Nell’articolo della scorsa settimana si è iniziato ad affrontare il discorso relativo all’architettura a blocchi di una gpu. Si è fatta anche una breve sintesi dell’evoluzione delle architetture, o meglio, di parte di esse, al mutare delle API di riferimento.
Questa settimana vorrei proseguire sulla stessa falsariga, scendendo un po’ più in dettagli di tipo architetturale ma, anche, facendo una breve analisi della filosofia progettuale che ispira i due principali protagonisti del mercato delle gpu: ATi, ovvero AMD e nVidia. Con questo non intendo raccontare la storia delle due società ma di parlare di come si è evoluto il loro modo di progettare i chip grafici nel corso degli anni.
Correva l’anno 1995 quando una quasi neonata nVidia introduceva sul mercato il suo primo chip. l’NV1, che proponeva soluzioni, per l’epoca, rivoluzionarie; vale la pena di ricordare che includeva funzionalità audio, oltre a quelle 2D/3D e faceva uso di texture quadratiche come primitive. Queste ultime permettevano di ridurre il carico di lavoro sulla cpu e di velocizzare alcune operazioni di rendering (tra cui la rappresentazione delle superfici curve). Nello stesso periodo, ATi era già una società affermata e si proponeva come alternativa economica a Matrox per coloro che avevano intenzione di fare del pc una stazione multimediale.
Le texture quadratiche non ebbero fortuna poichè le DirectX, poco tempo dopo, adottavano come standard i poligoni basati sui triangoli (che sono utilizzati ancora oggi). Questo, unito alle non esaltanti performance in 2D dell’NV1, decretarono l’insuccesso di quel progetto e spinsero nVidia ad abbandonare anche il successivo progetto. NV2, che faceva uso delle stesse tecniche.
Quel mercato, caratterizzato da un certo “immobilismo tecnologico”, era dominato, numericamente, da S3 che con i suoi chip delle serie Trio e Virge equipaggiava la stragrande maggioranza delle vga, di fascia media e bassa, allora in commercio. L’accelerazione 3D, invece, a cavallo tra la fine degli anni ’90 e l’inizio del III millennio, era monopolio di 3dfx.
Dopo il flop di NV1, nVidia mostra una grande vitalità ed una altrettanto notevole capacità di ripresa: abbandona, per il momento, l’idea di imporre le sue scelte, consapevole di non averne la forza, e decide di adeguarsi agli standard. Questo non significa che si accontenti, anzi, decide di puntare molto in alto, dove nessuno aveva mai osato guardare: ovvero al monopolio di 3dfx. Escono, in successione, i chip Riva 128 e 128 ZX, i primi ad adottare un bus ed un’architettura interna a 128 bit, il Riva TNT ed il TNT2, ovvero la prima famiglia di chip ad adottare un’architettura con la doppia pipeline di rendering, qui messa a confronto con quella delle Voodoo 2 e 3 e del Rage Pro
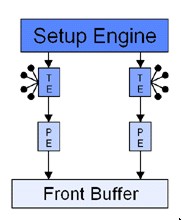 Riva TNT
Riva TNT 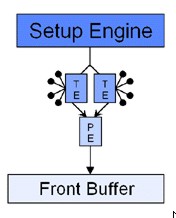 Voodoo 2 e 3
Voodoo 2 e 3 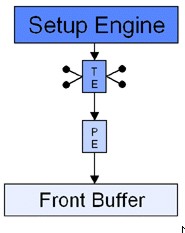 RagePro
RagePro
Nelle immagini, le unità indicate come TE sono le texture unit, mentre quelle indicate con PE sono l’equivalente delle attuali ROP’s, ovvero le unità che si occupano di “scrivere” i pixel. Il vantaggio di un’architettura come quella di NV4 rd NV5 è evidente: a parità di capacità di texturing, rispetto ai chip di 3dfx si ha un maggior parallelismo, ovvero, a parità di texel fillrate, si ha un maggior pixel fillrate, almeno in caso di single texturing.
L’architettura di NV4 sarà ripresa da ATi con il Rage 128 e migliorata da Matrox con il chip MGA400, con cui adotterà anche un’architettura interna a 256 bit di tipo dual bus (128 bit per i dati in ingresso e 129 per quelli in uscita), interfacciato con un MC a 128 bit ed una superiore capacità di texture sampling rispetto a quella del TNT 2 e del Rage 128.
