
I benefici di una struttura semplice degli opcode sono stati illustrati nell’articolo precedente per la nuova architettura NEx64T, ma consentire una decodifica efficiente, per quanto importante, è soltanto uno dei fattori che caratterizzano un’architettura e ne possono certificare la “bontà”.
La densità di codice
Un altro, di cui peraltro abbiamo ampiamente parlato in queste pagine (in particolare in quest’articolo), è quello della densità di codice, che riveste un ruolo di primo piano, in quanto influenza tutta la gerarchia della memoria e, di conseguenza, le prestazioni e i consumi.
L’obiettivo, in questo caso, è di far occupare meno spazio possibile alle applicazioni. Il che si traduce in due fattori a cui è direttamente legata: la dimensione (media) delle istruzioni e il numero di istruzioni eseguite.
Si può, quindi, pensare di ridurre la dimensione delle istruzioni, ma bisogna anche stare attenti a non aumentare il numero di istruzioni eseguite, pena l’effetto opposto (un maggior numero di istruzioni comporta un aumento dello spazio da loro occupato).
Pertanto l’ideale sarebbe quello di cercare di ottenere un buon bilanciamento fra questi due fattori, di modo che la loro combinazione comporti complessivamente uno spazio più ridotto (rispetto alle altre architetture di riferimento).
La lunghezza delle istruzioni
