Durante queste festività, ho trovato un po di tempo per dedicarmi ad uno dei miei hobby: la fotografia.
Questo mi ha fatto venir voglia di tornare a parlare di macchine fotografiche e soprattutto, considerato che non sono un fotografo ma un semplice appassionato alle prime armi con la fotografia ma con studi tecnico scientifici alle spalle, di dispositivi digitali per la fotografia e, in particolare, di sensori digitali, argomento, per altro, già trattato per un altro motivo.
Stavolta voglio parlare delle diverse tipologie di sensori digitali, iniziando con un’introduzione sui meccanismi di funzionamento di questo tipo di dispositivi.
Un sensore per immagini è un dispositivo che converte la luce incidente sulla sua superficie in impulsi elettrici che, a loro volta, sono convertiti in immagini. Questo processo passa attraverso varie fasi e prevede una trasformazione della radiazione incidente (discreta) in un segnale elettrico (continuo) e le successive operazioni di campionamento e quantizzazione di questo stesso segnale che deve essere messo in forma tale da poter essere elaborato dal processore d’immagini e, infine, ricostruito per essere inviato nella memoria dove viene salvato come immagine.
Poichè la luce incidente reca informazioni sull’immagine del mondo reale da “immortalare”, si può dire, senza essere tacciati di scarso rigore scientifico, che si parte da un’immagine contnua (quella del mondo reale) e attraverso una serie di operazioni di quantizzazione/ricostruzione, si torna ad un’immagine continua, la foto, con una serie di passaggi che ricordano molto da vicino quelli che abbiamo visto per la creazione di un’immagine 3D di un film animato o di un videogame.
E come per l’immagine 3D, incontriamo gli stessi problemi (aliasing) anche quando tentiamo di congelare un’istante di vita quotidiana in un’istantanea. Ovviamente, nel fare foto, si incontrano anche altri tipi di problemi legati al sistema, molto complesso e che mette insieme elementi di tipo analogico e di tipo digitale, formato da lente, filtro antimoire, sensore e processore di immagine.
Come detto, dunque, i fotoni incidenti passano attraverso la lente che li guida verso il sensore. La lente, sulle cui caratteristiche non mi dilungherò, ha il compito fondamentale di far pervenire sul sensore quanta più luce possibile, evitando distorsioni e aberrazioni cromatiche di sorta.
Detto ciò, iniziamo con l’introdurre la struttura tipica di un sensore digitale; si tratta di una matrice di pixel nxm, disposti a reticolo. Come ogni dispositivo digitale, anche i sensori delle fotocamere e delle videocamere fanno uso dei soliti 3 colori (rosso, verde e blu) che combinati tra di loro, con la luminanza (ovvero l’intensità luminosa registrata) a fare da funzione peso, permettono di ricavare tutti gli altri colori. In pratica esistono due tipi di sensore, indipendentemente dalla tecnologia adottata e dalla forma dei pixel: quelli a matrice bayer e quelli che adottano la tecnologia X3 di Foveon.
I primi presentano una disposizione dei 3 colori che chiameremo, impropriamente, di base, sullo stesso piano; i secondi presentano una disposizione di tipo stratificata, con il blu a comporre lo strato superiore con a seguire il verde ed il rosso.