Dopo l’esperimento TnT (twin texel engine), nVidia spinge ancora oltre il parallelismo, adottando anche, in contemporanea con S3, una unità di calcolo di tipo geometrico di tipo fixed function che, nell’immagine è schematizzata con i blocchi “transform” e “lightning”.
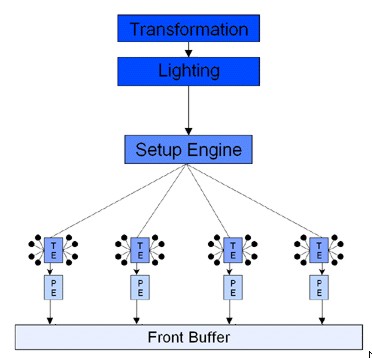
Questa architettura che è quella di NV10, chip noto come Geforce 256, nome derivante dall’adozione di un’arhcitettura interna a 256 bit, sarà modificata con l’aggiunta di una seconda tmu (o TE) per ogni pipeline, in NV15 (Geforce 2). A questo punto, ormai, nVidia ha soppiantato S3 come principale fornitore di chip a terze parti per il segmento consumer e con NV15 ha tolto a 3dfx lo scettro delle prestazioni nel 3D.
Tutto ciò è stato possibile in soli 4 anni, dopo il pesante fallimento del progetto NV1/NV2, grazie ad una politica aggressiva, di innovazione continua e di ritmi forsennati (qualcuno ricorderà la politica del “nuovo chip o un refresh di una esistente architettura ogni 6 mesi“). Proprio questi ritmi indiavolati permettono a nVidia di riuscire ad imporsi in un mercato che nel 1996 era popolato da decine di progettisti e fabbricanti di chip grafici e vga discrete e che nel 2000 si è ridotto a soli 3 soggetti “significativi”, ATi, nVidia e 3dfx, con Matrox ed S3 ormai relegati a mercati di nicchia (con Intel che continuava a spadroneggiare nel mercato delle vga integrate, fino ad allora di scarso interesse).
Nel frattempo, cosa faceva ATi? In seguito all’accelerazione imposta da nVidia al mercato delle vga discrete e alla transizione, conseguente, da adattatori grafici 2D più acceleratori 3D all’adozione di schede 2D/3D, non solo si è dovuta adeguare ai nuovi ritmi ma, potendo contare su una capacità progettuale e produttiva di gran lunga superiore a quella della media dei concorrenti, ha iniziato a progettare e realizzare chip e schede video sempre più potenti e innovativi, fino a restare l’unica in grado di opporsi alla corsa di nVidia. Dopo il Rage 128 ed il Rage 128 GL, chip ancora di “vecchia concezione”, arrivano, in sequenza, l’R100, l’R200 e l’R300. Il passaggio a chip dotati di unità “geometriche” e l’adozione del nome Radeon segna un punto di svolta. Pur non snaturando la natura multimediale dei suoi prodotti, ATi inizia a puntare anche alle prestazioni ed alle feature. Così, R100 risulta un chip più avanzato rispetto alle stesse APi di riferimento, le DX7, introducendo, seppure tramite FF, feature come il vertex skinning e la keyframe interpolation che anticipano soluzioni che saranno adottate, grazie agli shader programmabili, con i chip della generazione successiva. Per le soluzioni adottate, R100 è il chip più avanzato del periodo: non ha la forza bruta dell’NV15 in fatto di pixel fillrate e neppure può vantare un efficace sistema di HSR a livello di quello dei chip di PowerVR (Kyro e Kyro2), come non ha una qualità dei filtri a livello di quella della Voodoo 5, ma ha una suffuciente potenza di calcolo da poter competere, a 32 bit e, persino battere, in D3D, la Geforce 2; ha unità geometriche più avanzate di quelle dell’NV15 e una pipeline con 3 TMU che la mettono in condizione di applicare effetti come l’EMBM in single pass. Ha anche una serie di algoritmi di HSR che prendono il nome di Hyper-z (mentre, ad esempio, sia il chip 3dfx che quello nVidia sono sprovvisti della possibilità di effettuare la rimozione preventiva dei poligoni nascosti).