Ovviamente tutto ciò dipende da come sono sono stati strutturati gli opcode e da quali funzionalità (cioè dal “lavoro utile” che viene svolto) sono implementate nelle istruzioni. Riguardo il primo caso abbiamo già visto sommariamente qualcosa nel precedente articolo e aggiungeremo altro alla fine di questo, mentre per il secondo vedremo meglio in un apposito articolo (perché c’è di più da dire).
Adesso, invece, vediamo un po’ di numeri che ci fanno capire come sia messa NEx64T in termini di lunghezza delle istruzioni, mostrandola coi suoi due benchmark di riferimento (x86 e x64, rispettivamente per il codice a 32 e 64 bit) e il lavoro fatto da un’applicazione Python che si è occupata di disassemblare un certo numero di istruzioni da alcune applicazioni (nell’Appendice A ne sono riportati i numeri) per le due architetture e convertirle nelle equivalenti NEx64T, effettuando alcune ottimizzazioni (ove possibile).
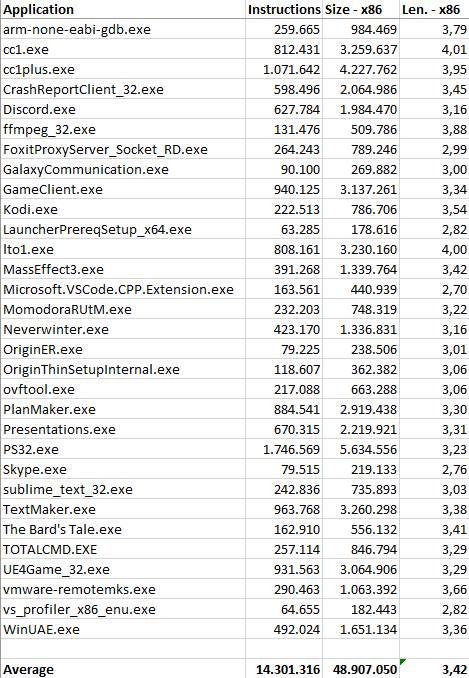
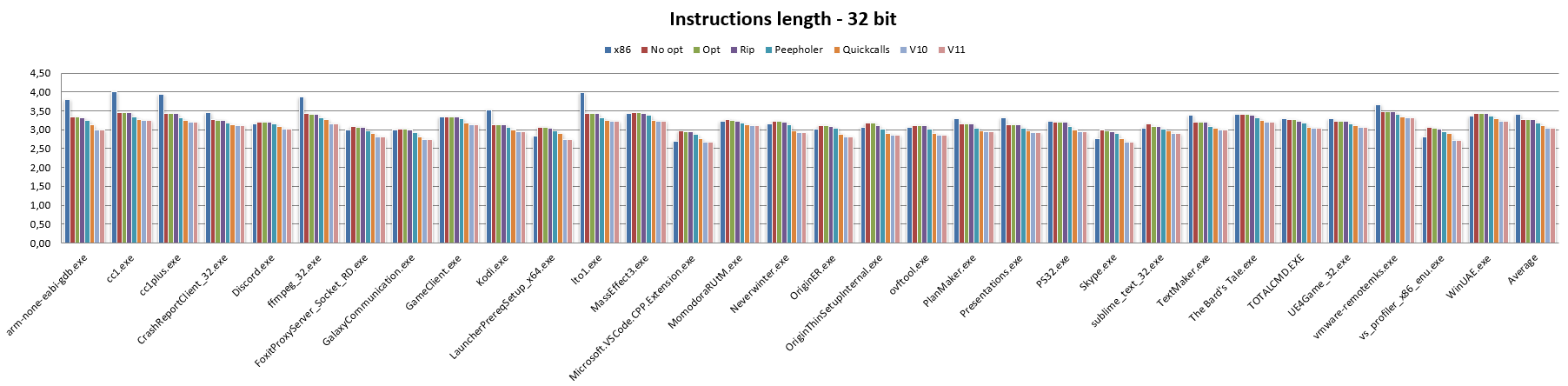
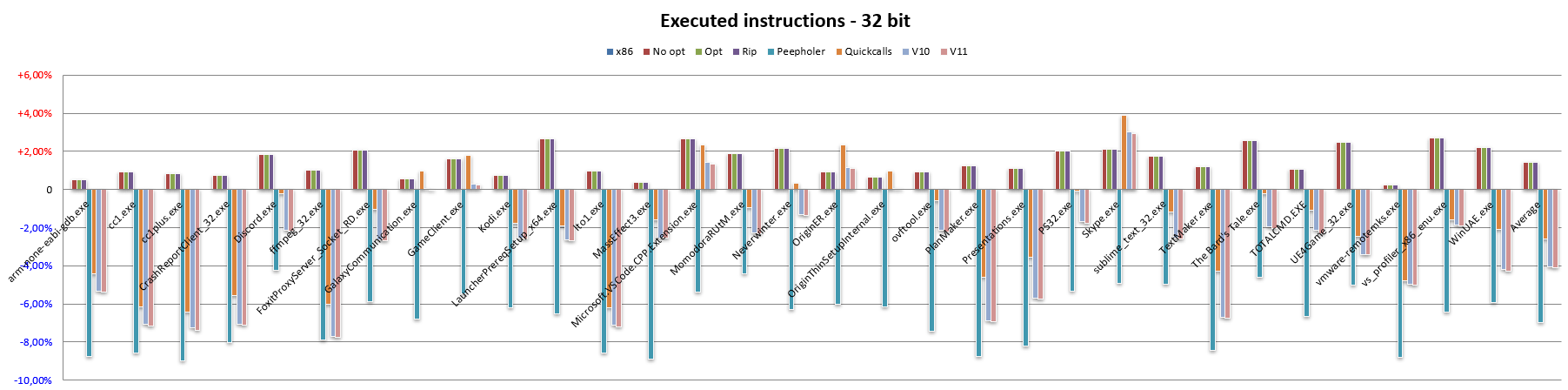
Cominciamo col codice a 32 bit (confrontato, ovviamente, con x86):
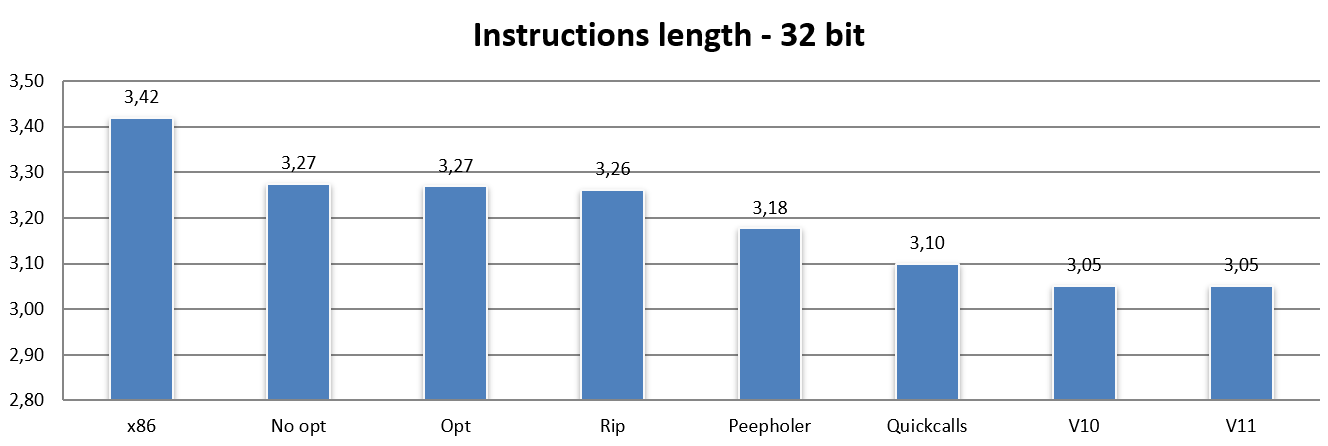
La barra x86 è ovviamente quella relativa alla lunghezza media per quest’architettura, che si assesta sui 3,42 byte per istruzione (questo con l’insieme di applicazioni utilizzate e col numero di istruzioni che si è riusciti a disassemblare).
