
Dopo aver passato brevemente in rassegna le tipologie di memorie presenti al’interno di un chip, questa settimana inizieremo ad entrare nel dettaglio di cosa succede quando viene data un’istruzione ad un processore. Iniziamo col dire che lo schema di un’istruzione elementare (ad esempio RISC) è del tipo: fetch, decode, execute, memory write back. In pratica, l’istruzione viene letta, interpretata, eseguita e, in fine, il suo risultato finisce in memoria.
Questo semplificando al massimo. Scendendo più nel dettaglio, scopriamo che, ad esempio, tra uno stadio e l’altro ci sono dei particolari tipi di memoria, registri, buffer o cache. Ad esempio, esiste un particolare registro detto Program Counter (PC) che contiene l’indirizzo all’istruzione successiva a quella che si sta eseguendo.
C’è, poi, un altro registro “speciale” detto Instruction Register (IR), che contiene l’istruzione in esecuzione. Un terzo registro, il Registro di Stato, contiene informazioni sullo stato corrente dell’esecuzione e segnala eventuali errori. Ci sono poi altri due registri speciali che contengono rispettivamente gli indirizzi della cella di memoria da cui leggere o scrivere un dato e il dato da leggere o scrivere.
Quando si assegna un’istruzione ad una unità di calcolo, quindi, che sia un processore o una alu, innanzitutto si deve fornire l’indirizzo della prima delle celle di memoria da cui prelevare i dati; quindi l’istruzione è caricata nel program counter da cui è inoltrata la richiesta di accesso alla ram (DMA) gestito dal memory controller e, successivamente, l’istruzione così ottenuta è inviata nell’instruction register; qui è decodificata e mandata in esecuzione.
A questo punto, i dati necessari alla sua esecuzione sono caricati nei registi della alu e inizia l’esecuzione vera e propria. Durante l’esecuzione, viene continuamente aggiornato il registro di stato che trasmette informazioni circa lo stato dell’esecuzione e permette di trarre informazioni sulla nuova istruzione da caricare nel program counter.
Appare chiara, quindi, l’importanza della velocità con cui tutte queste operazioni sono eseguite e del perchè sia così importante avere memorie con latenze molto ridotte che si interfaccino con le unità di calcolo o con i circuiti di controllo e trasmissione del chip. Il boom del numero di registri fatto segnare in questi anni è il miglior indice di questa necessità, in quanto i registri sono il tipo di memoria a più bassa latenza (il tempo d’accesso ad un registro interno varia tipicamente tra 1 e 5 cicli di clock).
Ovviamente la schematizzazione fatta è massima, in quanto il discorso è riferito ad una sola alu e ad una sola istruzione. La cosa è molto più complessa ed articolata, poichè all’interno di un chip pesantemente multithreaded, come una gpu, sono caricate svariate migliaia di istruzioni e dati che circolano contemporaneamente all’internod elle pipeline; ciò comporta che non si ha un singolo registro di tipo PC o IR, ad esempio, ma interi buffer di registri dello stesso tipo, con la possibilità, per i chip che fanno uso di controllo di flusso di tipo dinamico, di riordinare le istruzioni in base al feedback ricevuto dai registri di stato.
Il memory controller, a sua volta, gestirà in modalità Out of Order le richieste di accesso in memoria e, di conseguenza, è dotato anche lui di buffer in cui immagazzinare le suddette richieste e decidere in che ordine soddisfarle.
L?approccio sin qui descritto, però, non è l’unico. E’ stato fatto l’esempio di un’architettura che lavora su istruzioni elementari e le cui alu non hanno la possibilità di accedere direttamente alla memoria centrale. Questo approccio è tipico delle cosiddette architetture RISC (Reduced Instruction Set Computer).
Differente il caso, ad esempio, di un’architettura di tipo CISC (Complex Instruction Set Computer); quest’ultima prevede l’utilizzo di istruzioni complesse con la unità di calcolo che possono accedere direttamente alla memoria centrale per leggere e scrivere i dati. I vantaggi di questo tipo di approccio sono maggior facilità di programmazione e maggior numero di istruzioni eseguite per ciclo da ogni singola alu. Questo perchè ad ogni istruzione di tipo CISC corrispondono più istruzioni elementari di tipo RISC.