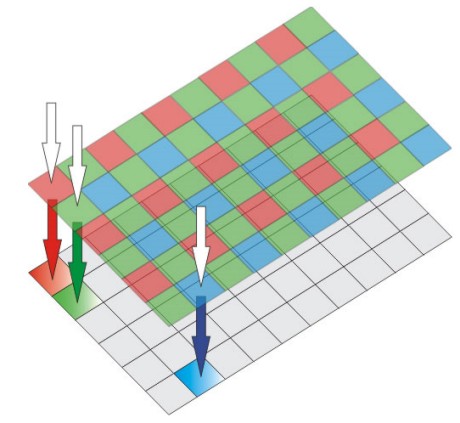
Nei sensori con pattern di tipo bayer, sul sensore, che è di tipo monocromatico, è applicata una maschera su cui, per ogni pixel, si attua una suddivisione in 4 subpixel, 1 rosso, 1 blu e 2 verdi (perchè l’occhio umano è più sensibile al verde e, di conseguenza, è opportuno che su quelle frequenze l’informazione catturata sia massima) nel modo indicato in figura
Il sensore vero e proprio, quello al di sotto della maschera, cattura l’intensità luminosa ed è formato, sia che si parli di cmos che di ccd, di una matrice di fotodiodi; la maschera fornisce le informazioni sul colore, filtrando le componenti indesiderate; in pratica, la maschera non fa altro che permettere alle componenti del colore indicato per ogni subpixel, di attraversarla per raggiungere il sensore, riflettendo tutte le altre (per questo motivo si schematizza con quadratini rossi, blu e verdi).
Il processore, ricevute le informazioni necessarie, abbina al colore corrispondente ad una determinata locazione sulla maschera la relativa intensità luminosa ricevuta. Quindi fa lo stesso per i subpixel contigui e, interpolando i 4 valori di un rosso, un blu e due verdi, ricava il valore di un singolo pixel.
Nell’immagine, ad esempio, il primo pixel lo si ricava partendo dal subpixel rosso in alto a sinistra e, muovendosi in senso orario, andndo a toccare il subpixel verde al suo fianco e poi, in oordine, il blu ed il verde posti al di sotto dei primi due. Il pixel successivo, sulla stessa riga, invece, lo si ricava partendo dal subpixel verde immediatamente successivo al primo rosso e così vie.
Quindi, ad esclusione dei subpixel sui bordi, tutti gli altri vengono utilizzati per ricavare informazioni per 4 pixel. Appare chiaro che questo tipo di sensore, per ogni locazione, riesce a catturare una sola componente di colore e richiede una necessaria operazione di demosaicing ai fini della composizione dell’immagine (l’immagine, di fatto, è composta dalle tessere di un mosaico), come illustra la seguente figura
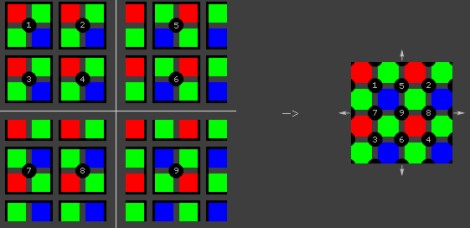
da cui si vede in che maniera, partendo da 16 subpixel sia possibile ricavare 9 pixel. Esistono diversi tipi di algoritmi di demosaicing, più o meno sofisticati, che si occupano non solo di interpolare i valori di subpixel noti ma anche di ricostruire quelli di subpixel mancanti.
Gli algoritmi di ricostruzione più semplici sono basati sulla conoscenza dei valori relativi ad un solo colore: ad esempio, se mancano o sono di difficile lettura i dati di un subpixel rosso, queati saranno ricostruiti partendo dai valori degli altri subpixel rossi i cui valori sono conosciuti. Gli algoritmi più complessi, invece, lavorano utilizzando anche i valori dei subpixel contigui a quello che si deve ricostruire, compresi quelli di diverso colore.
L’operazione di demosaicing, per quanto possa essere sofisticata, dà luogo ad artefatti, il più comune tra i quali è noto come moire e risulta evidente quando si tenta di ricostruire qualcosa assimilabile ad un reticolo periodico utilizzando un altro reticolo periodico a diversa frequenza spaziale, oppure con differente angolo (il pattern del sensore). Nelle immagini in basso, uno schema che spiega la formazione del moire in caso di pattern con differente angolazione
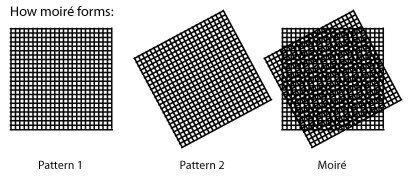
e l’effetto che si determina

La presenza di questo tipo di artefatti che rientrano nella categoria di quelli classificabili come aliasing spaziale, obbligano all’uso di appositi filtri che, nella fattispecie, sono di tipo fisico, costituiti da una lente posta sul sensore che ha il compito fare quello che solitamente viene fatto dal filtro antialiasing che abbiamo imparato a conoscere negli articoli dedicati a quella tipologia di fenomeni.