No opt riporta l’esatta traduzione di un’istruzione x86 in una (o più, nei casi più complessi / legacy) di NEx64T (specificamente di v9: la nona versione che ho realizzato), senza effettuare alcuna ottimizzazione né utilizzare alcuna caratteristica peculiare della nuova ISA.
Ad esempio, x86 usa soltanto 8 registri e lo stesso viene fatto per NEx64T (fatta eccezione per alcuni casi, che vedremo meglio in un apposito articolo sulle questioni prettamente legacy). Inoltre non vengono utilizzate nuove istruzioni, nuove modalità d’indirizzamento e nemmeno nulla di nuovo delle modalità SIMD / vettoriali / blocco di istruzioni.
Con No opt si può già vedere come NEx64T riesca a fare mediamente meglio rispetto a x86, pur con quest’ultima che risulta essere abbastanza nota e rinomata per avere una densità di codice molto buona.
C’è da dire che x86 si comporta così bene anche grazie all’ABI adottata, la quale prevede il passaggio di pochi parametri nei registri per le chiamate a funzione. Scelta in ogni caso forzata, considerato che ce ne sono soltanto 8 a disposizione (di cui uno è pure il puntatore allo stack).
Questo comporta il push sullo stack di tutti gli eventuali altri parametri, come pure il frequentissimo uso di push e pop di registri sullo/dallo stack quando serve liberare e utilizzare qualche registro per delle operazioni.
Poiché le istruzioni di PUSH e POP occupano un solo byte su x86, ecco spiegato perché quest’architettura ottiene così buoni valori riguardo la densità di codice. NEx64T, invece, risulta penalizzato in questo caso, in quanto la lunghezza minima delle istruzioni è di due byte, per cui le numerosissime istruzioni PUSH e POP occupano il doppio rispetto a x86, dopo la traduzione.
Passando alla barra Opt non si nota alcun cambiamento. In questo caso vengono effettuate soltanto alcune semplicissime ottimizzazioni, come ad esempio convertire un’istruzione AND LocazioneDiMemoria,0 in MOV LocazioneDiMemoria,0 oppure OR LocazioneDiMemoria,-1 in MOV LocazioneDiMemoria,-1, e AND LocazioneDiMemoria,-Immediato in SUB LocazioneDiMemoria,Immediato, perché con NEx64T occupano meno spazio.
Un lievissimo miglioramento si assiste con la barra Rip, anche se è poco rilevante (appena un centesimo). In questo caso l’unico cambiamento effettuato riguarda la conversione degli indirizzi assoluti a 32 bit negli equivalenti indirizzi relativi al PC (modalità d’indirizzamento RIP, che non esiste in x86 ed è disponibile soltanto su x64), che consente di risparmiare qualcosa nei casi in cui la locazione referenziata sia abbastanza vicina.
L’ottimizzatore Peephole al lavoro
Una parte più sostanziosa arriva dall’introduzione di un ottimizzatore peephole (chiamato Peepholer nei grafici), il quale si occupa di analizzare coppie di istruzioni x86 o x64 ed eventualmente convertirle in una singola istruzione NEx64T. Soltanto alcuni esempi, fra i più comuni, sono riportati nell’Appendice E a scopo puramente rappresentativo, per dare un’idea di come lavori.
