
The benefits of a simple opcode structure were illustrated in the previous article for the new NEx64T architecture, but enabling efficient decoding, important as it is, is only one of the factors that characterise an architecture and can certify its “goodness”.
Code density
Another, which we have discussed extensively in these pages (particularly in this article), is that of code density, which plays a major role, since it affects the entire memory hierarchy and, consequently, performance and consumption.
The aim, in this case, is to make applications take up as little space as possible. This translates into two factors to which it is directly related: the (average) instruction size and the number of instructions executed.
One can, therefore, think of reducing the size of instructions, but one must also be careful not to increase the number of instructions executed, on pain of the opposite effect (more instructions means more space occupied by them).
Therefore, the ideal would be to try to achieve a good balance between these two factors, so that their combination results in a smaller space overall (compared to other reference architectures).
The length of instructions
Obviously, this all depends on how the opcodes have been structured and what functionality (i.e. the “useful work” being done) is implemented in the instructions. Concerning the former, we have already briefly seen something in the previous article and will add more at the end of this one, while for the latter we will see more in a separate article (because there is more to say).
Now, instead, let’s look at some numbers that give us an idea of how NEx64T is in terms of instruction length, showing it with its two benchmarks (x86 and x64, for 32-bit and 64-bit code respectively) and the work done by a Python application that disassembled a certain number of instructions from some applications (Appendix A shows the numbers) for the two architectures and converted them into the NEx64T equivalents, making some optimisations (where possible).
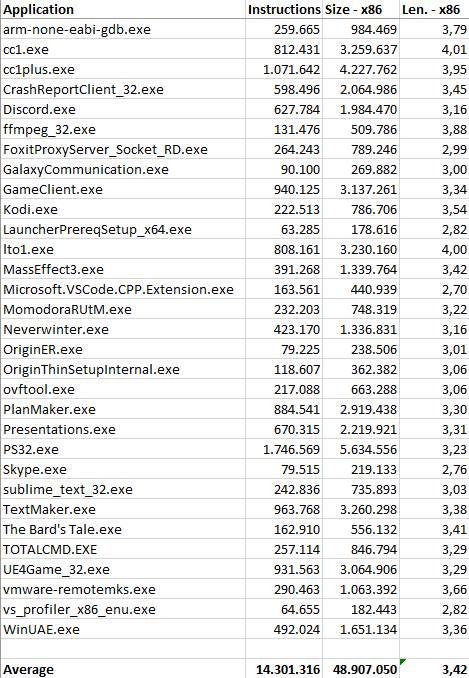
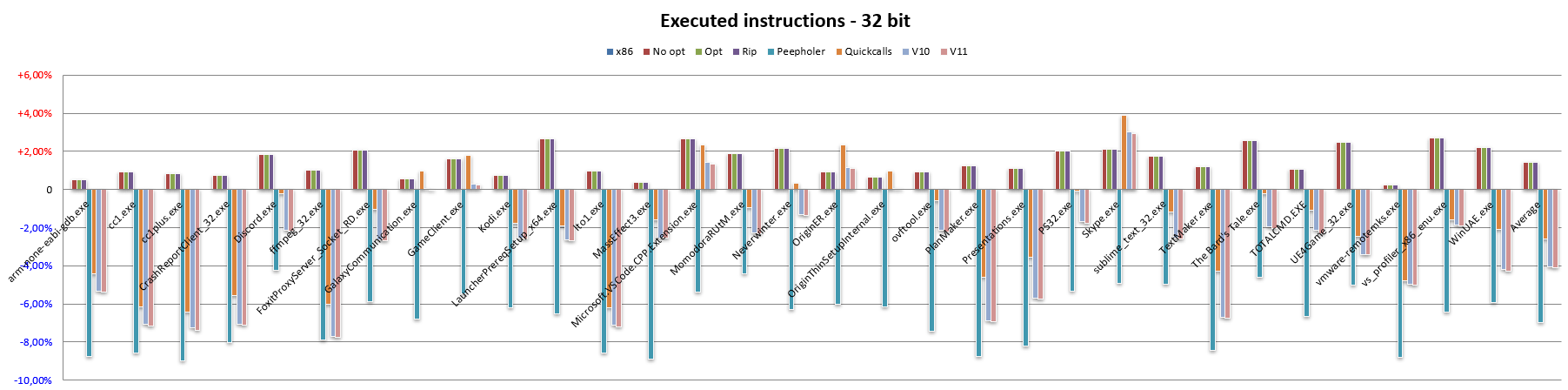
Let us start with the 32-bit code (compared, of course, with x86):
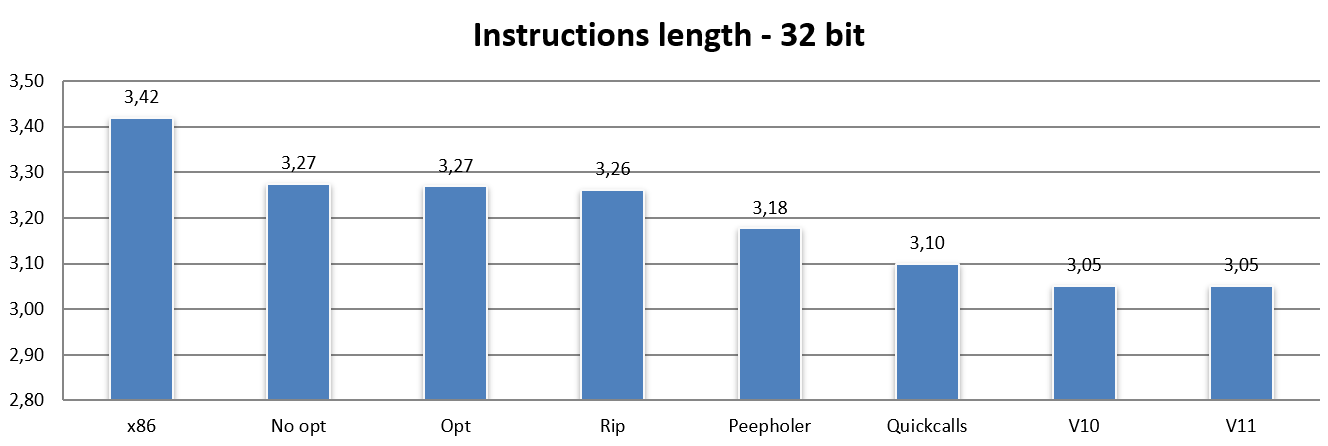
The x86 bar is of course the average length for this architecture, which stands at 3.42 bytes per instruction (this is with the set of applications used and the number of instructions we were able to disassemble).