Dopo R100 arriva R200, chip che adotta lo sm1.1 per i VS e l’1,4 per i PS, andando oltre le specifiche di NV20 e NV25. R200 è anche il primo chip ad adottare un circuito, con relativo algoritmo, per le higher order surface che fa uso di n-patches (il truform).
Finora, dunque, abbiamo visto come, nel periodo ’95 – 2000, nVidia abbia fatto la lepre, innovando e imponendo ritmi vertiginosi all’evoluzione dei chip grafici mentre gli altri, ad iniziare da ATi, si sono adeguati, quando hanno potuto, a quei ritmi. Dal 2000 in poi, dopo aver raggiunto il vertice a livello di capacità di penetrazione del mercato ma anche a livello di innovazione e prestazioni, la corsa di nVidia sembra rallentare. Da un lato, NV15, NV20, NV25, ma anche NV30 ed NV35, continuano a presentare la stessa architettura 4×2, pur inroducendo diverse novità tra una generazione e l’altra. Dall’altro lato, ATi, ad ogni generazione, rivoluziona la sua architettura, fino ad arrivare ad R300, chip da cui, nVidia che aveva per prima intuito i vantaggi derivanti dal parallelismo spinto, si lascia sorprendere proprio sulla capacità di calcolo parallelo, quel pixel fillrate che aveva decretato il successo di NV4 e di NV10.
NV30 non è un progetto “sbagliato” ma un progetto nato su un’architettura vecchia, quella di NV25, di cui conservava ancora la struttura a 4 pipeline con 2 tmu ciascuna e una spiccata predisposizione ai calcoli in virgole fissa piuttosto che in virgola mobile introdotti dalle DX9. A queste carenze si unisce un bus esterno a soli 128 bit, errore corretto con NV35, e una carenza di registri temporanei nelle unità di pixel shading, ovvero quei registri che si usano per immagazzinare i dati dei calcoli intermedi. Altro limite, la dipendenza della alu principale, l’unica in FP delle 3 presenti su ogni pipeline di NV30, dalle operazioni di texturing. Questo significa che una pipeline era in grado di effettuare operazioni in floating point solo in assenza di operazioni di texturing. Di contro, NV30 aveva un elevato numero di registri costanti ed aveva una capacità di effettuare calcoli di tipo ricorsivo nettamente superiore a quella di R300. Il problema era che il chip, nato ufficialmente per le DX9, era debole proprio nelle operazioni in floating point e in caso di elevata “pressione” sui registri temporanei (il limite di NV30 e dei suoi derivati era di 2, mentre per R300 si arrivava a 4 registri temporanei prima di assistere ad un calo delle prestazioni in FP).
La carenza di registri temporanei si manifestava in fp32, mentre in fp16 il limite era imposto dalla dipendenza dell’alu principale dalle tmu e dalla presenza, su NV30 e derivati, di minialu di tipo INT. Su NV35 si cercò di rimediare il possibile, sostituendo le minialu INT con minialu FP che, però, non essendo di tipo completo, non avevano la stessa capacità di calcolo dell’alu principale che restava dipendente dalle TMU (e lo sarà anche in NV40 e G70). Restava, però, il limite dei registri temporanei in fp32. In basso, un’immagine che dà l’idea dell’architettura della singola pixel pipeline di NV30 ed NV35
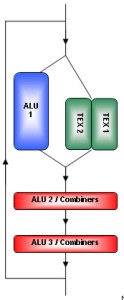
dove quella indicata come ALU1 è l’alu principale di tipo full vect con 4 unità fp32. Le altre due sono minialu che in NV30 sono di tipo INT e in NV35 di tipo fp.
Dopo R300 ed NV30, è ATi quella che sembra sedersi, proponendo un chip che, qualcuno ha definito, probabilmente a ragione, un R300x2. Infatti R420 non presentava grandi innovazioni rispetto ad R300 se non il raddoppio delle pixel pipeline ed un aaumento delle unità di vertex shading. A R420, nVidia risponde, questa volta, con un chip che, pur avendo ereditato qualche difetto da NV30 (la dipendenza dell’alu principale dalla TMU) , propone un’arhcitettura profondamente rinnovata.In basso la singola pixel pipeline delle 16 presenti su NV40
![]()
La serie 6 di nVidia, prestazionalmente è quasi allineata alla concorrenza ma, rispetto ai chip ATi, è molto più innovativa e, soprattutto, è una famiglia di chip realmente DX9, anzi, rispetto ai rivali, adotta uno SM più avanzato.