Ciò significa, come è facilmente comprensibile, che a livello circuitale un’alu di un processore CISC è enormemente più complessa di un’alu RISC. Quindi la maggior semplicità di programmazione si ripercuote in una maggior cpmplessità circuitale. Di fatto, l’approccio di tipo RISC nasce dal tentativo di semplificare le architetture dei chip attraverso un modello che prevedesse lo spezzettamento delle macro istruzioni RISC in tante istruzioni elementari.
Questo si traduceva anche nello spezzettamento delle unità preposte alle operazioni di lettura, decodifica e esecuzione delle istruzioni, in tante unità “elementari”, disposte serialmente, che svolgessero gli stessi compiti. Nasce così il concetto di pipeline. Il vantaggio di questo approccio è la minor complessità, sia a livello progettuale che realizzativo, della singola unità e la possibilità di raggiungere un duplice obiettivo: aumentare la potenza di calcolo semplicemente replicando un blocco di stadi elementari in serie o in parallelo; aumentare le frequenze di funzionamento del chip.
Questo perchè la velocità di elaborazione del chip è condizionata dal suo stadio più lento, ossia da quello che impiega più tempo a tarminare il suo task. E’ ovvio che più uno stadio è complesso, ossia più operazioni devono essere compiute per eseguire una singola istruzione, più questo farà da freno alla possibilità di incrementare la frequenza di funzionamento del chip; se si riesce a ridurne le dimensioni è possibile aumentarnela velocità di elaborazione.
Il modo per ottenere ciò è quello di scomporre la singola unità in unità sempre più piccole, fino a ridurle ad unità di tipo “elementari”. Nascono così le architetture pipelined, ossia formate da tanti blocchi che replicano gli stessi stadi, disposti in cascata. Con l’avvento del pipeline nasce anche la necessitàdi sincronizzare le operazini dei vari stadi. Proprio questo sincronismo finisce col costituire uno dei tre principalicolli i bottiglia a cui un’architettura di tipo pipelined va incontro. Vediamo un esempio pratico: supponiamo di avere una macro alu in grado di eseguire un “processo” che sia l’equivalente di 3 istruzioni elementari; per la prima e la terza sono necessari 10 ns, per la seconda 100.
Per l’esecuzione dell’intero processo saranno necessari 120 ns. Ora immaginiamo di scomporre l’alu in 3 alu più piccoile, ognune delle quali si occupi di una singola istruzione
Il primo ed il terzo stadio dovranno aspettare che il secondo completi la sua istruzione, per cui il tempo totale per terminare il processo sarà di 300 ns. Uno svantaggio notevole!!!!!!!!!!!!!!!!!!
Vediamo cosa accade se, però, i processi sono, ad esempio, 5. Nel caso della macro alu, il tempo impiegato sarà pari a 5 volte 120 ns, ovvero 600 ns. Con la pipeline, si verifica quanto riportato in figura
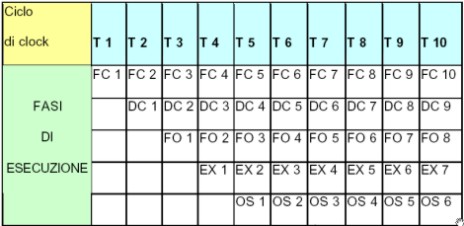
dove sono riportate le varie fasi dell’esecuzione per ogni songola istruzione (ad esempio FC1 sta per FETCH istruzione 1, DC per decode, ecc). Come si può vedere, l’istruzione n termina un solo ciclo dopo che è terminata l’istruzione n-1. Questo permette di ricavare la formula che fornisce il numero dei cicli macchina di un processore con un pipeline di k stadi che elabora n processi:
T(k) = k + (n – 1)
che tradotto in tempo d’esecuzione dà, nell’esempio riportato, un valore pari a [3+(5-1)]*100=700. Ovvero, con 5 porcessi il vabtaggio di un’architettura non pipelined si assottiglia. Ma si può fare di meglio. Scomponiamo lo stadio 2 in due stadi, ciascuno dei quali impiega 50 ns a portare a termine l’elaborazione.
