
The previous article completed the overview of NEx64T, so it is now possible to have quite a bit of information (including some statistics, reported in other articles in the series) that already provides a fairly clear idea of the features as well as potential of this new architecture.
One might ask now why spend so much time and resources on a project like this, beyond the sheer pleasure that a computer architecture enthusiast might have in designing one (which is not uncommon, in this field).
I think it is natural to fantasize about the little toy one has built with one’s own hands, but history and reality serve to bring us back down to earth. History teaches us that quite a few new architectures have been made, but reality shows us how difficult it really is to be able to enter a field/market like this, considering that very few of them have survived.
As “disruptive” as an architecture may seem, its nameplate features are not the only factor that matters and that are capable of stirring the waters, opening a breach in a fairly established as well as polarized reality (given the few representatives who currently share almost the entire slice, leaving crumbs to some of niches).
Thus, it is critical to understand first and foremost whether moving from gaming to something more serious is substantiated by more solid elements than dreams, and specifically to gather information on which points represent the added value, using the de facto standard architectures as benchmarks against which to compare.
Comparison with x86 and x64
In this case NEx64T does not start uphill since, proposing itself as a rewrite & evolution, it finds in x86 and x64 the main reference architectures, and with which several comparisons on very important aspects as well as metrics have already been made and illustrated in the previous articles of the series, which I briefly review in broad strokes:
- extreme simplicity of decoding instructions –> much smaller and simpler frontend (decoders) –> far fewer transistors needed –> lower power consumption;
- pipelines can be shorter, with benefits similar to the previous ones, compounded by performance benefits (lower penalty in the case of incorrectly predicted jumps);
- absence of several legacy instructions and reorganization of instructions –> simpler backend (execution units) –> far fewer transistors needed –> lower power consumption;
- better code density –> less access to the entire memory hierarchy –> better performance & lower power consumption. It is also possible to use less L1 instructions cache keeping the same performance –> fewer transistors –> lower power consumption;
- Fewer instructions executed –> better performance & lower power consumption;
- use of immediate values instead of memory referencing –> shorter instructions & better performance & lower power consumption.
In summary: it takes far fewer transistors to implement a processor with NEx64T ISA, resulting in savings on several aspects (including easier design & testing/debugging), including power consumption and better performance, which make this new architecture much more competitive than x86 and x64 in the various markets, also being able to attack others (embedded, low-power servers, embedded, server a basso consumo, real-time, mobile, IoT) on which the latter have had little impact so far.
In contrast, x86 and x64 can rely on a very large software library as well as enormous support, which are currently unmatched. NEx64T is not binary compatible with these two architectures, so it is obviously penalized in this respect.
It also has no support at the moment, so all the tools (assemblers, linkers, compilers, debuggers) have to be made. Being, however, totally compatible at the assembly code level, porting them from x86 / x64 does not require much effort on the part of experts working with these tools and architectures.
There is, then, to say that binary compatibility with x86 / x64 has become less and less important in recent years, thanks to tools and applications that have been made or ported for ISAs other than these, so those two old architectures are gradually losing this “added value” that has “held off” the competition for so long.
Comparison with ARM
One of these is another famous architecture, ARM, which actually groups together a number of ISAs that are also quite different from each other, but which share a common origin in the first architecture of this family, whose “strain” is now also commonly called ARM32.
ARM has made its fortune in the embedded and, especially, mobile markets, reaping success after success and coming to monopolize the latter, where it represents the only solution adopted by any device.
The strengths by which it fortified itself were represented by the small number of transistors used to implement the ARM32 cores, which was followed by the introduction of the Thumb extension first (with which it practically dominated in the area of code density) and Thumb-2 later (which, in addition to slightly improving code density, helped increase performance).
In particular, Thumb-2 has become an architecture in its own right, being completely independent of ARM32 (as opposed to Thumb, which is only an extension of ARM32 and is unable to replace it completely), so much so that there are even microcontrollers that implement only this ISA.