Cosa ha portato a questo ulteriore ribaltamento dei ruoli? Semplice, ATi era intenta a sviluppare un nuovo chip che fosse SM3.0 compliant (la serie R5x0) e, di conseguenza, non aveva risorse da impiegare per lo sviluppo di un altro chip da contrapporre a NV40. Quindi, se ATi ha vinta prima battaglia sulle DX9, a nVidia è andato il secondo round. Con G70, nVidia si limita ad aggiustare e potenziare l’ottimo NV40, mentre ATi sviluppa un chip che introduce interessanti feature alcune delle quali saranno riproposte anche in R600, come, ad esempio, il ring bus o, meglio, un semi ring bus (l’inoltro delle richieste, di accesso alla ram, su R5x0, avviene sempre tramite un crossbar e solo i dati sono inoltrati attraverso il ring bus).
D’altro canto, anche nVidia, con Nv40 prima e G70 dopo, getta le basi dell’architettura superscalare di G80.
Si arriva all’ultima serie di chip, quelli DX10. ATi sviluppa un chip in cui si tenta di ridurre al minimo i circuiti di controllo e trasmissione dei dati e delle istruzioni, nonchè di minimizzare il numero di registri necessari all’esecuzione della singola istruzione. Al contrario, nVidia preferisce adottare una soluzione che gestisca completamente in HW sia il bilanciamento dei carichi di lavoro che la parallelizzazione delle istruzioni. Di conseguenza, ATi adotta un’architettura di tipo MIMD di cluster SIMD con alu VLIW, mentre nVidia adotta un’architettura MIMD di alu SIMD. In entrambi i chip, si ha un sistema di controller (arbiter e sequencer) in cascata, con un thread dispatch processor principale che distribuisce i thread tra i vari cluster di alu; in R600 e derivati, ogni cluster è composto da 16 processori VLIW che operano in modalità VLIW; ogni cluster è gestito, a sua volta, da un controller che distribuisce i carichì di lavoro tra i 16 processori. Quella che, invece, non viene gestito in HW è la parallelizzazione a livello di microistruzioni, ovvero le operazioni di gouping e Fn assignment, ovvero il ragggruppamento delle istrizioni e la loro assegnazione alle singole alu. Ovvero, è compito del compilatore riunire insieme le singole microistruzioni da “dare in pasto” ad un processore di 5 unità VLIW.
Nei chip NV, invece, il controller principale distribuisce i thread tra i cluster di alu; all’interno di ogni cluster, un secondo controller si occupa di gestire la distribuzione dei thread tra le singole alu di ogni gruppo di 8+8 (in G80 che diventano 8+8+8 in GT200) unità scalari di tipo fp32. Quindi, di fatto, sui chip NV l’unico vincolo è rappresentato dal fatto che 8 alu lavorano in modalità SIMD, ovvero devono eseguire lo stesso tipo di istruzione delle unità dello stesso gruppo, seppure su dati differenti (vincolo che un’arhcitettura integralmente di tipo MIMD permetterebbe di superare).
R600 è caratterizzato da un errore tecnico, ossia l’aver affidato al ring bus anche la gestione del trasferimento dati non attinenti al 3D (errore a cui si è posto rimedio in RV770 con una linea dedicata) e da un errore di valutazione circa il rapporto tra operazioni matematiche e texture; in questo modo, R600 nasce con un rapporto alu/texture sovradimensionato rispetto a quanto richiesto da engine grafici ancora piuttosto datati. Infine, anche il rapporto tra il numero di processori di R600 e quello di G80 (64 VLIW contro 128 scalari) è molto meno favorevoale rispetto a quello di RV770 nei confronti di GT200 (160 a 240).
