
Dopo aver discusso i vantaggi generali, e in particolare riguardanti la densità di codice e il numero di istruzioni eseguite (argomenti affrontati nel precedente articolo), diamo un’occhiata alle innovazioni che NEx64T porta rispetto a x86 e x64.
Le istruzioni general-purpose / intere / scalari
Cominciamo col dire che l’architettura è per lo più ortogonale, per cui praticamente tutte le istruzioni sono strutturate allo stesso modo (come abbiamo anche visto nel secondo articolo), possono utilizzare le stesse modalità d’indirizzamento, e si può specificare una qualunque dimensione per i dati (da 8 a 64 bit: Byte, Word, Long, Quad).
Il vantaggio, in questo caso, è che i compilatori sono più semplici da realizzare, perché non devono tener conto di casi particolari e la generazione del codice risulta più facile. Il che risulta ancora più importante nel caso in cui si debba necessariamente scrivere codice in linguaggio assembly, oppure facendo uso di intrinsic, poiché sono i programmatori (esseri umani!) a doverlo fare.
Ciò significa che istruzioni come POPCNT, che su x86 / x64 possono gestire dati soltanto di alcune dimensioni (16, 32, e 64 bit, nello specifico), possono lavorare, invece, con qualunque dimensione (quindi anche 8 bit). Un altro esempio è ADCX, che su x86 / x64 lavora soltanto con dati a 32 e 64 bit, mentre su NEx64T può farlo anche con dati a 8 e 16 bit.
Com’è possibile intuire, sono state introdotte anche alcune nuove istruzioni, le quali consentono di accelerare l’esecuzione di compiti abbastanza comuni, che elenco brevemente:
CCMPcceCTESTccper ottimizzare la generazione di flag nella valutazione di condizioni booleane (più dettagli nell’apposito articolo diAPX);- generazione di maschere di bit (tutti i bit sono
1oppure a0, a seconda della condizione testata oppure del confronto di due operandi) oppure di flag booleani (valore0oppure1a seconda del confronto di due operandi); PUSH/POPdi più registri su/dallo stack, con eventuale aggiunta di spazio per variabili locali;- salto condizionato sulla base del contenuto di un registro oppure del confronto fra due registri;
- chiamate o salti a metodi (usando tabelle VMT “compatte”);
- chiamate o salti a tabelle di funzioni (“compatte”. Per istruzioni switch/case).
Si tratta di poche istruzioni, ma che possono fare la differenza in termini prestazionali e/o di spazio occupato in memoria (anche da dati), diverse delle quali si posso trovare in maniera similare anche su altre architetture (incluse le L/S = Load/Store. Gli ex-RISC).
Estendere le istruzioni
Un’altra peculiarità della nuova architettura è che le istruzioni (non tutte. Ad esempio non quelle “compresse”, che occupano meno spazio) possono essere estese in modo da acquisire nuove caratteristiche. Si tratta di roba in parte già vista con x86 / x64, ma che qui subisce una particolare evoluzione che consente di arricchire il funzionamento delle istruzioni.
Un diagramma consente di comprendere meglio di cosa si sta parlando (oltre a presentare una nuova sintassi per le istruzioni):
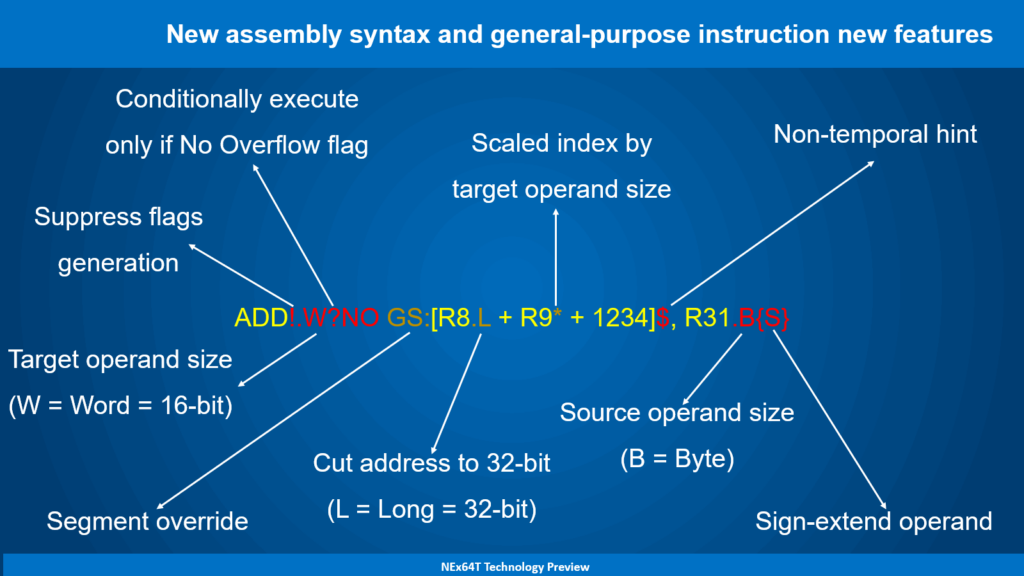
Sono state evidenziate in giallo l’istruzione (ADD) e tutte le sue normali parti di cui è composta. In arancione, invece, sono evidenziate le seguenti funzionalità, presenti anche in x86 / x64 (con qualche leggera differenza per l’ultima funzionalità):
- utilizzo di un segmento diverso (
GS) per referenziare la memoria, anziché quello di default (DSoSS. Il secondo viene utilizzato quando il registro base èSPoBP). Su x86/x64 si deve utilizzare il prefissoGS. - troncamento di un indirizzo da 64 a 32 bit (
