Dopo aver analizzato la genesi delle primitive di un’immagine 3D e aver iniziato ad introdurre lo schema a blocchi di una gpu , passiamo, questa settimana, ad analizzare, un po’ più in dettaglio, alcuni degli elementi presenti all’interno di un microprocessore. Vale la pena di fare una breve sintesi sull’evoluzione delle architetture nel corso di questi anni per capire come mai alcuni elementi o blocchi interni ad un chip abbiano assunto, nel tempo, un’importanza sempre maggiore.
In particolare, mi riferisco, in questo caso, a due gruppi di elementi che caratterizzano sempre più le prestazioni dei chip grafici e non e occupano, ormai, uno spazio preponderante al loro interno: i dispositivi ed circuiti di controllo da una parte e le memorie dall’altra. In questo articolo non parlerò delle varie tipologie di ram e del loro funzionamento ma mi limiterò ad introdurre le tipologie di ram presenti, soprattutto, all’interno dei chip; parlerò del perchè sono diventate indispensabili al punto da occupare, oggi, un ruolo centrale nella progettazione di un chip grafico o di una CPU e inizierò ad introdurre alcune terminologie specifiche.
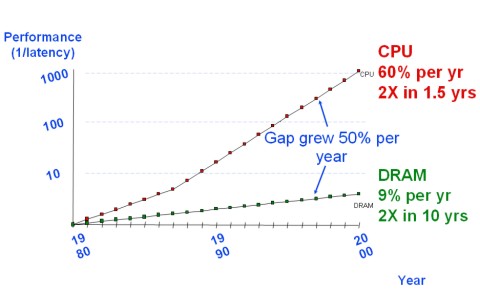
Come ha ricordato Cesare in questo interessante articolo, fino all’inizio degli anni ’80, le memorie erano i dispositivi più veloci ed era la capacità di elaborazione dei processori a fare da collo di bottiglia. Questo semplificava notevolmente le scelte a livello progettuale perchè non poneva il problema, che è divenuto centrale in seguito, di “disaccoppiare” le prestazioni dei processori da quelle delle ram.
Tra il 1980 ed il 2000, però, è successa una cosa del genere
che non solo ha permesso alle cpu di raggiungere e superare le ram, prestazionalemente parlando, ma ha fatto allargare a dismisura il gap tra di esse. E qualcosa di ancora peggiore è avvenuta tra la fine degli anni ’90 e i giorni nostri tra le ram e le gpu, il cui ritmo di crescita è stato, addirittura, di svariati ordini di grandezza superiore a quello delle cpu
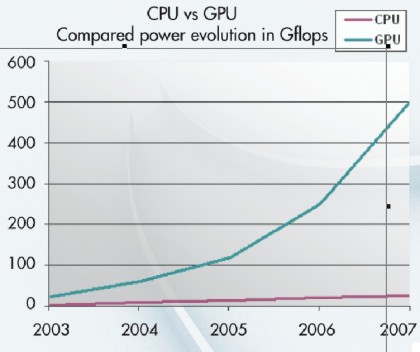
Tutto ciò ha costretto gli ingegneri ed i tecnici a modificare completamente l’approccio al progetto di un chip, poichè li ha messi di fronte a problematiche in passato del tutto inesistenti, che richiedevano una soluizone efficace che impedisse alle memorie di diventare un collo di bottiglia troppo stretto, destinato a vanificare tutti gli sforzi atti ad ottenere sempre più potenza di calcolo ed efficienza dai processori.