On the back of the enormous consensus as well as diffusion ARM has, calmly, worked on the 64-bit evolution of its families, presenting AArch64, which also represents a cut with ARM32, in that the ISA has been completely rethought by eliminating quite a bit of legacy that had accumulated over time, simplifying the architecture, which is now devoted to performance (code density is not good, although it defends itself quite well considering that it has only fixed-length instructions).
ARM has, therefore, a varied portfolio that allows it to cover different market segments, but it does so by carrying behind and offering four different architectures (thus with mutually incompatible binaries), although in recent years its sole focus has been AArch64, leaving the embedded & 32-bit market to Thumb-2.
The problem with AArch64, however, is that it does not offer good code density, as mentioned above, because this architecture is basically devoted to pure performance. In addition, there is no 64-bit version of Thumb-2 that could solve this problem, and that would not be feasible anyway, as the opcode table does not have enough room to fit all the necessary “compact” (16-bit) instructions.
The only possible solution, should ARM ever decide to move in this direction, would be to repeat exactly what was accomplished with Thumb and, therefore, to introduce a new ISA and a new execution mode to switch to by introducing special jump instructions in AArch64.
It would come out, however, the same as with ARM32: a junk that would limit performance (given the jumps to/from the new mode whenever it turned out to be necessary) and could not in any case achieve code density comparable even to that of Thumb, since AArch64 has as many as 32 registers available instead of ARM32’s 16, so there would not be enough space in the opcodes to perform the same, identical operations, consequently limiting the number of implementable instructions.
From this point of view NEx64T is much better off, since it has only one ISA (whatever its “declination” is: execution mode and/or variants), with preliminary results already showing very good code density vis-à-vis x86 and excellent vis-à-vis x64, while executing fewer instructions. So it certainly aspires to do better than ARM, once compilers, libraries, and various tools support it.
Comparison with RISC-V
Even RISC-V (one of the latest/newest architectures) has only one ISA (there are few differences in instructions depending on the execution “mode”), which was purposely designed, from the very beginning, with code density in mind and reserving as much as 75% of the entire opcode space only for “compact” (16-bit) instructions.
This may sound hilarious, but this is also its biggest flaw. Its code density, in fact, is good, but not the best around or even close to the best around, as is sadly pointed out in the following presentation given at the 2021 RISC-V conference:
of which I quote the relevant part:
When trying to compare the normal RISC-V code size density and code size performance against other commercial ISAs, we found that it’s considerably worse like 20-25% even with a compressed extension that it provides which is for the 16 bit, which is, so there is a compressed extension that provides a set of 16 bit instructions that should help with the code size but even with that the application code size are often much larger than ARM like that than alternative commercial processors like ARM.
Without going into too much detail, errors (I would say major ones) were made in the selection of instructions that are part of the C extension (for “compressed,” 16-bit opcodes), the specifications of which were consequently “frozen” once this was ratified and not amenable to further modification.
This, combined with the fact that “philosophical” choices (such as, for example, the imposition of a maximum of two registers to be read per instruction. Which heavily castrated those of load/store) that were made for this architecture regarding normal (fixed, 32-bit ones) and “basic” opcodes make it too simple (about 40 instructions for the ISA “core“), have decreed the situation in which it finds itself (not only for code density, but also for performance: more instructions are needed to execute for certain tasks).
To partially solve the problem, new extensions have been presented (and already ratified), called Zc (and another letter to follow, identifying the precise subset), which are the subject of the presentation whose video has been shared above.
The results look very promising, although the complexity level of some of the introduced extensions/instructions literally puts the more complicated CISC processors to shame, as can be seen, for example, in this part of the video:
In fact, and as is clear from the Zce specification document, these extensions were introduced specifically for the embedded market (which at the time was the main reference for RISC-V, which was quite penalized compared to the fierce competition):
The Zce extension is intended to be used for microcontrollers, and includes all relevant Zc
extensions.
And it could not be otherwise: some of those instructions are so complicated as to be totally incompatible with the above-mentioned design philosophy. So it is very difficult for them to be used in areas other than embedded, leaving the rest of the architecture in the same state that was stymied at the beginning of the presentation.