Questo serve già a dimostrare le ulteriori potenzialità della nuova architettura, grazie a nuove istruzioni e/o modalità d’indirizzamento che mette a disposizione. Purtroppo analizzando soltanto due istruzioni alla volta non si può fare molto, per tre motivi:
- il compilatore originale ha provveduto a “riordinare” le istruzioni generate, in modo da ridurre le dipendenze fra di esse e, quindi, ottimizzarne l’esecuzione (il che è fondamentale in architetture in-order, ad esempio);
- sarebbe stato possibile utilizzare due diverse modalità d’indirizzamento nella stessa istruzione, che però nel codice hanno generato 3 o più istruzioni;
- sarebbe stato possibile far uso di funzionalità estese, come il caricamento dei valori con estensione del segno o dello zero, ma il codice generato è di 3 o più istruzioni.
L’Appendice F mostra un elenco di spezzoni di codice (soltanto alcuni, sempre a titolo puramente rappresentativo) trovati in alcune delle applicazioni disassemblate, mostrando cosa si sarebbe potuto fare (rimpiazzare due, tre o quattro istruzioni con una sola) e le potenzialità ancora inespresse di NEx64T, che può senza dubbio alcuno contribuire a migliorare ancora di più la densità di codice e le prestazioni.
Un altro grosso problema che ha inciso molto sulla densità di codice è quello relativo al prologo e all’epilogo delle funzioni, le quali fanno spesso abbondante uso delle già menzionate istruzioni PUSH e POP per salvare i registri sullo stack per poi ripristinarli alla fine del loro uso.
Si tratta di liste di diverse istruzioni (ben più di due!), che chiaramente l’ottimizzatore peephole, per come funziona ed è stato strutturato, non poteva di certo gestire normalmente.
Fortunatamente si tratta spesso di sequenze di istruzioni identiche, che si ripetono sistematicamente allo stesso modo, per cui è stato abbastanza semplice intercettarne un certo numero di sequenze predeterminate (64 in totale) senza stravolgere completamente l’attuale impianto dell’ottimizzatore peephole.
Il risultato di questo lavoro viene mostrato dalla barra Quickcalls, la quale riporta un’altra consistente riduzione della lunghezza media delle istruzioni e, quindi, un netto beneficio in termini di densità di codice. Non sono, però, tutte rose e fiori, come verrà evidenziato più avanti, quando si affronterà il tema del numero di istruzioni eseguite.
Le versioni 10 e 11 di NEx64T
Dopo aver completato i lavori per la nona versione (v9) dell’architettura c’è stata occasione per rimettere mano al progetto grazie ad alcune idee che sono venute fuori e che meritavano di essere implementate in NEx64T, com’è dimostrato dalla barra v10, per l’appunto.
Si tratta di alcuni cambiamenti alla struttura degli opcode e qualche nuova istruzione “compressa” (equivalente di un’istruzione più lunga), ma molto lavoro è stato fatto nell’ottimizzatore peephole, che è stato in grado di gestire parecchi altri casi e alcuni anche molto comuni.
Ad esempio in diverse occasioni / pattern ricorrenti è stato possibile togliere completamente di mezzo le istruzioni MOVZX e MOVSX, le quali estendono con zero o con segno un dato di dimensione inferiore alla lunghezza del registro.
Con NEx64T esiste la possibilità di realizzare quest’operazione come parte integrante di una qualunque istruzione (il cui funzionamento / comportamento è stato “esteso”), al prezzo dell’utilizzo di opcode un po’ più lunghi.
Ciò non è sempre applicabile (o, per meglio dire, non sempre desiderabile), in quanto la nuova istruzione potrebbe richiedere più spazio rispetto alle due istruzioni x86/x64 che dovrebbe andare a sostituire, per cui bisogna vedere nello specifico come procedere.
In questi casi ho sempre scelto di non far aumentare lo spazio occupato anziché ridurre il numero di istruzioni eseguite. Quindi tutti i dati sulle ottimizzazioni riportate nei vari grafici sono sempre intesi a favorire la dimensione del codice (compilazione per “size” anziché “speed“, in gergo).
In ogni caso i risultati ottenuti si sono rivelati abbastanza buoni. Mentre lo stesso non si può dire con la successiva versione, la v11, come si può vedere dalla relativa barra.
Il motivo è che l’undicesima versione ha visto principalmente una riorganizzazione degli opcode, togliendo di mezzo un po’ di roba legacy di x86/x64, similmente a quanto Intel ha proposto con la sua futura architettura X86-S (di cui abbiamo parlato in quest’articolo), e riciclandone lo spazio per qualche altra miglioria (che non è visibile per quanto riguarda la lunghezza delle istruzioni).