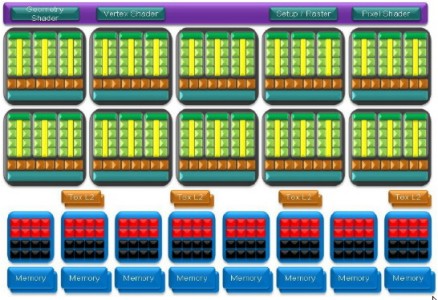
A ben guardare, esiste un’analogia tra questi chip a shader unificati (di cui riporto l’immagine di GT200 e RV770)
GT200
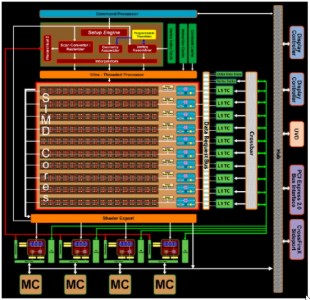 RV770
RV770
e i chip della precedente generazione e riguarda la complessità dei circuiti preposti a gestire il lavoro dei chip stessi: da un lato, ATi che propone, su R5x0, alu di tipo vect3 + scalar fp32 per i PS, contro le unità di tipo scalare di NV40 e G70, con una logica di controllo più complessa nel secondo caso, relativamente alla gestione del singolo gruppo di unità (da un lato un vettore dall’altro 4 scalari). Nei fatti, R5x0 presentava, però, nell’insieme, una logica molto più complessa a livello di architettura dell’intero chip, in quanto, per la prima volta, faceva la sua comparsa su una GPU un varo e proprio thread dispetch processor, ovvero un complicato insieme di arbiter e sequencer. Questo trend si ripete, in maniera più spinta, sui chip a shader unificati, con la scelta di ATi che privilegia la semplicità dei circuiti logici e di controllo, nonchè la flessibilità, dall’altro nVidia che mostra di preferire l’efficienza dell’architettura a scapito della complessità cirsuitale. Da un lato ATi punta sul numero di unità per compensare la minore efficienza, dall’altro nVidia preferisce adottare un minor numero di unità, ciascuna delle quali molto più complessa di quelle di R600 e compensa lo scarso numero con la maggior efficienza e l’elevata frequenza dello shader core. Esiste una analogia tra le alu vettoriali di R5x0 o di xenos e quelle VLIW di R600 con le seconde molto più flessibili rispetto alle prime ma che ugualmente necessitano di microistruzioni facenti parte dello stesso thread raggruppate tra loro; allo stesso modo esiste una analogia tra le alu di NV40 e quelle di G80 con l’architettura del secondo decisamente più efficiente e flessibile ma con gestione indipendente delle singole alu fp32.
Il risultato è che i chip ATi risultano meno trasperenti alle ottimizzazioni del SW e maggiormente ottimizzabili via SW, mentre i chip NV risultano molto meno dipendenti dal SW e si rivelano competitivi da subito.
Volendo fare un paragone di tipo politico, si potrebbe dire che nVidia, dopo aver attraverato la fase rivoluzionaria che ha permesso la presa del potere, è diventata conservatrice e cambia solo quando è costretta perchè messa alle corde: dall’altra ATi che dopo l’immobilismo iniziale si è trasformata in un partito “riformista”.
Di certo è che entrambe hanno contribuito all’evoluzione della grafica 3D riuscendo a proporre sempre, o quasi, prodotti competitivi, all’altezza di quelli della concorrenza, per quanto spesso differenti nelle soluzioni tecniche adottate. Di certo è che se in passato, in qualche occasione, è sembrato che, dal punto di vista delle architetture, le soluizoni adottate fossero abbastanza vicine (ad esempio la generazione DX8 e, in minima parte, NV40 ed R420), in quest’ultimo perdiodo sembra proprio che le due società abbiano preso strade decisamente divergenti: da un lata ATi con chip sempre più piccoli con elevato numero di unità di calcolo, abbastanza flessibili (anche se le ROP’s e le TMU fanno ancora uso di FF ma, almeno per le TMU, questo avverrà anche con Larrabee), ma dall’efficienza fortemente dipendente dalle ottimizzazioni del SW, dall’altro nVidia con chip sempre più complessi (si parla di architettura di tipo MIMD per GT300) con un numero di unità di calcolo relativamente ridotto ma dall’elevata efficienza e, molto meno dipendenti dal SW rispetto ai prodotti della concorrenza.