On the other hand, there was an absolute as well as urgent need to put a patch on the current situation (which was done with Zce for the embedded market, precisely), as is also clearly remarked in a paper by one of the main architects (Krste Asanovic) of this new architecture (here is the PDF with the slides), from which I extract some relevant parts:
- Contemporary instruction sets overflow 32 bits, and fixed 64b instructions
make code-size uncompetitive
- Add complex 32b instructions to mitigate 30-40% code size increase
- encoding new instructions that need substantially greater than 30-32b to encode (e.g., 32b immediates, longer calls, more source/destination register specifiers)
C.MOPSwhich reduce code size cost of new security features (checks add code at exit/entry to every function+ indirect branch targets)- 48b instructions that substantially improve code size (e.g., Just replacing 64b AUIPC-based sequences in Linux kernel with 48b instructions would save 3.6% code size over and above linker relaxation)
- Without new complex instructions, code-size penalty will hurt RISC-V adoption
I think the situation is pretty clear, as is remarked by the last sentence, which unequivocally shows that improving code density is one of the main factors for an architecture that wants to be competitive, and that, in particular, all of this necessarily comes through the adoption of complex instructions.
Stuff to make John Cocke roll over in his grave, in short, but so be it: there are people who are still convinced that RISC processors still exist, when all that is left of the foundations on which they were based is the constraint of only load/store instructions to access memory (so they are L/S architectures and not RISC!).
Compared to what has already been said for ARM, we can say that NEx64T already succeeds in solving all the problems that have plagued or are plaguing RISC-V: more complex instructions, more efficient from the point of view of code density, immediate values (up to 64 bits! ), “long” calls to subprograms, more selectable registers (especially masks for vectors), and much more are already available and usable without having to wrack our heads thinking about what new extensions to introduce to mitigate or solve the gripes that plague the latter. All packed into a coherent and well-defined opcode and instruction structure that does not need to add random opcodes to meet the above requirements.
Comparison with MIPS, PowerPC/POWER, SPARC
There are also other fairly famous architectures that have come up again in recent years to try to compete with x86/x64, ARM, and especially RISC-V (because they are in danger of being wiped out by the newcomer): MIPS, PowerPC / POWER, and SPARC certainly need no introduction, having also contributed to the history of computing in recent decades.
The main card they have used to relaunch themselves consists of the openness of their technologies, by which they mean the elimination of the fees (user licenses) to be paid to the holders of their intellectual properties, which not coincidentally is RISC-V’s greatest advantage that has contributed to its recent popularity.
The problem, however, is that the companies to which they belong moved very late (which is part of the reason they were swallowed up by Intel and AMD first, and later by ARM as well) to make their architectures attractive and gain market share for them.
But another major problem that plagues them is that they do not propose a homogeneous ecosystem capable of meeting the needs of any industry in which they compete (from embedded to HPC): they remain based basically on their very old ISAs, to which various instructions have been added over the years, of course, including extensions to try to mitigate the major problems of very low code density that have characterized them since their introduction.
They represent, in short, a collection of heterogeneous pieces to be put together as required, depending on what is needed. RISC-V already started out with a single ISA (plus countless extensions, but the basic structure is and remains the same: at the most new instructions are added), and so does NEx64T. So it escapes us what could be the added value of these older architectures, apart from the support and library of existing software, since they excel neither in code density nor performance.
The benefits of being a “Super CISC!”
Turning now to talk about the inherent advantages of NEx64T, in this day and age it may seem anachronistic if not outright blasphemy (because of the pounding propaganda that has polarized the general consensus on supposed RISCs, which are actually L/S ISAs, as already extensively explained in a recent series of articles), but it must be said that compared to the competition it has the advantage of being… a CISC! Indeed, a “Super CISC,” considering that x86 and x64 are also CISCs, but this new architecture goes far beyond that.