No opt reports the exact translation of an x86 instruction into one (or more, in more complex / legacy cases) of NEx64T (specifically of v9: the ninth version I made), without performing any optimisation or using any special feature of the new ISA.
For example, x86 uses only 8 registers, and the same is done for NEx64T (with the exception of a few cases, which we will see more about in a separate article on purely legacy issues). Furthermore, no new instructions, no new addressing modes, and no new SIMD / vector / instruction block modes are used.
With No opt, one can already see how NEx64T manages to do on average better than x86, even with the latter being quite well-known and renowned for having a very good code density.
It must be said that x86 also performs so well thanks to the ABI adopted, which provides for the passage of few parameters in registers for function calls. A forced choice in any case, considering that there are only eight available (one of which is also the pointer to the stack).
This involves pushing any other parameters onto the stack, as well as the very frequent use of push and pop of registers onto/from the stack when it is necessary to free up and use some registers for operations.
Since the PUSH and POP instructions occupy only one byte on x86, this explains why this architecture achieves such good values with regard to code density. NEx64T, on the other hand, is at a disadvantage here, as the minimum instruction length is two bytes, so the very large number of PUSH and POP instructions take up twice as much as on x86, after translation.
Switching to the Opt bar, no change is noticeable. Only a few very simple optimisations are made here, such as converting an AND MemoryLocation,0 instruction to MOV MemoryLocation,0 or OR MemoryLocation,-1 to MOV MemoryLocation,-1, and AND MemoryLocation,-Immediate to SUB MemoryLocation,-Immediate, because they take up less space with NEx64T.
A very slight improvement is seen with the Rip bar, although it is insignificant (barely a penny). The only change made here concerns the conversion of 32-bit absolute addresses into the equivalent PC relative addresses (RIP addressing mode, which does not exist in x86 and is only available on x64), which saves something in cases where the referenced location is close enough.
The Peephole Optimiser at work
A more substantial part comes from the introduction of a peephole optimiser (called Peepholer in the graphs), which takes care of analysing x86 or x64 instruction pairs and eventually converting them into a single NEx64T instruction. Only a few examples, among the most common, are given in Appendix E for purely representative purposes, to give an idea of how it works.
This already serves to demonstrate the further potential of the new architecture, thanks to the new instructions and/or addressing modes it makes available. Unfortunately, by analysing only two instructions at a time, not much can be done, for three reasons:
- the original compiler “reordered” the generated instructions, so as to reduce dependencies between them and thus optimise their execution (which is crucial in in-order architectures, for instance);
- it would have been possible to use two different addressing modes in the same instruction, which however generated 3 or more instructions in the code;
- it would have been possible to make use of extended functionality, such as loading values with sign or zero extension, but the generated code is 3 or more instructions.
Appendix F shows a list of code snippets (just a few, again purely representative) found in some of the disassembled applications, showing what could have been done (replacing two, three or four instructions with just one) and the still unexpressed potential of NEx64T, which can undoubtedly contribute to improving code density and performance even further.
Another major problem that has greatly affected code density is that relating to the prologue and epilogue of functions, which often make abundant use of the aforementioned PUSH and POP instructions to save registers on the stack and then restore them at the end of their use.
These are lists of several instructions (well over two!), which clearly the peephole optimiser, as it works and was structured, could certainly not handle normally.
Fortunately, these are often identical sequences of instructions, which are systematically repeated in the same way, so it was quite easy to intercept a number of predetermined sequences (64 in total) without completely disrupting the current peephole optimiser setup.
The result of this work is shown by the Quickcalls bar, which reports another substantial reduction in average instruction length and, thus, a clear benefit in terms of code density. However, it is not all doom and gloom, as will be shown later, when the issue of the number of executed instructions is addressed.