![]()
La formula restituisce un valore pari a [4+(5-1)]*50= 400 ns. In tal modo, grazie ad un’architettura pipelined abbiamo guadagnato 200 ns. Ma si può fare ancora meglio
In tal modo, il tempo impiegato diventa [3+(5-1)]*50=350 ns.
Da questo esempio, emerge anche un’altra considerazione: che a parità di frequenza, un’architettura che presenta unità di calcolo in parallelo è più efficace di una che ha tutte le unità disposte in serie.
In effetti, avere una disposizione prevalentemente seriale delle unità, quando gli stadi diventano tanti (un caso emblematico l’architettura netburst), finisce col rivelarsi particolarmente inefficiente anche per il problema legato ai salti condizionali ed alla propagazione delle bolle. Un salto condizionale sbagliato, ad esempio,, con architettura tra i venti e i trenta stadi, può far sprecare qualche centinaio di cicli solo per le operazioni di svuotamento e riempimento del pipeline.
Terzo possibile problema delle architetture di tipo pipelined è legato alla necessità, in caso di istruzioni dipendenti, di aspettare il risultato delle elaborazioni dei precedenti stadi prima di poter procedere ai successivi calcoli.
Per ovviare a questi inconvenienti, i moderni microprocessori sono spesso dotati dicircuiti di branching dinamico molto sofisticati a cui sono affiancati anche algoritmi di static branching. Inoltre, tra uno stadio e l’altro, sono presenti registri e cache deputati a immagazzinare i risultati delle elaborazioni intermedie e a minimizzare l’impatto degli stadi più lenti sulla velocità di elaborazione della pipeline.
Le microarchitetture di cpu e gpu, di fatto, non sono riconducibili univocamente ad un preciso modello, in quanto presentano contaminazioni anche di altri modelli architetturali.
Dalle considerazioni fatte finora, emerge che le diverse architetture finora presentate differiscono per alcuni aspetti fondamentali, come ad esempio, le modalità di accesso alla memoria centrale o la tiopologia di alu e, di conseguenza, del tipo di istruzioni elaborate.
Questo ha un’inpluenza scontata sull’architettura dei chip; così vediamo che un’architettura di tipo RISC ha unità meno complesse, ma in numero assai maggiore, stadi di dimensioni ridotte, disposti in serie e/o in parallelo e un gran numero di registri e cache; il trasferimento dei dati e delle istruzioni avviene prevalentemente facendo uso dei registri e le sue unità non accedono direttamente alla ram. Un processore CISC ha unità più complesse, è più semplice da programmare, non ha necessità di avere un gran numero di registri e cache interni e ha unità che possono accedere direttamente alla ram.
Sia per le considerazioni, anche di carattere numerico, fatte in questo articolo, sia per quanto visto la scorsa settimana sulle latenze dei vari tipi di ram esterni e interni al chip, appare evidente come l’approccio RISC sia avvantaggiato sia dall’adozione dell’architettura a pipeline, sia dall’utilizzo di tipi di memoria embedded. Sono anche emerse considerazioni sul parallelismo di dati e istruzioni e sul loro rapporto.
Questo sarà elemento di un prossimo capitolo, in cui, oltre a sviluppare il discorso sulle architetture pipelined, introdurremo anche altri tipi di architetture che consentono l’esecuzione di più istruzioni per ciclo in generale, focalizzando sempre più l’attenzione sul calcolo di tipo parallelo. Arriveremo, così, a parlare di architetture superpipelined, superscalari, vliw, epic, smt, nonchè di sisd, misd, mimd e simd e faremo la conoscenza, un po’ più da vicino, con qualche architettura “reale”, per scoprire se e in che misura si è rimasti fedeli ai modelli teorici sin qui proposti.