Lunghezza delle istruzioni a 64 bit
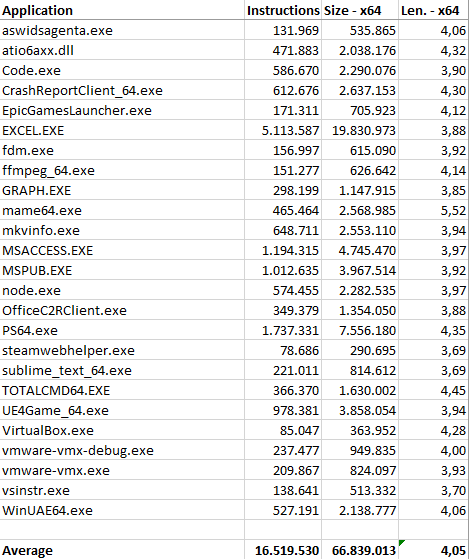
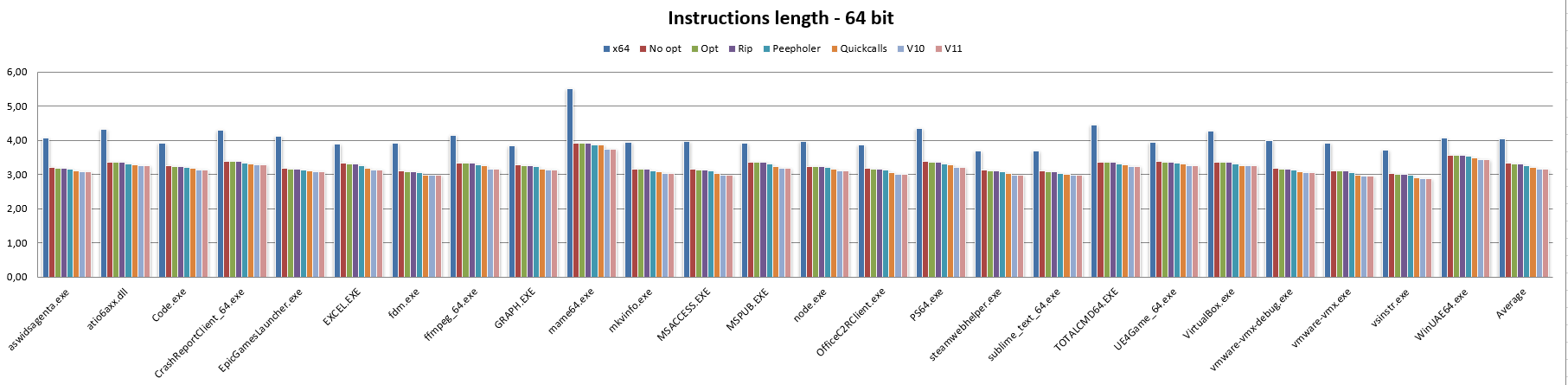
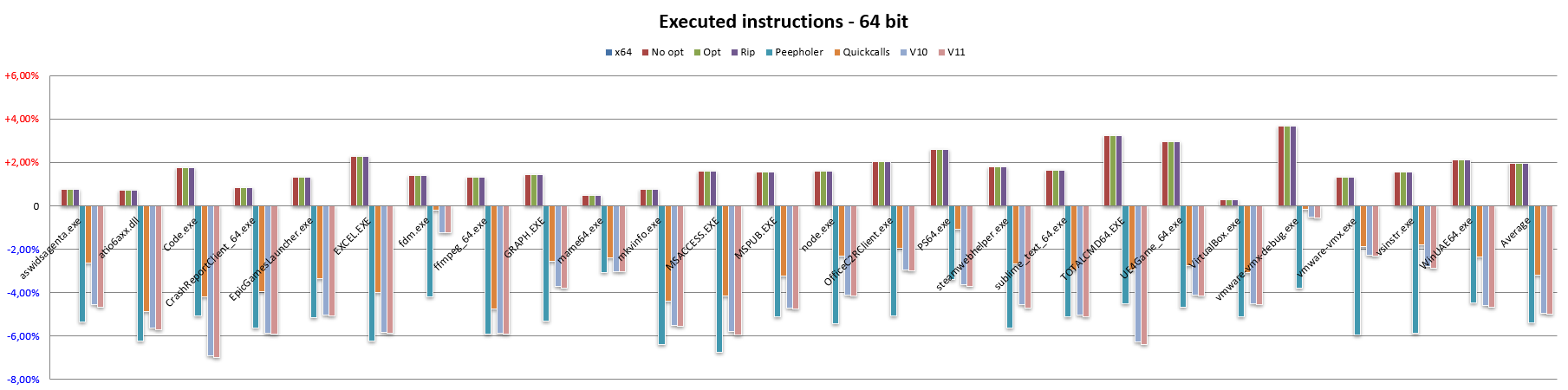
Finito col codice a 32 bit, vediamo adesso come si comporta NEx64T col codice a 64 bit (e, quindi, contro l’architettura x64):
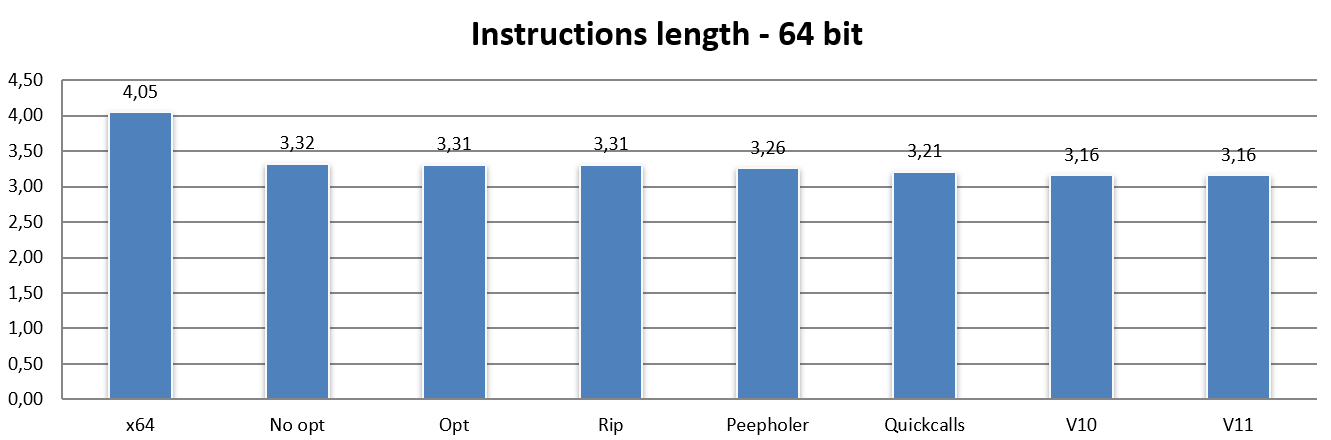
In questo caso vediamo subito che persino la banalissima traduzione letterale delle istruzioni x64 nelle equivalenti NEx64T (o qualcuna in più, in certi casi più complessi / legacy) comporti una drastica riduzione della lunghezza media delle istruzioni.
Il che è un risultato anche atteso, considerato che la struttura degli opcode di questa architettura è sostanzialmente la stessa per il codice a 32 bit e 64 bit, con soltanto alcune lievi differenze. In questo caso i risultati leggermente diversi sono imputabili quasi esclusivamente al fatto che x86 abbia un’ABI stack-based, come già discusso parlando di PUSH e POP, mentre x64 è register-based. Quindi utilizzano mix di istruzioni diverse per le chiamate a funzione, da cui le differenze.
Le micro-ottimizzazioni hanno pochissimo effetto, com’è visibile dalla barra Opt, e lo stesso vale per la barra Rip (anche questo ovviamente atteso, considerato che non ci sono indirizzi assoluti a 32 bit da convertire nella modalità RIP: tutti gli indirizzi sono già relativi al PC!).
Similmente a quanto riscontrato per il codice a 32 bit, la barra Peepholer mostra una sensibile riduzione della lunghezza delle istruzioni, e lo stesso vale per la barra Quickcalls, sebbene in entrambi i casi non si raggiungano gli stessi benefici osservati passando da x86 a NEx64T, mentre passando a v10 e v11 si osservano, nelle rispettive barre, le stesse diminuzioni riscontrate in precedenza.
L’Appendice B riporta i dati più dettagli riguardo la lunghezza delle istruzioni, suddivisi per le singole applicazioni utilizzate.