NEx64T versions 10 and 11
After completing work on the ninth version (v9) of the architecture, there was an opportunity to rework the project due to a few ideas that came up that deserved to be implemented in NEx64T, as evidenced by the v10 bar.
These are some changes to the opcode structure and a few new “compressed” instructions (equivalent to a longer instruction), but a lot of work was done in the peephole optimiser, which was able to handle several other cases and some very common ones.
For example, on several occasions/recurring patterns, it was possible to completely get out of the way the MOVZX and MOVSX instructions, which extend with zero or sign a datum smaller than the length of the register.
With NEx64T there is the possibility of realising this operation as an integral part of any instruction (whose operation / behaviour has been “extended”‘), at the price of using somewhat longer opcodes.
This is not always applicable (or, rather, not always desirable), as the new instruction may require more space than the two x86/x64 instructions it is supposed to replace, so one has to see specifically how to proceed.
In these cases, I have always chosen not to increase the space occupied rather than reduce the number of instructions executed. So all the optimisation data shown in the various graphs is always intended to favour the size of the code (compilation by “size” instead of “speed“, in jargon).
In any case, the results obtained turned out to be quite good. While the same cannot be said with the next version, v11, as can be seen from the relevant bar.
The reason for this is that the eleventh version mainly saw a reorganisation of the opcodes, getting some legacy x86/x64 stuff out of the way, similar to what Intel proposed with its future X86-S architecture (which we talked about in this article — it’s in Italian), and recycling the space for some other improvements (which are not visible as far as instruction length is concerned).
64-bit instruction length
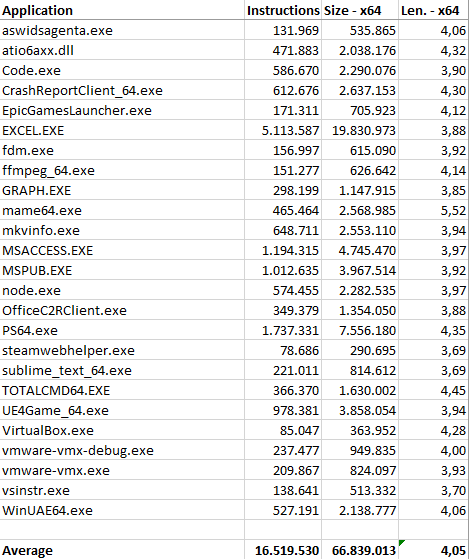
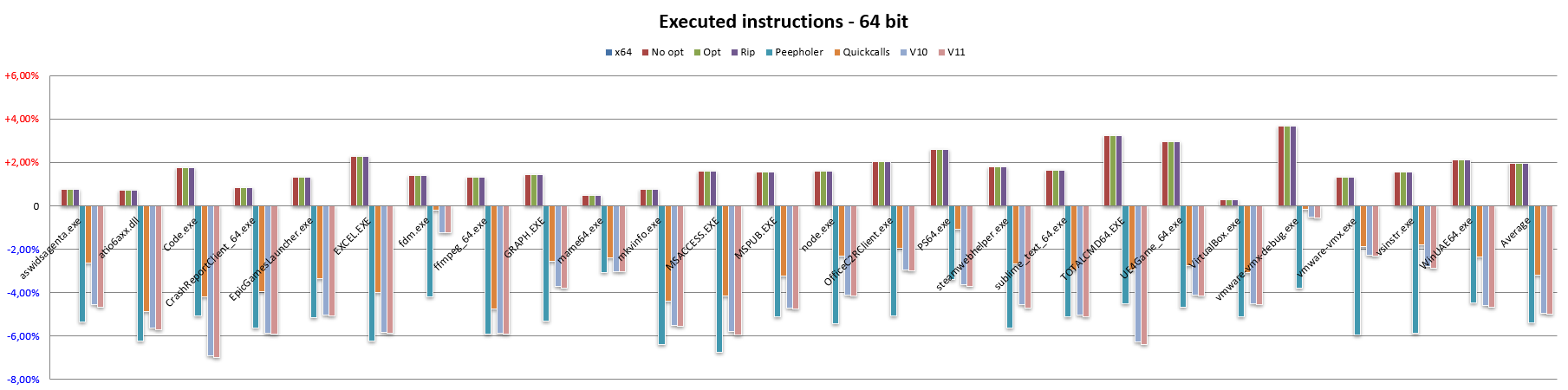
Having finished with 32-bit code, let us now see how NEx64T behaves with 64-bit code (and thus against the x64 architecture):
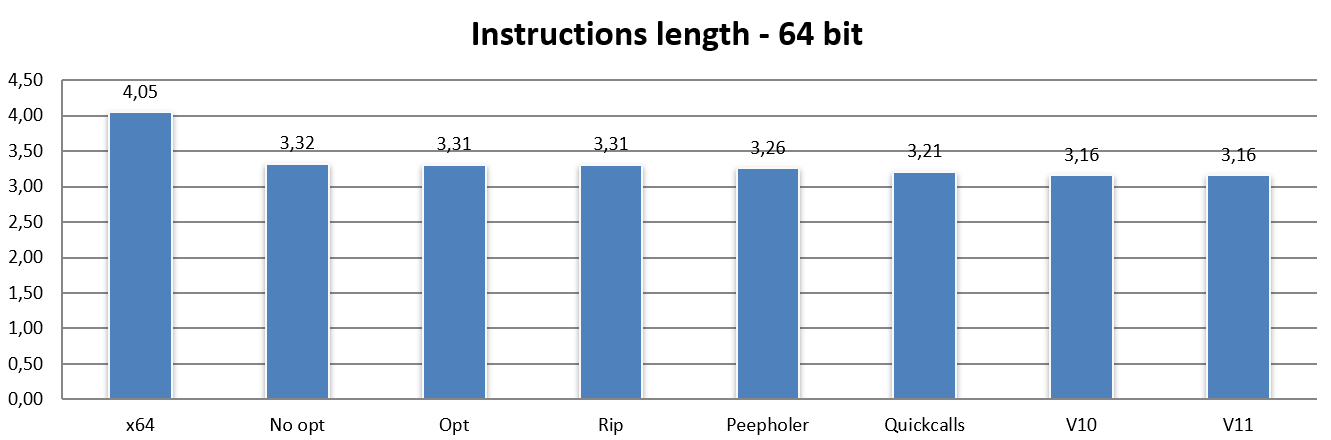
In this case, we immediately see that even the very trivial literal translation of x64 instructions into the NEx64T equivalents (or a few more, in certain more complex / legacy cases) results in a drastic reduction of the average instruction length.