Il problema di fondo da risolvere era: come aumentare la velocità di trafserimento dei dati e delle informazioni da e verso chi questi dati e queste informazioni doveva utilizzarli, ovvero le pipeline di un processore. Partiamo dall’assunto che se si creasse una “corsia preferenziale” per ciascun automobilista, il traffico scorrerebbe molto velocemente e non ci sarebbero ingorghi. O meglio, questo sarebbe vero se l’automobilista in questione facesse sempre lo stesso percorso tra gli stessi due punti. Nei fatti non è così, un automobilista può avere mete differenti e, di conseguenza, essere obbligato a seguire strade diverse. Allora gli si dovrebbe costruire una corsia dedicata ad ogni meta da raggiungere e lo stesso si dovrebbe fare per tutti gli altri. I progettisti di chip, a partire dall’inizio degli anni ’80, si sono trovati ad affrontare un problema analogo in cui il posto degli automobilisti era preso dai dati che viaggiavano tra ram di sistema e processori. Nell’impossibilità di costruire una corsia dedicata a ciascun dato o istruzine in transito, hanno fatto una semplice considerazione: ci sono dati che vengono richiamati più frequentemente di altri e, di conseguenza, il velocizzare il trasferimento di questi permetterebbe un aumento della velocità di elaborazione. Per ottenere questo risultato, hanno pensato di creare, per questi dati, una via molto più ampia che potesse sopportare un traffico più intenso senza che si creassero ingorghi. Nasce, così, l’idea della cache, una speciale “memoria” in grado di garantire tempi d’accesso di molto inferiori rispetto a quelli della ram solitamente utilizzata. Per questo scopo, si sceglie un particolare tipo di ram, la SRAM, che ha una serie di pregi: è molto più veloce della ram di tipo DRAM o EDO o SDRAM, è molto meno sensibile alle interferenze e stabile e consuma anche meno rispetto alla ram di tipo dinamico, in quanto la potenza di tipo statico (teoricamente nulla ma praticamente presente) dissipata dai due CMOS Inverter di cui è composta uan cella di SRAM è notevolmente inferiore alla potenza necessaria alle operazioni di refresh necessarie per le ram di tipo dinamico. Ha, in pratica, due soli difetti: costa molto e la singola cella occupa molto più spazio di una singola cella di SDRAM del tipo comunemente usata per le VRAM o per la ram di sistema.
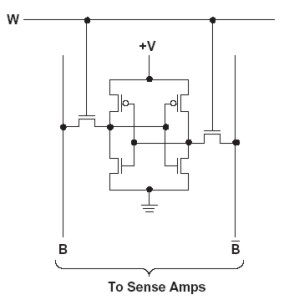
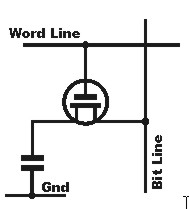
In figura una cella di SRAM 6T, ovvero del tipo tradizionale e più usato, con 6 transistor, tipicamente 2 nmos accoppiati con 2 pmos a formare i due inverter al centro e altri due nmos che pilotano il circuito. Esistono anche celle di SRAM di tipo 4T, come quella in basso
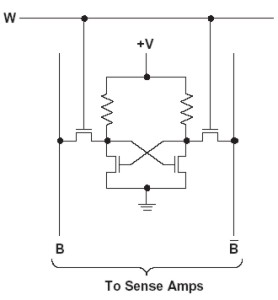
che, rispetto alla 6T, occupa meno spazio ma presenta alcuni inconvenienti: il primo di tutti è che le resistenze devono essere molto grandi (dell’ordine dei Gohm), per minimizzare la corrente che passa nei transistor. In una cella di tipo 4T, solitamente si fa uso di tecnologia nmos e questo, oltre all’elevato valore delle resistenze, rende il circuito meno insensibile ai disturbi di un circuito con celle 6T; infine, al diminuire del numero di transistor diminuiscono anche le prestazioni velocistiche della memoria.
Ci sono, inoltre, celle 3T anche se in quel caso sarebbe opportuno parlare di quasi-static RAM e, perfino, celle a 8 o più transistor per circuiti che richiedono particolari caratteristiche di affidabilità e velocità. L’architettura di tipo 6T resta, comunque, il miglior compromesso tra costi, benefici e spazio occupato ed è, pertanto, la più utilizzata (motivo per cui si dice comunemente che la SRAM ha celle a 6 transistor).
Per confronto, posto anche l’immagine di una cella di DRAM, formata, come si vede, da un transistor e da un condensatore
Di fatto, dunque, la cache ha lo scopo di “disaccoppiare” la ram dal processore, introducendo, tra i due, un elemento che mediasse, in qualche modo, tra le prestazioni velocistiche dei due e impedisse, il più possibile, alla ram di fare da freno alle prestazioni della cpu o della gpu che dir si voglia.