Numero di istruzioni eseguite
Passando adesso all’altra importante metrica menzionata all’inizio dell’articolo, un comportamento per certi versi simile (ma con dei necessari distinguo) si riscontra anche nel numero di istruzioni eseguite.
In particolare, per il codice a 32 bit (sempre riferito a x86):
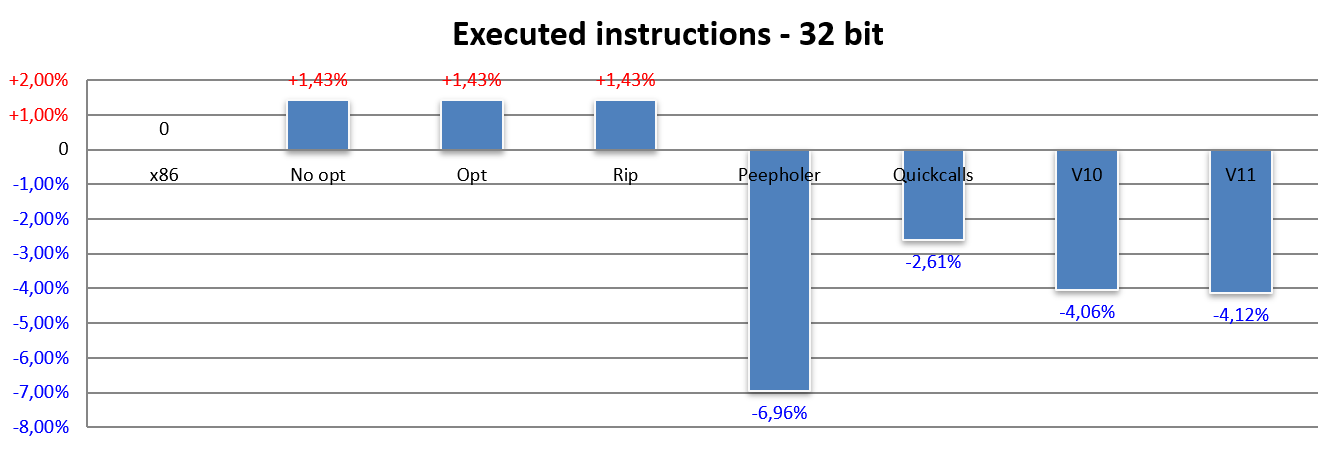
Qui la cosa che salta subito all’occhio è il fatto che tutte e tre le barre No opt, Opt e Rip riportano esattamente lo stesso risultato: un incremento di poco meno dell’1,5% del numero di istruzioni eseguite. Ciò si verifica a causa dei casi più complessi / legacy di x86, che richiedono più di un’istruzione per essere emulati da NEx64T.
Mi riferisco in particolare a:
- uso dei registri “alti” a 8 bit (
AH,BH,CHeDH), i quali sono ancora utilizzati (anche se molto poco, fortunatamente), pur essendo un retaggio dell’8086; - modalità d’indirizzamento in memoria indicizzato e scalato.
NEx64T non possiede nemmeno il concetto di registro “alto”, per cui per emularne fedelmente il funzionamento ha bisogno di due o anche tre istruzioni addizionali che effettuano le necessarie risistemazioni dei dati prima di poter eseguire l’istruzione vera e propria, rimettendo poi i dati al loro posto subito dopo.
Riguardo la modalità indicizzata e scalata, invece, la differenza risiede nel fatto che NEx64T supporti esclusivamente lo scaling basato sulla dimensione dei dati manipolati, mentre x86 e x64 consentono di selezionare uno qualunque dei quattro fattori di scaling messi a disposizione: 1, 2, 4 o 8 (per dati che vanno da 8 a 64 bit).
Quindi se si leggono o scrivono dati a 8 bit, lo scaling sarà 1, mentre sarà 2 per dati a 16 bit, ecc.. E’ interessante notare che le istruzioni SIMD/vettoriali hanno registri molto grandi, per cui su NEx64T lo scaling sarà proporzionale: per registri da 512 bit sarà, infatti, di ben 64 (mentre su x86/x64 il massimo selezionabile sarà 8, come già detto).
Si tratta di una scelta, questa, dettata dal ridotto spazio a disposizione nella word (di 16 bit) che consente di specificare una qualunque modalità d’indirizzamento quando si referenzia la memoria. Sarebbero serviti due bit in più, che ovviamente non c’erano (a meno di complicare ulteriormente la struttura degli opcode, perdendo parecchi dei vantaggi).