Which is also an expected result, considering that the opcode structure of this architecture is basically the same for 32-bit and 64-bit code, with only a few slight differences. In this case, the slightly different results are almost exclusively attributable to the fact that x86 has a stack-based ABI, as already discussed when talked about PUSHs and POPs, whereas x64 is register-based. So they use different instruction mixes for function calls, hence the differences.
Micro-optimisations have very little effect, as can be seen from the Opt bar, and the same applies to the Rip bar (also obviously expected, since there are no absolute 32-bit addresses to convert in RIP mode: all addresses are already relative to the PC!).
Similarly to the 32-bit code, the Peepholer bar shows a significant reduction in instruction length, and the same applies to the Quickcalls bar, although in both cases the same benefits are not achieved as observed when switching from x86 to NEx64T, while switching to v10 and v11 shows the same decreases in the respective bars as previously observed.
Appendix B provides more detailed data on instruction length, broken down for the individual applications used.
Number of instructions executed
Turning now to the other important metric mentioned at the beginning of the article, a somewhat similar behaviour (but with necessary distinctions) is also found in the number of executed instructions.
In particular, for 32-bit code (again referring to x86):
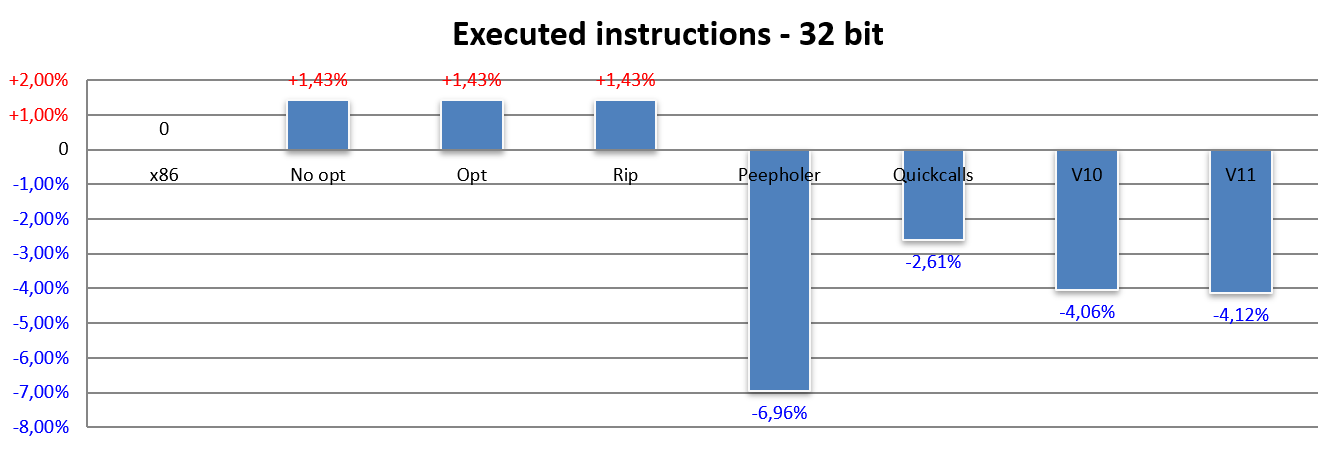
Here the thing that immediately jumps out at you is the fact that all three bars No opt, Opt and Rip report exactly the same result: an increase of just under 1.5% in the number of instructions executed. This occurs due to the more complex/legacy cases of x86, which require more than one instruction to be emulated by NEx64T.
I am referring in particular to:
- use of the 8-bit “high” registers (
AH, BH, CHandDH), which are still used (although very little, fortunately), despite being a legacy of the 8086; - indexed and scaled memory addressing modes.
NEx64T does not even possess the concept of a “high” register, so that in order to faithfully emulate its operation, it needs two or even three additional instructions that carry out the necessary rearrangements of the data before it can execute the actual instruction, putting the data back in place immediately afterwards.
