In questi giorni, mi sono scervellato per tentare di mantenere fede all’impegno preso la scorsa settimana, di parlare di qualcosa di più recente delle matrox G400. Per giorni ho tentato di trovare un argomento altrettanto interessante ma più attuale dell bump mapping e, devo ammettere che le idee erano molte, ma nessuna soddisfacente. Certo, la vittoria di Del Potro nell’ultimo Open USA ha dei risvolti intriganti, mentre l’incoronazione di Maria Perrusi quale Miss Italia 2009 non è esente da un certo fascino; peccato che nessuno dei due eventi sia legato in alcun modo al mondo delle schede video o abbia una qualche attinenza con una rubrica intitolata “Grafica e silicio”.
Per fortuna è, incidentalmente venuto in mio soccorso l’inaspettato (?) lancio delle nuove GPU di casa (ora) AMD (ma ancora ATi per gli aficionados). Ok, lo ammetto, non era esattamente inaspettato; diciamo che… forse qualcuno ne era a conoscenza. E visto che non vi si può nascondere niente, cerchiamo di entrare subito in argomento.
Qualche tempo fa, sul forum di Hardware Upgrade, nell’ambito di una discussione, qualcuno sollevò il dubbio che la serie 4xx0 di ATi (RV770 e derivati) potesse essere DirectX11 full compliant. Quella volta risposi che RV870 non sarebbe stato molto diverso architetturalmente da RV770 ma che delle differenze esistevano ed erano tali da non permettere di affermare che RV770 era un chip DX11. Non è di questo che voglio parlare: un confronto tra le due generazioni di chip lo farò in un altro articolo; quello su cui voglio focalizzare l’attenzione è un dubbio venuto a molti guardando lo schema a blocchi di RV870: si tratta di un chip mono core o di un RV770 x2?
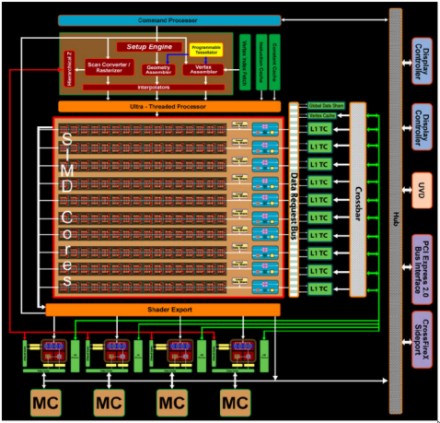
In effetti, se si confronta lo schema a blocchi di RV770
con quello di RV870
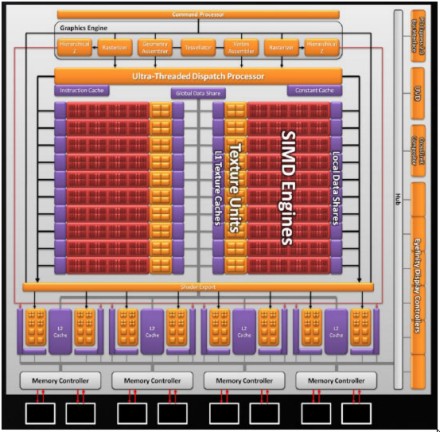
le prime cose che saltano agli occhi, oltre al raddoppio dei cluster SIMD e, di conseguenza, delle ALU e delle TMU, delle Render Back End (RBE) e della relativa cache L2, sono la presenza di un controller per sei uscite video e una apparente architettura dual core. La prima delle due non ha nulla a che fare con le DX11 ma è una peculiarità dei nuovi chip ATi.
In quanto alla seconda, a ben guardare, non si può parlare di due core separati e perfettamente funzionanti indipendentemente l’uno dall’altro, in quanto hanno in comune alcuni elementi, come il vertex assembler, il geometry assembler e il tessellator, oltre al thread dispatch processor ma, rispetto a quella di RV770, presenta delle ridondanze come, ad esempio, il rasterizzatore e l’unità che si occupa delle operazioni di calcolo e analisi dei valori dello z-buffer (hierarchical-z). Si può dire, quindi, che si è in presenza di un ibrido, con parti in comune e parti dedicate a ciascuno dei due blocchi.
A questo punto, ci si potrebbe porre la domanda: per quale motivo non optare per un’architettura dual core?
Innanzitutto si sarebbe assistito allo sdoppiamento di tutte le unità, comprese le RBE che, in RV870, sono, invece, in comune. Cosa avrebbe comportato ciò? Le conseguenza più immediata è che ogni core avrebbe potuto usare solo le RBE ad esso dedicate, mentre con un’architettura come quella di RV870, ognuno dei due blocchi funzionali ha la possibilità di accedere a tutte le ROP’s a disposizione, sfruttando le prime “libere” tramite una connessione di tipo crossbar tra SIMD Engine e RBE.