In fact, this ISA allows referencing not one, but up to two operands in memory with all “normal” instructions (not the “compact” ones, to be clear), as well as purposely providing a compact version of the MOV instruction that is now able to copy a data item directly from one memory location to another (x86 and x64 are also able to do this with the MOVS instruction, which is much more limited, however).
This choice has brought significant benefits (as already explained in great detail in a previous article), which are summarized in the following main points:
- Less use of registers to store data that are needed only once (temporarily);
- elimination of dependencies & penalties due to load-to-use in the pipeline (when you have to wait until a piece of data is available to finally use it);
- fewer instructions executed (and, in general, better code density because of this).
The first point may seem trivial and not so important, but it has a not inconsiderable weight in areas where there are few registers available, because you want to reduce the area (silicon)/transistors used and, consequently, also reduce power consumption.
But such a choice has positive spin-offs in any domain (so not just embedded), because dirtying more registers often also means having to preserve their original contents at the beginning of the subprograms that use them, and then restore them at the end (before returning control to the caller). So, and without going into too much detail talking about specific architectures, you need to execute more instructions, impacting (negatively) performance and code density.
For the second point, it may be more difficult to assess its impact, because it seems more like a purely technical issue (it is, indeed). Actually, these are very common cases, because it happens very often that you need to read a data item from memory, and then process it.
The problem is that using one instruction only to read it, and then another to process it, causes a dependency in the pipeline (and, consequently, a penalty of a certain number of clock cycles): the processor is forced to wait until the data has been read and finally available in the register, in order to use it and, therefore, finalize the operation.
This penalty does not exist in a CISC processor that allows a data to be referenced directly in memory without, therefore, going through a register, because as soon as the data becomes available (thus as soon as the AGU has finished its work), the execution unit can process it immediately.
L/S processors can also exploit stratagems that lead to similar results. For example, SiFive’s U74-MC processor is based on the RISC-V architecture and allows it to eliminate the load-to-use penalty in most cases, as can be seen from the following diagram from its manual:
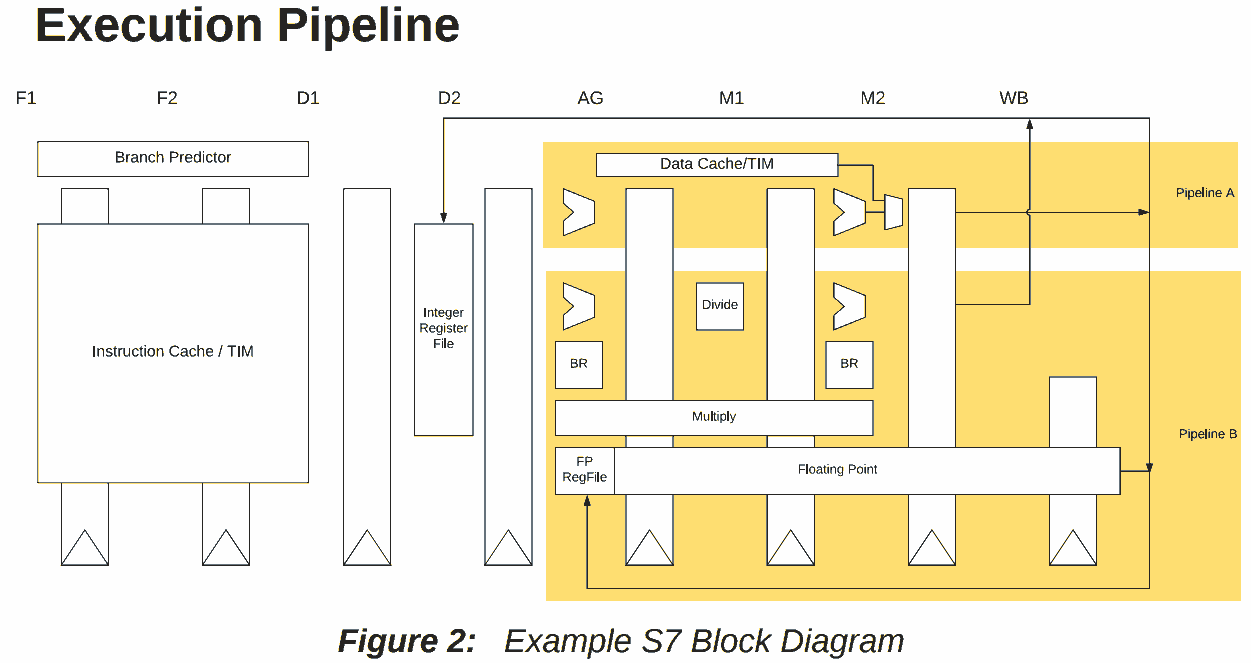
and by the following description:
The S7 execution unit is a dual-issue, in-order pipeline. The pipeline comprises eight stages:
two stages of instruction fetch (F1 and F2), two stages of instruction decode (D1 and D2),
address generation (AG), two stages of data memory access (M1 and M2), and register writeback (WB). The pipeline has a peak execution rate of two instructions per clock cycle, and is
fully bypassed so that most instructions have a one-cycle result latency:
- Loads produce their result in the M2 stage. There is no load-use delay for most integer
instructions. However, effective addresses for memory accesses are always computed in the AG stage. Hence, loads, stores, and indirect jumps require their address operands to be