With regard to indexed and scaled mode, however, the difference lies in the fact that NEx64T only supports scaling based on the size of the manipulated data, whereas x86 and x64 allow the selection of any of the four scaling factors made available: 1, 2, 4 or 8 (for data ranging from 8 to 64 bits).
So if 8-bit data is read or written, the scaling will be 1, while it will be 2 for 16-bit data, etc.. It is interesting to note that SIMD/vector instructions have very large registers, so on NEx64T scaling will be proportional: for 512 bit registers it will, in fact, be as many as 64 (while on x86/x64 the maximum selectable will be 8, as already mentioned).
This is a choice dictated by the reduced space available in the word (of 16 bits) that allows any addressing mode to be specified when referencing memory. Two extra bits would have been needed, which obviously were not there (unless the opcode structure was further complicated, losing several of its advantages).
In my opinion, this is a good compromise (which should coincide with the very nature of memory access requests), the merits of which clearly outweigh the three special cases which are not directly supported and which require, for their emulation, the execution of an additional instruction (hence the slightly worse numbers compared to x86).
There would be the case of the reduction of addresses from 64 to 32 bits and from 32 to 16 bits, which are provided for by x64 and x86 respectively, but which were never encountered in the analysed code. In any case, the handling of this particular case would also have involved the execution of an additional instruction.
The Peepholer bar, on the other hand, reports a marked improvement over x86: almost 7% fewer instructions executed, which also compensates for the previous increase of 1.5%. This means that it was possible to identify several pairs (8.5%, in fact) of x86 instructions that were “merged” into a single NEx64T instruction.
Unfortunately, much of this advantage is lost when support for prologue and epilogue functions is introduced, as is clearly visible with the Quickcalls bar.
Fortunately, the v10 version made up for quite a bit of this loss, while it is interesting to note that, at least with regard to the number of executed instructions, v11 also makes a small contribution.
A similar situation occurs for 64-bit code (again compared to x64):
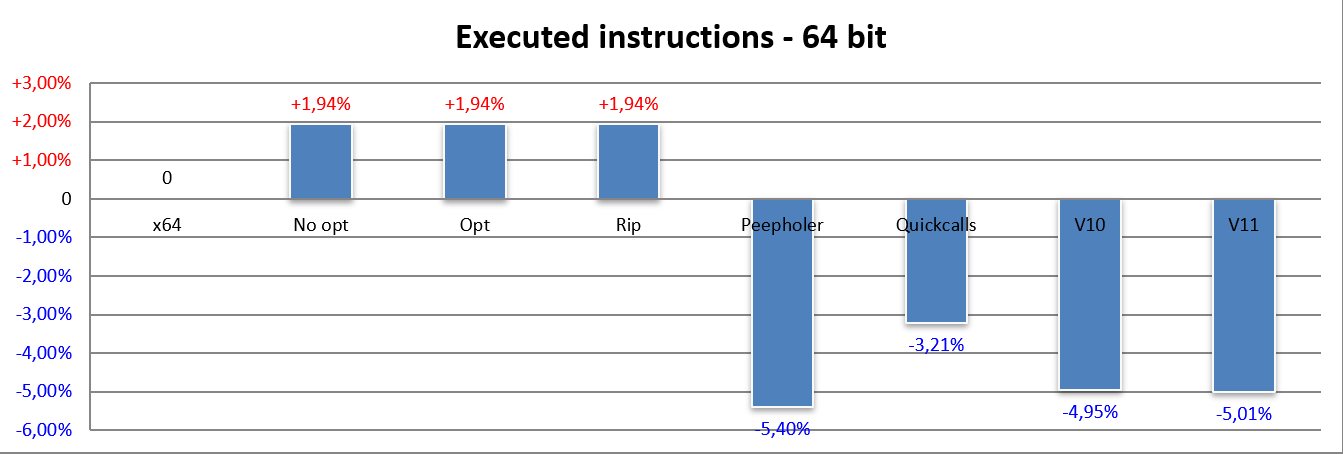
In this case, the impact of the more complicated/legacy cases is a little more substantial (we are at 2% now, as opposed to the previous 1.5%), which may seem absurd considering that x64 is a more modern architecture than x86 and has also removed some legacy.
The explanation is due to the fact that there is an increase in the occurrences where the aforementioned scaled indexed mode is used, relative to the three cases that are not implemented in NEx64T, hence the results.
The contribution of the optimiser with respect to the 32-bit code is reduced, as shown by the Peepholer bar, although it comes to a respectable 5.4 per cent. On the other hand, the impact of Quickcalls was less, and this made up for some of what would normally be lost, probably because the ABI has changed (compared to x86) and less use is made of the stack.
Finally, the switch to the v10 version of the ISA makes its weight felt in a fairly similar way, and the same can be said of the contribution of the v11 version.
Here too, more complete data broken down for the individual applications used can be analysed in Appendix C.
Distribution of instructions
Having finished the analysis of the two most important metrics that are used when talking about computer architectures, I will also provide some statistics that may be of interest to computer enthusiasts and scholars by showing graphs on the distribution of instruction opcodes according to their length.
