilizzatori, ovvero i core del processore e l’accesso ad essi deve essere gestito in maniera tale da evitare o minimizzare ogni eventuale “ingorgo” che comporti tempi lunghi di attesa.
Una delle strade che si percorrono per ridurre l’impatto delle latenze di determinate operazioni è quella del multithreading. In effetti, prima ho presentato le architetture multicore e quelle SMT come se fossero concorrenti: di fatto non è così ed è sempre più frequente assistere alla presentazione di architetture multicore e multithreaded.
Un altro dei limiti delle architetture multicore è che, per risultare veramente efficienti in tutti i campi, hanno bisogno del supporto del sistema operativo e del software che devono elaborare. E questo vale tanto più per le architetture in cui il bilanciamento dei carichi di lavoro non avviene in hardware.
Oggi abbiamo visto, principalmente, perché si è scelto di battere la strada del multicore e se ne sono visti, soprattutto, i vantaggi mentre si è fatto solo qualche cenno alle problematiche connesse alla progettazione ed alla realizzazione di un chip multicore. In futuro torneremo su questi aspetti molti dei quali sono comuni anche alle architetture dei chip grafici che rappresentano l’argomento principale di questa rubrica.
Se nel campo delle CPU la scelta del multicore appare inequivocabile, in ambito GPU pare esserci una maggiore ambiguità; se è possibile, ad esempio, definire larrabee un chip multicore o, per meglio dire, per usare la definizione di Intel, “manycore”, si può dire lo stesso, ad esempio, di GT200 o di RV770?
Abbiamo visto che le cpu multicore presentano architetture MIMD con memoria cache a più livelli, in parte dedicata ed in parte condivisa. Anche i chip grafici sopra elencati presentano blocchi di unità di calcolo gestiti in modalità MIMD e, quindi, almeno in parte, l’analogia è possibile.
Certo, non si tratta di core fisicamente distinti, non sono gestiti singolarmente ma in blocco da un unico thread processor principale e neppure si può pensare di ricavarne un’architettura di tipo asimmetrico. Si potrebbero, con buona approssimazione, considerare delle architetture “ibride” con caratteristiche tipiche, vantaggi e problemi connessi alle architetture multicore di cui condividono, almeno in parte, l’impostazione.