ready when the instruction enters AG. If an address-generation operation depends upon a
load from memory, then the load-use delay is two cycles.
This is not done, however, without cost. In fact, the microarchitecture needs special logic that performs checks on the two executed instructions, to see if one or both operands of the second instruction use the register that is affected by the first instruction (which will eventually contain the value read from memory).
None of this is necessary in a CISC processor, because the data read is immediately used, as already explained: no additional logic is needed, since it turns out to be “already implemented” (it is inherent in the operation of the processor). Therefore, “at zero cost.”
Finally, for the third point, there are also cases in which the number of registers available is not sufficient for the implementation of a particular algorithm, so the processor will be forced to use the stack, for example, as a “temporary area” in which to store data from certain registers, and then restore it when the job is done, spending time going back and forth with data on and from the stack.
Being able to reference as many as two operands in memory helps a lot in these cases, eliminating several instructions to execute. This does not happen, however, only in these scenarios, as it can also occur when there are enough registers available, but you can still directly reference operands in memory, saving instructions to execute.
Which means that CISC processors such as and, especially, NEx64T may require less wide pipelines (with fewer instructions decoded and executed per clock cycle) than others (especially L/S ones), as is also shown by a study that was published a few years ago, which compared different architectures and microarchitectures of the time:

As can be seen, an older Atom (x86/x64) that has a two-way in-order pipeline obliterates the A8 (ARM, also two-way in-order), disintegrates even the A9 (ARM, two-way out-of-order), and even manages to be competitive with the A15 (ARM, three-way out-of-order)!
The reasons are given in the conclusion of the article, from which I extract the relevant part (relative to a benchmark that was investigated. But similar situations are common with L/S ISAs):
The Cortex processors execute dramatically more instructions for the same results.
Which is not surprising. In fact, it is even quite obvious, once you consider that to increment a memory location, for example, an L/S architecture has to execute as many as three instructions (load the value into a register, increment the register, and finally write back the content), while a CISC such as the Atom manages to do the same with just one instruction…
Having the ability to be able to execute fewer instructions than other architectures is a very important factor that should not be underestimated, since it entails significant changes at the microarchitecture level: it is one thing to decode and execute 2 instructions per clock cycles in an in-order pipeline, and quite another thing to do so with an out-or-order one (and worse still by increasing the number of instructions per clock cycle).
One can take note of this by reading the aforementioned RISC-V architect’s paper, which gives some information about this (although sometimes not immediately visible):
- Control-flow changes on integer workloads already at point where wider front end will have to predict multiple PCs to be effective.
- move to larger BTB structures that are decoupled from instruction fetch (and hence encoding) makes finding instruction start boundaries less critical.