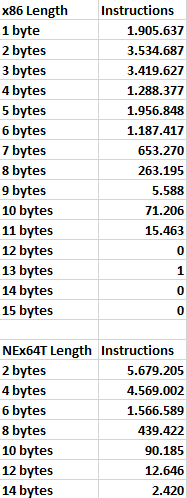
Let us start with x86 (and, therefore, 32-bit code):
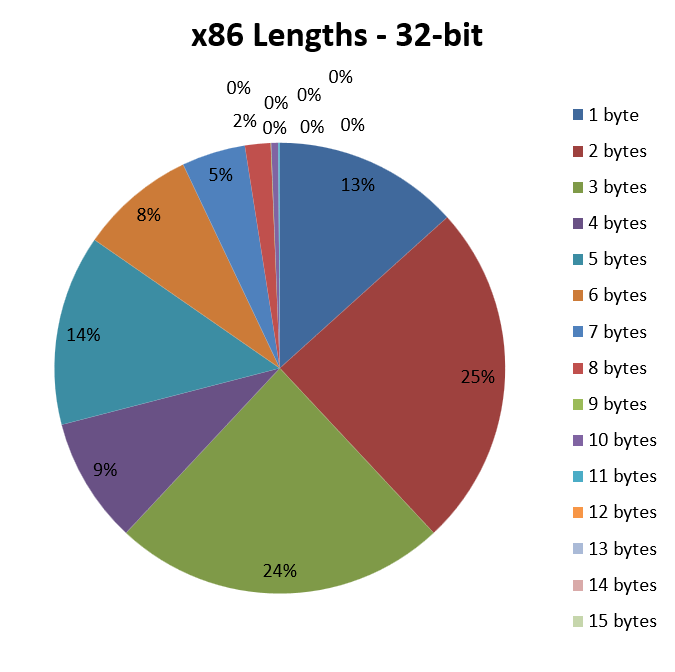
As can be seen, the lion’s share is taken by opcodes two or three bytes long, which are present in 25% and 24% of the disassembled and analysed instructions, respectively. Read another way, this means that about 50% of the instructions have an average length of 2.5 bytes.
Also very important are opcodes consisting of only one byte, which take up no less than 13% of the cake, and which also contribute to bringing down the average instruction length somewhat.
By contrast, 14% of opcodes are a full five bytes long. Which means that, putting one-byte and five-byte opcodes together, almost 30% of instructions have an average length of 3 bytes, which is still a very good value.
Unfortunately, it is all the other cases that remain that raise the bar, until we reach the 3.42 byte average instruction length, which is still a flattering result, for which x86 is also famous (it has a good code density, in fact).
Moving on to NEx64T and for 32-bit code only, we have the following graph:
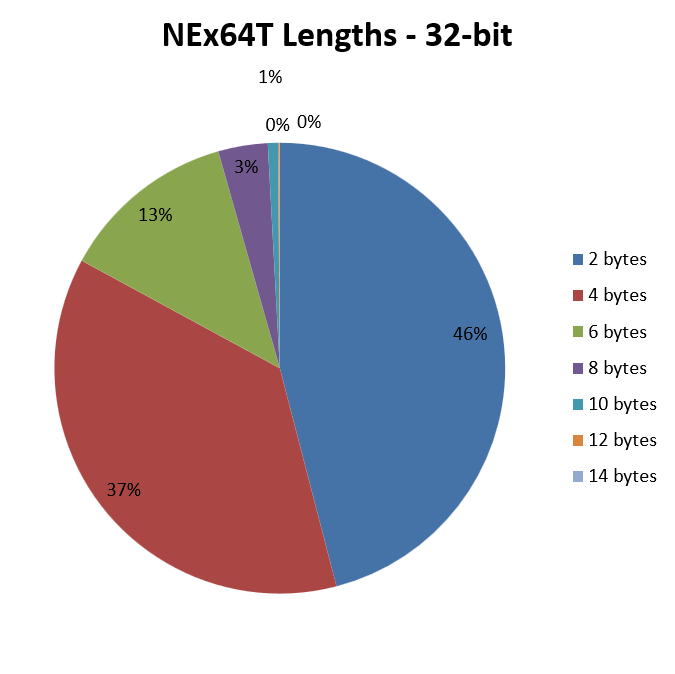
It is glaring how, in this case, the strong point is represented by instructions using opcodes of only two bytes, which account for just under half of the total, and thus weigh heavily on the contribution to the average length.
Also very important are instructions with opcodes of four bytes, which account for almost 40%. It is interesting to note that, ideally overlapping the graph with that of x86, these opcodes cover almost the entire pie of the latter’s five-byte opcodes, thus mitigating the disadvantage due to x86’s three-byte opcodes.
The rest of the cases are quite similar to x86. On the other hand, very long instructions are certainly not the most common.