Ovviamente la ricerca delle soluzioni non si è fermata qui e un ulteriore passo (anche se temporalmente antecedente) è stato quello di spostare tutti i registri, di cui le unità interne di un processore fanno uso, all’interno dello stesso processore e, con le moderne architetture, di aumentarne il numero, a volte in maniera considerevole. Anche per i registri si fa uso di SRAM 6T e il loro scopo, tornando al parallelo con l’automobilista, è quello di creare una corsia preferenziale, seppure per un brevissimo tratto, ai dati che viaggiano da e verso le alu. In pratica ogni alu ha un certo numero di registri di vario tipo ad essa dedicatio un pool di registri condivisi con un numero limitato di unità simili, da cui prelevare i dati necessari all’esecuzione di una determinata istruzione. Altra mossa è stata quella di adottare tipologie di ram di sistema con architetture che permettessero uno scambio più effiicente dei dati e un più elevato bit rate, al fine di ampliare il canale di comunicazione tra ram e processore.
L’importanza di cache e registri è nelle latenze relative alle operazioni effettuate con essi; cito solo alcuni dati: il tempo d’accesso ad un dato contenuto in una cella di SRAM è di circa un ordine di grandezza inferiore rispetto ad un dato contenuto in una cella di SDRAM. Inoltre, l’accesso ad un dato contenuto in un registro, teoricamente, richiede un solo ciclo di clock che corrisponde a una manciata di ns (nanosecondi); per accedere ad un dato contenuto in una cache interna al chip si arriva a qualche decina di ns, in caso di cache hit, che arrivano all’ordine delle centinaiadi ns per dati contenuti nella main memory (memoria di sistema per le cpu o VRAM per le gpu).
Di fatto, l’organizzazione interna di un sistema comprendente cpu e gpu si può schematizzare nel modo che segue
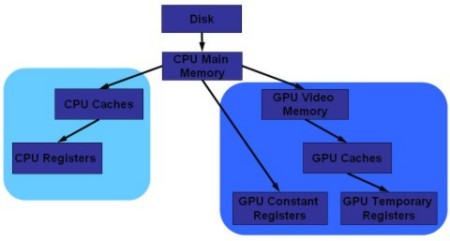
Nel diagramma ad albero si parte dal supporto di menoria più lento e si arriva a quelli più veloci; per registri e cache, come detto, si usa SRAM 6T, mentre per la cpu main memory (memoria di sistema) e per la GPU video memory memoria di tipo SDRAM (DDRn o GDDRn). I registri costanti sono locazioni dimenoria utilizzate solo in lettura e sono quelle all’interno delle quali vengono caricati i dati relativi ai thread da elaborare; i registri temporanei sono utilizzati per immagazzinare i dati intermedi di un’elaborazione e sono registri utilizzabili sia in lettura che in scrittura. All’interno di un chip esistono anche altri tipi di registri oltre quelli citati, come pure ci sono altri tipi di menorie come, ad esempio, i buffer, che si usano sia per le istruzioni che per i dati e si pososno schematizzare come una sorta di colonna di registri impilati gli uni sugli altri. Ci sono buffer di tipo FIFO (first in firts out) gestiti in modalità In Order; in tal caso, il primo elemento (dato o istruzione) ad essere immagazzinato è anche il primo ad essere elaborato una volta che il buffer è pieno; ci sono anche buffer getiti in modalità Out of Order e, in tal caso, una volta riempito il buffer, un arbiter deciderà qual è l’elemento che epr primo deve essere indirizzato a destinazione. Un esempio di buffer di tipo OoO, anche su chip che lavorano in modalità rigorosamente In Order (come ad esempio il cell di PS3) è quello in cui si immagazzinano le richieste di DMA (direct memory access). In quel caso l’arbiter presente nel MC deciderà quali richieste evadere per prime procedendo al riordino della coda.