.L), oppure da 32 a 16 bit. Su x86 / x64 si deve usare il prefisso67(in esadecimale); - utilizzo dell’indice scalato in base alla dimensione dell’operando. Su x86 / x64 la dimensione è fissa e coincide con quella dell’operando di destinazione; inoltre l’indice viene scalato in base a uno dei quattro valori fissi selezionabili (1, 2, 4 oppure 8). Su NEx64T, invece, è possibile scalare l’indice esclusivamente in base alla dimensione dell’operando di destinazione (quindi di un fattore 2, in questo caso).
Fino ad ora si tratta di ordinaria amministrazione, poiché si tratta sostanzialmente di quanto già possibile con x86 / x64, per l’appunto.
Le cose cambiano con le nuove funzionalità, evidenziate in rosso, le quali sono di esclusiva pertinenza di NEx64T:
- soppressione della generazione dei flag (
!) nelle istruzioni che li generano. Viceversa, i flag vengono forzatamente generati nelle istruzioni che, invece, non lo prevedono. Ad esempio,MOV!eseguirebbe la normaleMOV, ma imposterebbe i flag confrontando con zero il dato copiato; - definizione della dimensione del dato della destinazione (
.W). Normalmente ciò è già possibile ed è implicito con x86 / x64, ma assume un significato diverso quando viene specificata una dimensione anche per l’operando sorgente (vedi sotto); - esecuzione condizionale dell’istruzione (
?NO), soltanto quando non risulta impostato il flag di overflow. L’istruzione, quindi, non viene eseguita se il flag di overflow risulta impostato (in questo specifico caso. Ma è possibile selezionare 15 delle 16 condizioni disponibili per x86 / x64); - i dati letti e/o scritti dall’istruzione non vengono memorizzati in nessuna cache (
$) del processore. Le quali, quindi, non vengono “inquinate” (togliendo spazio ad altri dati già memorizzati) da dati che non è utile conservare; - definizione della dimensione del dato della sorgente (
.B). Viene usato in combinazione con la definizione della dimensione del dato della destinazione (vedi sopra) e della modalità di estensione del dato (vedi sotto); - selezione della modalità di estensione del dato sorgente con segno (
{S}) oppure con zero ({Z}. Normalmente è implicito e non serve specificarlo. Lo si riporta qui soltanto per completezza). In quest’esempio il byte meno significativo del registroR31viene esteso con segno e sommato alla word (16 bit) referenziata in memoria.
Si tratta, come si può vedere, di funzionalità molto comuni che richiedono, in assenza del meccanismo di estensione messo a disposizione da NEx64T, l’esecuzione di una o più istruzioni (per ogni specifica funzionalità utilizzata / abilitata) per emularne il funzionamento, e in alcuni casi anche di qualche registro di appoggio per il calcolo di valori intermedi / temporanei.
Questo meccanismo rappresenta quella che, a mio modesto avviso, si potrebbe classificare come la quintessenza dei CISC: poter eseguire più “lavoro utile” in una singola istruzione.
Il che va tutto a vantaggio del numero di istruzioni eseguite (che si riduce, ovviamente) e, spesso, anche della densità di codice (meno spazio occupato grazie al fatto di eseguire meno istruzioni), con conseguenti, benefiche, ricadute in termini prestazionali e di consumi del processore.
Istruzioni polimorfiche
Continuando su questa scia, NEx64T ne sublima il concetto introducendo le istruzioni polimorfiche, che rappresentano un’ulteriore estensione delle istruzioni che potremmo definire “di base”, le quali assumono nuove “forme”, per l’appunto.