L’altra questione riguarda il thread dispatch processor e le relative cache (instruction cache e constant cache). Si sarebbe dovuto scegliere se implementare un doppio thread processor ma, in tal caso, la ripartizione dei carichi tra i due core sarebbe avvenuta via software. Ora, un conto è ripartire i carichi di lavoro tra due o più core che sono deputati a svolgere incarichi differenti (ipotesi, uno si occupa della fisica ed uno del rendering), un altro è quello di bilanciare i carichi di lavoro tra due core che si devono occupare della stessa cosa.
Nel secondo caso, l’efficienza raggiungibile è molto minore rispetto a quella teorica, come dimostrano i test delle soluzioni dual gpu o delle configurazioni SLI o Crossfire. In una situazione del genere, la gestione dei carichi di lavoro è sempre opportuno che avvenga in hardware.
In un chip come RV870, pensare di utilizzare un core per la fisica sarebbe stato un inutile spreco di risorse e l’alternativa alla gestione software sarebbe stata quella di avere un unico thread processor (come avviene in RV870, appunto). Da un punto di vista della sostanza, averlo fuori dai due core fisici o all’interno di uno di essi non cambia nulla.
Chiara, dunque, a questo punto, l’opportunità di avere thread processor e RBE in comune. Veniamo alle unità di tipo geometrico, ovvero quelle che si occupano di preparare il lavoro delle unità di vertex shading e di geometry shading. Il vertex assembler, di cui riporto un generico schema a blocchi (nella speranza che si riesca a vedere qualcosa)
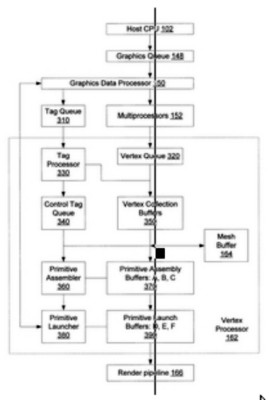
si occupa di ricevere i dati compressi, relativi ai vertici, provenienti dalla cpu, di ordinarli e di inserirli in un buffer per metterli a disposizione delle unità di vertex shading o del tessellator; il geometry assembler svolge un compito analogo con le primitive.
C’è, poi, il tessellator, che, secondo le specifiche DX11, deve essere composto di 3 blocchi funzionali, hull shader, tessellator vero e proprio e domain shader, con il primo ed il terzo programmabili ed il secondo di tipo fixed function. Al tessellator ed alle tecniche di generazione di higher order surface su GPU (dal truform in poi) farò cenno in un prossimo post, per cui non mi dilungo sull’argomento.
Tornando in topic, appare evidente che questi elementi sarebbero potuti essere duplicati senza problemi di gestione dei thread sui due core, ma, di fatto, si tratta di elementi che raramente fanno da collo di bottiglia nel corso dell’elaborazione delle immagini, poichè, per vari motivi (presenza di fixed function, quantità limitata di calcoli da eseguire, ecc), il più delle volte terminano il loro lavoro prima di quanto non faccia, ad esempio, lo shader core che, oltre ad occuparsi delle operazioni di vertex shading, geometry shading e pixel shading, in RV870, contrariamente a quanto avveniva in RV770, si occupa anche delle operazioni di interpolazioni sulle texture. Diciamo che l’avere un doppio stadio di tessellation non avrebbe fatto male, ma, dovendo scegliere (secondo l’antico principio della coperta corta che, in questo caso, si traduce in numero di transistor e die size) si è optato per avere un unico tessellator e qualche unità di shading in più.
Questo perchè, secondo la strategia del “piccolo è meglio”, inaugurata da AMD/ATi con l’architettura di R600 per cui il processo produttivo a 80 nm non era adeguato, però) e proseguita con RV670, RV770 ed RV870, è importante cercare di limitare le dimensioni del die, introducendo delle unità ridondanti all’interno, a livello di cluster dello shader core, per avere rese più alte e, quindi, contenere i costi. C’è da dire, invero, che RV870, con i suoi circa 330 mm^2, da questo punto di vista rappresenta già un mezzo fallimento, soprattutto in considerazione del fatto che AMD si è posta come misura ideale quella di 250 mm^2, da cui si è ben lontani.