Quella che nell’immagine è schematizzata semplicemente come cache merita un discorso a parte. Una cache, al contrario di quanto avviene per i registri, può, al pari dei buffer, essere interna o esterna al die del chip. Può, inoltre (anzi ormai è la prassi) essere a più livelli. Ha, inoltre, la caratteristica di presentare un’associazione tra le sue celle e quelle della main memory o della memoria video: presenta, insomma, quella che si chiama in gergo una mappatura rispetto alla memoria di sistema. Questo è l’elemento più caratteristico tra quelli che contraddistinguono la cache da qualunque altra tipologia di memoria locale.
Procediamo con ordine. Innanzitutto, la cache nasce con lo scopo di contenere i dati e le istruzioni più frequentemente utilizzati da un chip. In tal modo i tempi di accesso a quegli elementi si accorcia notevolmente velocizzando l’elaborazione. Quindi deve essere piuttosto grande? Si, deve essere sufficientemente grande ma se diventa molto, troppo grande, paradossalmente il tempo di accesso ai dati in essa contenuta si allunga, perchè ci vuole più tempo a cercare qualcosa in un contenitore molto grande pieno di roba che in uno molto piccolo. Quindi sarebbe meglio averla grande per metterci quanta più roba possibile ma se è troppo grande non riseco più a trovare velocemente ciò che mi serve. Quali sono le soluzioni allora? Una è quella di dividere la cache in più livelli: il primo, L1, piuttosto piccolo e contenente lo stretto necessario (ciò che si usa, praticamente, sempre). Il secondo, L2, più grande, con quegli “oggetti” importanti ma non indispensabili (per chi non se ne fosse accorto, si sta scivolando verso un parallelismo con chi si mette in viaggio e deve preparare un bagaglio). Volendo possiamo utilizzare anche un terzo livello L3, magari condiviso con altri viaggiatori, molto più grande dei primi due e con quelle cose che possono servire a tutti ma non sono indispensabili per nessuno. In tal modo, è ovvio che se devo trovare qualcosa rischio di doverla cercare sia il L1 che in L2 e, magari, in L3, però il tempo che impiegherò è sempre minore di quello che impiegherei se la dovessi cercare nella ram di sistema. Un altro accorgimento è quello di fare in modo che i livelli di cache contengano il più possibile. Per fare questo, si associano delle aree di ciascun livello con aree del livello successivo e così via fino ad arrivare alla ram di sistema.
Il metodo più semplice è quello della mappatura diretta. In questo modo, ad una determinata area della ram di sistema, ad esempio, può corrispondere una sola locazione di memoria all’interno della cache L3.
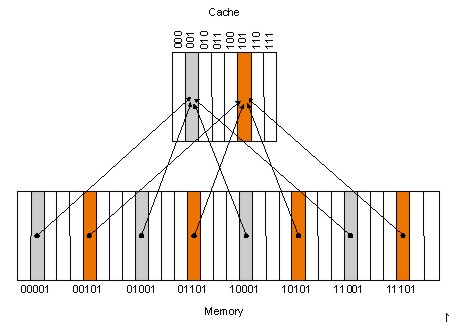
Come si vede dalla figura, il principale problema di una cache direct mapped è che ad una medesima locazione, in cache, corrispondono più locazioni nella main memory che possono essere associate a quella sola locazione. Questo comporta che o si sceglie di realizzare cache di dimensioni molto grandi (e si incorre nel porblema dell’allungamento del tempo di ricerca), oppure si rischia un caso di cache miss a causa di un conflitto di risorse. Se, ad esempio, sia il dato del blocco 01101 che quello del blocco 10101 risultassero necessari ad una determinata elaborazione, uno dei due non potrebbe comunque essere caricato in cache.