L’idea è quella di astrarre il funzionamento di un’istruzione, pensandola semplicemente come un oggetto che riceva uno o più dati in ingresso, li elabori in un certo modo, per poi fornirne il risultato finale. Da dove arrivino questi dati e dove finisca il risultato non è rilevante né vincolante per l’istruzione, perché ci penserà il processore: lei deve soltanto occuparsi di fare i calcoli che le sono stati richiesti.
Questa generalizzazione delle istruzioni ha consentito di plasmare più formati coi quali le istruzioni sono messe a disposizione, come si evince dalla seguente tabella:

Prendendo sempre la celeberrima ADD, possiamo vedere come questa sia utilizzabile in diverse forme rispetto alla prima, la quale è l’unica disponibile con x86 / x64. Infatti con quest’ISA è possibile specificare soltanto due argomenti, dove il primo funge sempre sia da destinazione sia da prima sorgente; inoltre uno dei due dev’essere sempre un registro.
Invece il secondo formato dell’elenco qui sopra mostra come sia possibile referenziare due elementi in memoria (quindi utilizzando una qualunque modalità d’indirizzamento per ciascuno di essi), mimando uno dei più famosi rappresentanti della macrofamiglia dei CISC: il VAX di Digital.
Il terzo è un formato comune in parecchi processori L/S, dov’è possibile specificare ben tre argomenti per l’istruzione, sebbene questi debbano essere tutti e tre dei registri. Questo perché il formato utilizzato in questo caso è quello “compatto” (gli opcode occupano 32-bit. Come buona parte dei L/S).
Problema che viene risolto già col quarto formato, il quale consente di referenziare una locazione in memoria per il terzo argomento (ossia la seconda sorgente in ingresso). Il primo e il secondo devono sempre essere dei registri, comunque.
Il quinto, il sesto e il settimo formato sono, invece, una generalizzazione del quarto, in quanto consentono di referenziare ben due elementi in memoria, mentre uno deve sempre essere un registro. In questi casi i tre formati si differenziano soltanto sulla posizione dell’unico registro (quindi quale dei tre argomenti dev’essere).
L’ultimo formato, infine, rappresenta la generalizzazione del concetto di istruzione ripetuta in x86 / x64, che con questi processori era vincolata soltanto ad alcune di esse, mentre NEx64T consente di specificare una qualunque istruzione “di base”.
In questo caso l’operazione viene ripetuta un certo numero di volte (specificato nel registro RCX) e i tre operandi possono essere liberamente dei registri o delle locazioni di memoria (ma soltanto con poche modalità d’indirizzamento utilizzabili). Di questo, però, ne parleremo meglio in un successivo articolo.
Quanto illustrato per le istruzioni binarie (le quali prendono due argomenti e ne restituiscono un altro come risultato) vale anche per quelle unarie, le quali in questo caso hanno anche il vantaggio di poter avere entrambi gli operandi (sorgente e destinazione) in memoria.
Ad esempio l’istruzione NOT, che su x86 / x64 ha un solo argomento usato sia per la sorgente sia per la destinazione, si può adesso utilizzare anche in questo modo:
NOT.L [RBX + RDX* + 1234], [RBP + RCX* + 5678]
dove viene effettuata la negazione dei 32 bit contenuti in [RBP + RCX* + 5678] e il risultato memorizzato poi in [RBX + RDX* + 1234].
Penso sia evidente come questa nuova architettura consenta un’enorme flessibilità nonché efficienza, in quanto una singola istruzione in uno dei suddetti formati consente di rimpiazzarne anche più d’una per emularne il funzionamento, a tutto vantaggio sempre delle prestazioni (meno istruzioni eseguite), della densità di codice (una sola istruzione ne rimpiazza due o più), e dei consumi.
Con ciò possiamo dire che NEx64T si spinge ancora di più nella tradizione dei CISC, codificando molto più “lavoro utile” in una singola istruzione e richiamando in buona parte il già menzionato VAX, il quale consentiva, però, di compattare meglio lo spazio di istruzioni complesse come queste, ma pagando l’elevato prezzo di una decodifica nettamente più difficile e inefficiente (cosa che non avviene con NEx64T, come abbiamo già visto in uno dei precedenti articoli).
Il confronto con APX di Intel…
Di APX abbiamo già parlato in una recente serie di articoli, i quali esplorano le novità introdotte da Intel con questa nuova estensione (che in realtà, e per quanto già sviscerato, si può considerare come una nuova architettura).