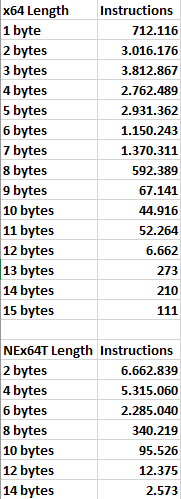
Turning now to 64-bit code, x64 shows us the following graph:
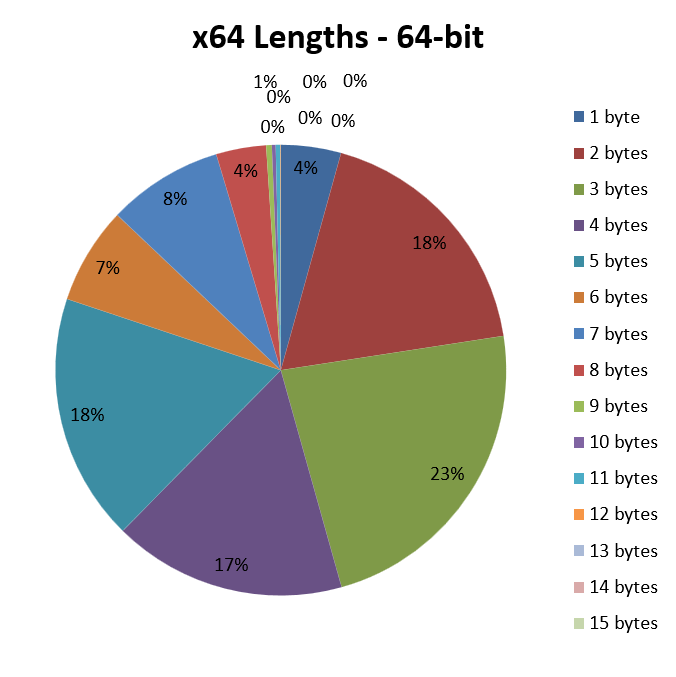
All the advantage of x86’s one-byte opcodes has been lost, as only 4% of instructions make use of them, with a large proportion having “turned” into two-byte opcodes.
Obviously, the situation can only get worse, starting from this premise: opcodes make use of more and more bytes, consequently increasing the average instruction length to the 4.05 bytes we have already seen.
On the other hand, we know that x64 often requires the use of an additional prefix, compared to x86, in order to access the 8 new registers, as well as to extend the data size from 32 and 64 bits, and this is very clearly reflected by the numbers above.
Finally, we come to the graph of 64-bit code for NEx64T:
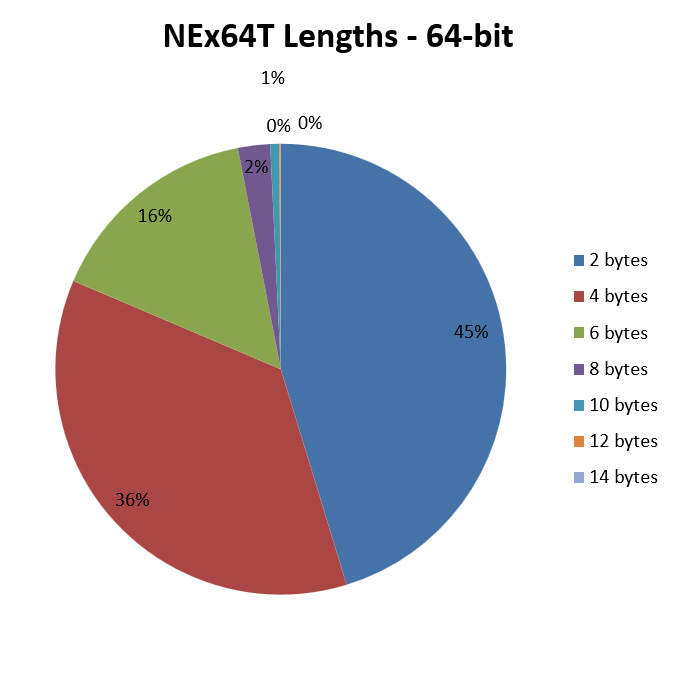
Here there are no particular surprises, since it mirrors almost the same for 32-bit code, apart from a slight increase in instructions using 6-byte opcodes.
On the other hand, I had already reported that the structure of opcodes is essentially the same, whatever the code (32 or 64 bit), and this is reflected quite clearly in the two images.
For those interested, Appendix D shows the data used by all four graphs.
Conclusions
This concludes a long digression on the two most important metrics, interspersed with several graphs to make the reading more relaxing.
I think that the advantages of NEx64T are palpable with respect to x86 and, above all, x64 (which is now the reference architecture, given that CPUs are no longer produced that implement only x86 and not x64. Moreover, most operating systems have only supported the latter for years now).
I must, however, emphasise that this is only preliminary data that was obtained by disassembling some 30 million instructions from just over 50 applications (although they are quite heterogeneous, as can be seen from the first appendix).
They serve, therefore, to provide an indication: a trend of the potential of this new architecture, although I am convinced that the situation can only improve further. This is because we have to take into account the fact that at the moment code generated specifically for x86 and x64 has been used, which has been “recycled” and “repurposed”, where possible, for NEx64T.
Thus, there is nothing generated and optimised specifically for this ISA and, above all, no use is made of the many innovations it brings compared to two other, more emblazoned ones.
The next article will explain its new functionalities and a general overview of the architecture, so as to better understand why it can do even more than the already excellent numbers that have been presented to accompany it.