In pratica, il filtro antimiore, definito anche filtro antialiasing, non fa altro che fare operazione di blurring tra 4 subpixel contigui, secondo uno schema riconducibile ad un pattern di tipo rotated grid; in tal modo, si riduce l’effetto dell’aliasing ma si rendono più morbide le immagini.
Alcuni metodi per ridurre il moire sono quelli di aumentare la frequenza di campionamento spaziale, ovvero aumentare la risoluzione del sensore, ma, oltre un certo limite, si può incorrere in problemi derivanti dalla diffrazione e si ha un incremento del rumore digitale ad alti ISO.
Alcuni produttori scelgono di implementare filtri antimoire meno aggressivi (ad esempio Pentax con la K20D) col risultato di aumentare il potere risolvente del sistema lente sensore (quella che in gergo si definisce risoluzione assoluta e si misura in LPH) ma di diminuire la risoluzione di estinzione a causa del moire.
Di concezione differente il sensore X3 di Foveon. In questo caso, si sfrutta il principio che una radiazione incidente è in grado di penetrare tanto più in profondità quanto più è grande la sua lunghezza d’onda. Quanto asserito è riportato quantitativamente nell’immagine seguente
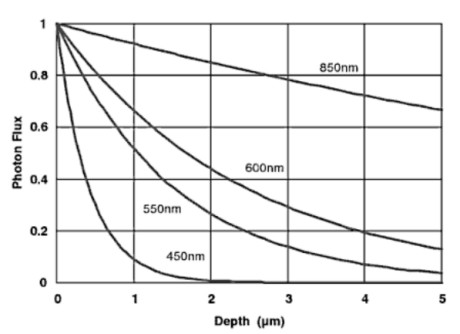
Alle lunghezze d’onda inferiori (la cui capacità di penetrazione è molto ridotta) corrisponde la banda del blu, a quelle superiori quella del rosso. Partendo da questo principio, un sensore foveon si compone di tre strati di silicio, uno per ogni colore, nel modo seguente
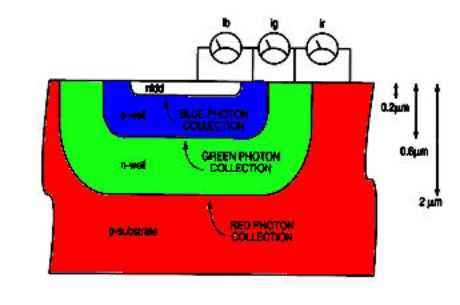
Come è possibile vedere da questo schema, formalmente ogni pixel è ancora scomponibile in subpixel questa volta nel numero di 3 e disposti in verticale e non sullo stesso piano; come per il sensore bayer, è ancora necessaria l’operazione di interpolazione tra le 3 componenti cromatiche di base per ottenere la crominanza del singolo fotosito.
Quello che cambia è il fatto che, in questo caso, i subpixel di un singolo pixel sono usati solo per determinare il valore cromatico di quel pixel e non sono riutilizzati per determinare anche i valori dei pixel vicini.
Contrariamente ai filtri di tipo bayer, non è dunque necessaria l’operazione di demosaicing anche se si deve, comunque ricorrere ad un’interpolazione. Questo diminuisce l’impatto dell’aliasing e permette alle fotocamere che fanno uso di sensore X3 di non avere il filtro antimoire.