Ricapitolando, dunque, ci troviamo di fronte ad un chip con thread processor, tessellator e RBE in comune, ma con due blocchi di cluster SIMD, un doppio rasterizzatore, due distinti circuiti che si occupano di branching e un bus che funge da global data share. Quello che sarebbe interessante capire è se, effettivamente, lo shader core è diviso, in qualche modo, in due parti, oppure quella che appare nelle slide è solo una suddivisione di comodo per una miglior visualizzazione. In realtà, rispetto a RV770, non c’è alcuna rivoluzione architetturale e le slide di inizio pagina traggono in inganno, in quanto l’organizzazione interna dei cluster SIMD di RV770 non è quella presentata in precedenza ma, piuttosto, questa
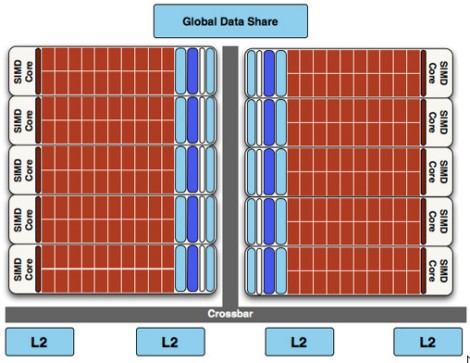
che, come si può vedere, presenta molti più elementi in comune (ad iniziare dal bus che collega gli SP alla cache L2 ed alla global data share mamory) con RV870. Quella che è migliorata nella serie 5xx0 è proprio la gestione dei consumi, ora più efficiente e più simile a quella tipica dei chip multicore; maggiore efifcienza ottenuta, infatti, non solo grazie all’adozione del processo produttivo a 40 nm che, addirittura, nelle prime fasi di sviluppo, aveva creato più di qualche problema proprio a livello di gestione energetica.
D’altra parte si deve anche considerare che per TSMC il passaggio da 55 a 40 nm rappresentava un salto di tipo “full node” con tutti i problemi connessi a questi tipi di passaggi. I minori consumi, infatti, sono dovuti principalmente al fatto che i vari blocchi, tra cui i due gruppi di cluster, sono gestiti tramite l’adozione di voltage island, oltre che attraverso l’uso di più domini in frequenza, ovvero con tecniche piuttosto comuni sui chip multicore ma senza arrivare all’utilizzo del power gating, ovvero allo spegnimento completo dei circuiti non in uso ma a limitandosi a tecniche di clock gating su più zone, ossia alla regolazione dinamica della frequenza applicata a più settori, unita alla regolazione dinamica della tensione per aree del chip.
Grazie a ciò è stato possibile arrivare al risultato che in idle, nonostante i 20 core SIMD i consumi siano prossimi a quelli di RV670 che di core SIMD ne ha solo 4. Quindi, di fatto, si tratta di un chip che, dall’esterno, ovvero dal “punto dei vista” di dati e istruzioni, è visto come un single core, ma che, per alcune cose, come ad esempio la gestione energetica si avvicina di più a quella di un chip multicore e, comunque, rappresenta un punto di discontinuità col passato.
Si può parlare di architettura nata come single ma che aspira, in futuro, a diventare multicore? Probabilmente si; in parte le prove tecniche si stanno già facendo e, in futuro, non è da escludere l’adozione di architetture multicore con core asimmetrici di cui, ad esempio, uno con numero ridotto di cluster SIMD, dedicato alla fisica o un altro alla IA.
La prossima settimana passeremo ad analizzare alcuni altri aspetti del nuovo chip di AMD e vedremo in che modo questo si differenzia dai suoi predecessori e in che cosa è, invece, rimasto invariato. Ci sono tante piccole differenze, non evidenti dall’analisi dello schema a blocchi proposto, che rendono RV870 diverso da RV770 e quest’ultimo non DX11 fully compliant. Paradossalmente, il tessellator che appare la più evidente delle differenze tra i due chip è, invece, uno degli elementi il cui funzionamento meno si discosta, a livello funzionale, nel passaggio da una generazione alla successiva e l’incompatibilità con le DX11 è dovuta solo all’assenza dei due blocchi programmabili (hull shader e domain shader) che in RV770 sono surrogati, rispettivamente, da vertex shader e geometry shader. Ben maggiore, a livello di funzionalità integrate, invece, il passaggio dai compute shader 4.1 (delle DX10.1) ai 5.0 delle DX11, come pure tante le ottimizzazioni “sotto la scocca” che rendono RV870 più efficiente di RV770.
Un ultimo appunto: nonostante il gran lavoro di ottimizzazione sul memory controller, l’ampliamento del thread local store (TLS) e gli avanzati algoritmi di compressione, il bus a 256 bit inizia a manifestare alcuni limiti, almeno con le applicazioni attuali; vedremo cosa avverrà con applicazioni DX11 che dovrebbero supportare le atomic operation ed altre ottimizzazioni atte a far risparmiare banda passante.
Ma di questo e altro parleremo in futuro.