Appendix A – Details of the statistics
Appendix B – Details of instructions length
Appendix C – Details of the number of instructions executed
Appendix D – Details of the instructions distribution
Appendix E – Some transformations performed by the peephole optimiser
MOV Reg1,Immediate64 ARITHMETIC Reg2,Reg1 --> ARITHMETIC Reg2,Immediate64 MOV Reg1,Operand1 MOV Operand2,Reg1 --> MOV Operand2,Operand1 CMP Reg1,Reg2 JNZ Label --> JNZ Reg1,Reg2,Label CMP Operand,0 Jcc Label --> Jcc Operand,Label CMP Operand,Reg Jcc Label --> CMPJcc Operand,Reg,Label TEST Reg,Reg Jcc Label --> Jcc Reg,Label LEA Reg,Operand PUSH Reg --> PEA Operand MOV [Reg1],Reg2 ADD Reg1,4 --> MOV [Reg1]+,Reg
Quickcalls, x86/32-bit: PUSH EBP MOV EBP, ESP PUSH EBX --> QCALL 8 Quickcalls, x64/64-bit: POP RDI POP RBP RET --> QCALL 59
Appendix F – Some possible transformations but not performed by the peephole optimiser
INSTRUCTIONS THAT CANNOT BE FUSED DUE TO REORDERING 0x0090ed6d (6) 8d85dcfcffff LEA EAX, [EBP-0x324] 0x0090ed73 (2) 6a00 PUSH 0x0 0x0090ed75 (1) 50 PUSH EAX -> 0x0090ed73 (2) 6a00 PUSH 0x0 0x0090ed6d (6) 8d85dcfcffff PEA [EBP-0x324]-2 bytes, -1 instructions executed, -1 register used0x0090ee2f (6) 8d85dcfcffff LEA EAX, [EBP-0x324] 0x0090ee35 (2) 1adb SBB BL, BL 0x0090ee37 (3) 8945fc MOV [EBP-0x4], EAX -> 0x0090ee35 (2) 1adb SBB BL, BL 0x0090ee2f (6) 8d85dcfcffff LEA [EBP-0x4], [EBP-0x324]-1 instructions executed, -1 register used0x004b5366 (3) 8b430c MOV EAX, [EBX+0xc] 0x004b5369 (2) 33f6 XOR ESI, ESI 0x004b536b (6) 8985bcf5ffff MOV [EBP-0xa44], EAX -> 0x004b5369 (2) 33f6 XOR ESI, ESI 0x004b5366 (3) 8b430c MOV.L [EBP-0xa44], [EBX+0xc]-1 instructions executed, -1 register used0x004b53d7 (7) 80bdc7f5ffff00 CMP BYTE [EBP-0xa39], 0x0 0x004b53de (1) 59 POP ECX 0x004b53df (1) 59 POP ECX 0x004b53e0 (2) 7421 JZ 0x4b5403 -> 0x004b53de (1) 59 POP ECX 0x004b53df (1) 59 POP ECX 0x004b53d7 (7) 80bdc7f5ffff00 JZ.B [EBP-0xa39], 0x4b5403-1 instructions executed0x00994539 (3) 8b4818 MOV ECX, [EAX+0x18] 0x0099453c (1) 49 DEC ECX 0x0099453d (3) 894808 MOV [EAX+0x8], ECX -> 0x0099453d (3) 894808 DEC.L [EAX+0x8], [EAX+0x18]-2 bytes, -2 instructions executed, -1 register used0x0093ba0d (2) 8a06 MOV AL, [ESI] 0x0093ba0f (2) 8807 MOV [EDI], AL 0x0093ba11 (1) 46 INC ESI 0x0093ba12 (1) 47 INC EDI -> 0x0093ba0f (2) 8807 MOV.B [EDI]+, [ESI]+-4 bytes, -2 instructions executed, -1 register used0x0044fc70 (2) 8a02 MOV AL, [EDX] 0x0044fc72 (1) 42 INC EDX 0x0044fc73 (2) 84c0 TEST AL, AL -> 0x0044fc70 (2) 8a02 MOV! AL, [EDX]+-2 instructions executed0x0093b9d0 (4) f30f6f06 MOVDQU XMM0, [ESI] 0x0093b9d4 (5) f30f6f4e10 MOVDQU XMM1, [ESI+0x10] 0x0093b9d9 (4) f30f7f07 MOVDQU [EDI], XMM0 0x0093b9dd (5) f30f7f4f10 MOVDQU [EDI+0x10], XMM1 0x0093b9e2 (3) 8d7620 LEA ESI, [ESI+0x20] 0x0093b9e5 (3) 8d7f20 LEA EDI, [EDI+0x20] -> 0x0093b9d9 (4) f30f7f07 PMOVU.Q [EDI]+, [ESI]+ 0x0093b9dd (5) f30f7f4f10 PMOVU.Q [EDI]+, [ESI]+-4 instructions executed, -2 registers used0x004522db (3) 0f57c0 XORPS XMM0, XMM0 [...] 0x004522f1 (5) 660f1345ec MOVLPD [EBP-0x14], XMM0 -> 0x004522f1 (5) 660f1345ec PMOVL.D [EBP-0x14], 0-2 bytes, -1 instructions executed, -1 register used