Anche APX porta, quindi, delle innovazioni, ma rappresentano soltanto alcune piccole aggiunte rispetto a quanto introdotto da NEx64T. Infatti si limitano soltanto alle seguenti:
- nuove istruzioni
CCMPcceCTESTcc, e istruzioniCMOVccpiù generali (senza necessariamente sollevare eccezioni). NE64T consente, invece, di eseguire condizionatamente qualunque istruzione “di base” (similmente ad alcune architettureL/S. Ad esempio ARM); - nuove istruzioni
PUSH/POPdi soli due registri (e niente aggiustamento dello stack per riservare ulteriore spazio); - soppressione della generazione dei flag soltanto per alcune istruzioni e non per tutte quelle li generano. Inoltre non è possibile “invertire” il processo: generare flag per le istruzioni che non lo fanno;
- le istruzioni binarie che adesso usano tre argomenti possono e devono avere soltanto un registro per la destinazione. Idem per quelle unarie che hanno due argomenti (la destinazione dev’essere sempre e soltanto un registro).
Si tratta di buone innovazioni, senz’altro, ma sono di gran lunga più limitate rispetto a quanto offerto da NEx64T, che in confronto ad APX è un ricco sovrainsieme proprio (superset).
Entrambe le nuove ISA estendono il numero di registri general-purpose da 16 a 32, ma APX ha un prezzo molto salato da pagare: deve far ricorso ad appositi prefissi che fanno lievitare anche molto la dimensione delle istruzioni, come abbiamo visto nell’apposito articolo che ne trattava la densità di codice.
NEx64T, invece, ha una struttura ortogonale e in genere non subisce alcuna penalizzazione nell’uso di uno qualunque dei 32 registri, avendo cura che i registri vengano utilizzati in maniera opportuna (esistono istruzioni “corte” che operano soltanto su precisi loro sottoinsiemi). Il che è particolarmente vero se si usa l’apposita ABI che è stata definita.
…e con la vecchia FPU x87
Infine c’è da considerare anche la vecchissima FPU x87 che, pur essendo obsoleta (ha soltanto 8 registri dedicati), viene ancora utilizzata in quanto ha il vantaggio non indifferente di poter lavorare con numeri in virgola mobile a precisione estesa (80 bit), mentre le altre FPU (a parte quella della gloriosa famiglia Motorola 68000, che funziona in maniera simile) mettono a disposizione al massimo la precisione doppia (64 bit).
In questo caso non aveva senso estendere ulteriormente quest’unità di calcolo, in quanto considerata deprecata (le linee guida consigliano di utilizzare almeno l’estensione SSE2). Quindi non sono stati aggiunti ulteriori registri, sebbene fosse possibile.
L’unica cosa che avrebbe ancora avuto una sua utilità sarebbe stata quella di dare la possibilità di utilizzarla in maniera più moderna e pratica, facendo sì che le sue istruzioni potessero accedere direttamente ai registri, anziché operare solamente come una macchina basata su stack.
Quindi, e per fare un esempio pratico, non è più necessario eseguire due istruzioni per caricare sullo stack i valori e infine eseguirne una terza che si occupa di “consumare” i due valori (che sono in cima allo stack, per l’appunto), effettuare concretamente l’operazione (di somma, ad esempio), e infine depositarne il risultato nello stack (sempre in cima).
NEx64T consente, invece, di eseguire tutto in una sola istruzione, se gli operandi sono tutti direttamente indirizzabili. Quindi non c’è alcun problema se si trovano tutti nei registri dell’FPU o al massimo con due argomenti in memoria (e un registro), similmente a quanto abbiamo già visto con le istruzioni polimorfiche (binarie e unarie).
Il vantaggio è chiaramente prestazionale, ed in genere è soltanto quello il vantaggio che si ottiene, poiché i nuovi formati delle istruzioni x87 occupano più spazio in memoria: è difficile fare di meglio in termini di densità di codice (l’FPU x87 è veramente molto compatta!), ma senza dubbio alcuno si può fare di gran lunga meglio in termini prestazionali (e, soprattutto, senza troppi mal di testa per chi debba ancora lavorarci).
Conclusioni
Con ciò si conclude la panoramica generale della nuova architettura, limitatamente alle istruzioni general-purpose e alla vecchia FPU.
Il prossimo articolo si concentrerà, invece, sulle modalità d’indirizzamento messe a disposizione, le quali portano un bel po’ di carne al fuoco e chicche che consentono di migliorare notevolmente ciò che è possibile fare con le istruzioni che referenzino la memoria.
Ma… non soltanto la memoria! NEx64T, infatti, va ben oltre quanto consentito / codificato da x86 e x64, a tutto vantaggio della densità di codice, dello spazio occupato in memoria per i dati, e quindi ancora una volta con positive ricadute sulle prestazioni e i consumi…