Quindi, ricapitolando e volendo schematizzare al massimo, un sensore è un collettore di fotoni a cui sono collegati dei circuiti elettronici che hanno il compito di “leggere” l’intensità luminosa per ogni componente cromatica delle tre di base, tradurla in segnali elettrici (una carica o un livello di tensione a seconda della tipologia di sensore) interpretabili da un processore che ha il compito di ricostruire l’immagine finale.
Per svolgere al meglio questo compito, la matrice di fotodiodi di cui è composto ils ensore, ha bisogno di raccogliere quanta più informazione possibile, cercando di evitare o ridurre interferenze o disturbi di varia natura (qualcuno lo vedremo le prossime settimane). A tal fine, il sensore deve essere “aiutato” tramite l’uso di lenti di buona qualità, deve avere opportune dimensioni dei fotositi, non inferiori a certe dimensioni (per evitare la diffrazione e per raccogliere il maggior quantitativo di fotoni) e, spesso, viene dotato di dispositivi, come microlenti focalizzanti, per concentrare il maggior quantitativo possibile di fotoni sulla parte fotosensibile del pixel.
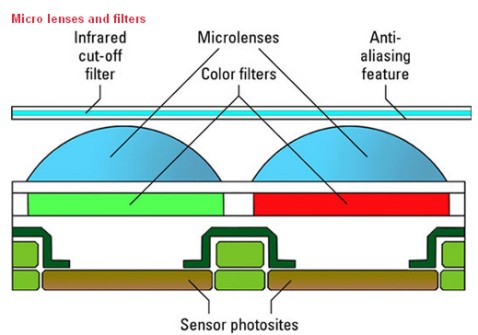
Quello riportao qui sopra è lo schema tipico di un sensore, sia esso cmos, ccd, nmos (i live mos di Olympus) o X3 di foveon (qualcuno avrà notato la forma ottagonale dei pixel, il che non lascia adito a dubbi sul fatto che si tratta di uno schema di un superccd di Fuji, ma di questo parleremo in una prossima puntata).
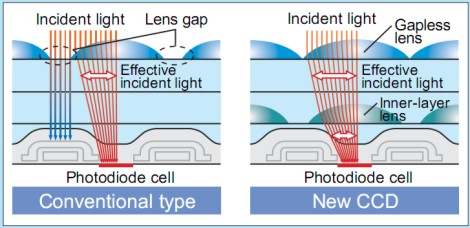
Ovviamente, a seconda della tipologia di sensore, alcuni elementi possono o meno essere presenti: ad esempio, alcune medio formato con risoluzioni non troppo elevate, hanno sensori privi di microlenti, oppure le fotocamere (Sigma) con sensore X3 non hanno il filtro antimoire; alcune fotocamere non hanno filtro per infrarossi. In altri casi, per i sensori più “affollati” e con fotositi più piccoli, le microlenti sono di tipo gapless o, addirittura, presentano un doppio strato di microlenti, uno di tipo gapless ed uno, più interno, di tipo tradizionale, come si vede in basso
Dopo questa breve introduzione sui sensori digitali, nelle rpossime settimane approfondiremo la conoscenza sulla loro architetutra e funzionalità, introducendo anche delle distinzioni tra le varie tecnologie adottate (magari sfatando qualche mito come quello del minor costo dei sensori cmos, ad esempio); faremo un tour tra le varie soluzioni adottate per migliorare alcune delle caratteristiche basilari (risoluzione, gamma dinamica, velocità di acquisizione delle immagini, rumore ad alti ISO), facendo la conoscenza con alcuni dei parametri con cui ci si deve cimentare quando si progetta un sensore digitale.
Vedremo come alcuni produttori si siano sbizzarriti a cercare soluzioni alternative (la matrice bayer a 4 colori di Sony, quella con matrice di tipo complementare utilizzata soprattutto nelle videocamere) e daremo un’occhiata ad una delle tecnologie più promettenti, ovvero quella dei sensori di tipo back illuminated (per la serie “a volte ritornano”).
Tanti auguri a tutti.








{kind=link}