- Cracking high-frequency instructions in a superscalar requires complex decode->dispatch buffer management and increases per-instruction tracking costs.
- Variable amount of cracking in highly superscalar decode adds mux complexity in downstream uop queue datapath that can add to branch resolution latency.
To simplify, the more instructions one has to decode and execute in a superscalar pipeline, and obviously the more resources a processor needs (more decoders in the frontend, and more information to keep track of instruction execution in the backend).
It is evident from what has been said ‘til now that NEx64T is in a privileged situation compared to any other architecture analyzed so far, in that it can perform much more “useful work” with its instructions, significantly reducing the number of those that must be executed to accomplish a given task.
Which means it can achieve higher or comparable performance than microarchitectures implementing other ISAs, but needing fewer resources overall. Fewer instructions to decode and execute per clock cycle, for example. Or less L1 instruction cache, due to excellent code density. Just to give some concrete examples.
From HPC to “low-cost” embedded
Similarly to ARM and RISC-V, the flexibility of this new architecture allows it to be used in a wide variety of areas, ranging from high & massive performance (HPC) thanks to the new SIMD/Vector unit (which we discussed extensively in the previous article), to embedded.
From the latter point of view, NEX64T manages to go even further than what is offered by ARM and RISC-V (which are the benchmarks in this market) by also being able to count on a 16-bit execution mode (absent in the other two) which, as it suggests, uses (general-purpose) registers of this size, thus saving on implementation costs when 16-bit is sufficient to manipulate data as well as the maximum 64kB of addressable memory, thus putting itself in competition with other “very low-cost” architectures operating in these segments.
What makes NEx64T more attractive than other 16-bit ISAs is that it allows, eventually, access to memory locations that are beyond the normally addressable 64kB (up to a few MB), thanks to some special very compact addressing modes that do not require offsets or pointers longer than the 16-bit that are normally usable.
This feature (if enabled) makes it possible to move some data (but not all: it is only possible to read or write directly to these “high” memory locations, but not to reference them via pointers) out of the “standard” 64kB, so as to save this precious memory for code, stack, and other data (that cannot fit anywhere else).
Another option offered, perhaps even more interesting than the previous one, is to be able to execute code beyond 64kB (up to a few MB), with only the PC (Program Counter) being 32-bit (all other registers remain 16-bit). This is because very often you are dealing with a lot more code rather than data, so this solution fits like a glove.
Obviously, only subroutine jump instructions are affected by this change, because they have to store or use the return address using 32 bits instead of 16. So it is not possible to compute addresses to jump to (via registers), but the former functionality lends itself, instead, very well to implementing VMTs or, in general, function pointer tables when this option is also used.
The difference, compared to many other 16-bit architectures, is that the handling remains simple and “homogeneous,” not requiring the introduction of bank registers or segments: the architecture remains perfectly consistent, as do all offsets and immediate values that always remain at 16 bits (maximum).
Again to try to minimize implementation costs, fewer registers can be used in the embedded domain. 32 general-purpose registers are great for the desktop/server/HPC sectors, but 16 is just fine when it comes to embedded. In areas where the constraints were even tighter, one might consider using only 8 registers (like x86, in essence), while still being able to rely on the possibility of being able to address as many as two memory locations in the instructions, which greatly mitigates the shortage.
Finally, and it was already mentioned in the article on addressing modes, just for the embedded (as well as system) domain it is possible to employ a special mode that is particularly useful when working in this field (as well as in special situations), which could make all the difference. Of this, however, I continue to avoid reporting further information for reasons that are intuitable.
Conclusions
It was not possible to go into much detail because the article is long enough in itself, but I think it is quite clear how NEx64T stands against the competition and why, despite being a “newcomer,” it would have quite a lot to say as well as offer.
Introducing a new architecture is by no means easy and requires not insignificant costs, but if there are advantages enough to justify the sacrifices it might be a road worth taking.
The next article will close the series by taking stock of the situation and putting some final considerations on the plate for reflection.