Una soluzione è l’utilizzo di modalitù di tipo n-way set associative in cui una stessa locazione della main memory può essere associata a più locazioni in cache (2, 4, 8 a seconda del valore di n). Questo riduce la possibilità di cache miss, soprattutto se si associa alla cache un circuito di branching che preveda i dati e le istruzioni che sarà necessario caricare in cache. Una cache, ad esempio, 4-way set associative si realizza, fisicamente, mettendo insieme due blocchi di cache a mappatura diretta
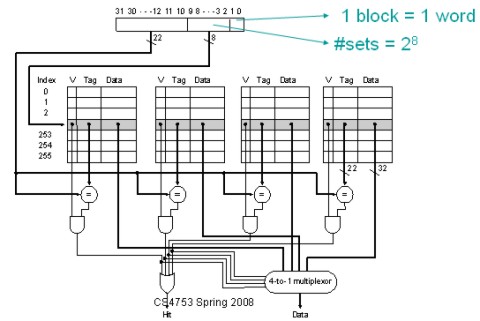
Oltre la cache n-way associative, sempre nell’ottica della riduzione del cache miss penalty, c’è il ricorso alla cache di tipo fully associative, come, ad esempio, la texture cache di R5x0 e di R600 e derivati. Questa, abbinata al solito circuito di branching con relativo algoritmo, azzera, in pratica, il rischio di cache miss ma allunga i tempi di ricerca e presenta un circuito notevolmente più complesso a livello di linee di trasmissione. Una cache fully associative è costituita in modo tale che una locazione della ram di sistema può essere associata a tutte le locazioni della cache.
Solitamente, si ricorre a un livello di cache, tipicamente il più basso, di dimensioni piuttosto generose, in cui si utilizza una modalità fully associative n-way set associative (4-way o 8-way); un livello superiore di cache in cui si fa uso di cache n-way set associative con n minore di quello della cache di livello infeeriore (quindi, ad esempio, una cache L2 12-way set associative ed una L1 fully associative o 4-way set associative). Questo al fine di mediare tra tempi di ricerca e rischi di cache miss penalty. Si tenga conto che, ad esempio, con una cache di 256 KB, tra una 4-way ed una 8-way set associative, la probabilità di cache miss è molto prossima e, di conseguenza, nella scelta della tipologia di associazione giocano un ruolo importante altri fattori tra cui la complessità circuitale.
Questa breve introduzione sulla tipologia di memorie utilizzate in abbinamento con una GPU o con una CPU è servita sia a capire quanto queste abbiano assunto un ruolo, oserei dire, preponderante nell’evoluzione delle prestazioni dei processori, sia a dare un’idea di quanto, parallelamente alla loro importanza, sia cresciuto lo spazio che esse occupano all’interno di un chip. In futuro, scendendo più in dettaglio, si vedrà come siano aumentati di numero, ad esempio, i registri interni di una GPU e le dimensioni delle cache. D’altra parte, non è un mistero che i 10 MB di eDRAM presenti nel die secondario di C1 (il chip grafico dell’x-box360) giochino un ruolo fondamentale nelle elaborazioni grafiche, grazie anche all’ampia bandwidth tra questo frame buffer on chip e le ROP’s. Da quanto scritto, trapela anche l’importanza dell’altro elemento citato in apertura, ovvero i dispositivi e i relativi circuiti di controllo e trasmissione dei dati (arbiter, circuiti di branching, controller, ecc). Ormai non è un azzardo affermare che l’interno di una cpu o di una gpu sia, per un buon 70-75% occupato da circuiti di memoria e di controllo e trasmissione dati (anche i blocchi indicati come, ad esempio, shader core, son, per lo più, occupati da dispositivi e circuiti che servono a controllare il corretto funzionamento delle unità di calcolo, ad effettuare il bilanciamento dei carichi di lavoro. Per rafforzare questo concetto, propongo uno schema dei core di RV770 e di Itanium II

Nel primo si nota il blocco arancione che sono le ROP’s con i 4 MC e gli oltre 5 MB di cache L2 dedicati ai MC. La parte del SIMD core comprende anche i circuiti logici e i vari registri e buffer presenti all’interno delle pipeline. Discorso analogo per il blocco delle texture unit in cui è presente anche una cache L1 di tipo fully associative.
Discorso analogo per la CPU Intel
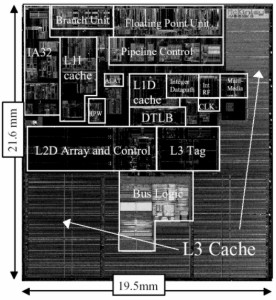
Dove è ancora più evidente il ruolo preponderante, anche a livello di spazio occupato, dalle cache, dall’unità di branching e dalle unità di controllo.