A mio avviso si tratta di un buon compromesso (che dovrebbe coincidere con la natura stessa delle richieste di accesso alla memoria), i cui pregi superano nettamente i tre casi particolari che non sono direttamente supportati e che richiedono, per la loro emulazione, l’esecuzione di un’istruzione aggiuntiva (da cui i numeri leggermente peggiori rispetto a x86).
Ci sarebbe il caso della riduzione degli indirizzi da 64 a 32 bit e da 32 a 16 bit, che sono previsti da x64 e x86 rispettivamente, ma che non sono mai stati riscontrati nel codice analizzato. In ogni caso la gestione di questo caso particolare avrebbe comportato anch’esso l’esecuzione di un’ulteriore istruzione.
La barra Peepholer riporta, invece, un netto miglioramento rispetto a x86: quasi il 7% in meno di istruzioni eseguite, che compensa anche il precedente aumento di 1,5%. Ciò significa che è stato possibile individuare parecchie coppie (l’8,5%, per l’appunto) di istruzioni x86 che sono state “fuse” in una sola istruzione di NEx64T.
Purtroppo parecchio di questo vantaggio si perde nel momento in cui viene introdotto il supporto per il prologo e l’epilogo delle funzioni, com’è chiaramente visibile con la barra Quickcalls.
Fortunatamente la versione v10 ha consentito di recuperare un bel po’ di questa perdita, mentre è interessante notare che, almeno riguardo al numero di istruzioni eseguite, anche la v11 porta un piccolo contributo.
Una situazione simile si verifica per il codice a 64 bit (paragonato sempre a x64):
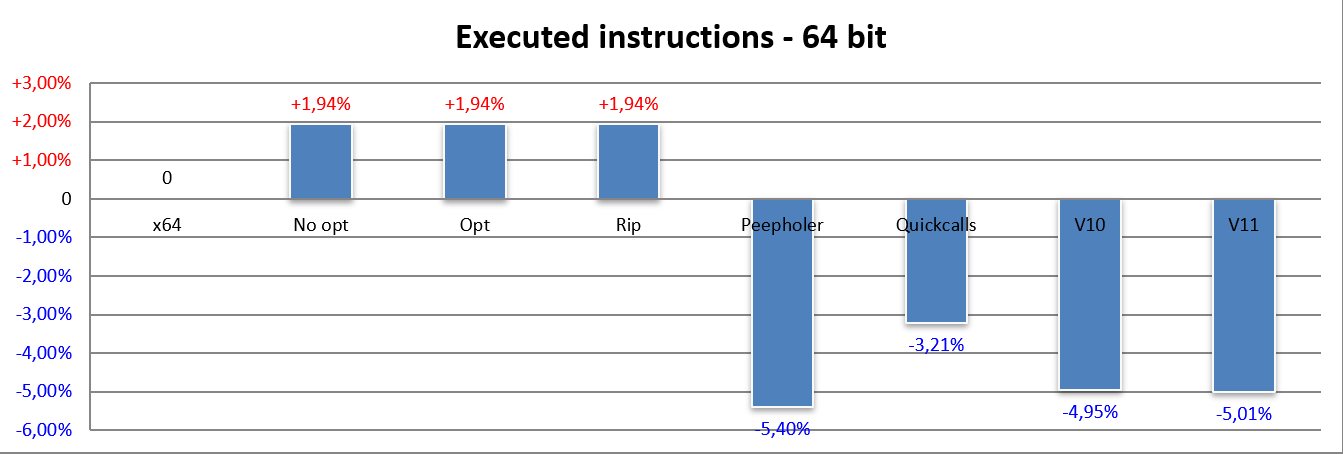
In questo caso l’impatto dei casi più complicati / legacy è un po’ più consistente (siamo al 2% adesso, contro il precedente 1,5%), il che può sembrare assurdo se consideriamo che x64 sia un’architettura più moderna di x86 e che abbia pure rimosso un po’ di legacy.
La spiegazione è dovuta al fatto che si assiste a un aumento delle occorrenze in cui si fa uso della summenzionata modalità indicizzata scalata, relativamente ai tre casi che non sono implementati in NEx64T, da cui i risultati.
Si riduce il contributo dell’ottimizzatore rispetto al codice a 32 bit, come emerge dalla barra Peepholer, anche se si arriva a un rispettabile 5,4%. In compenso l’impatto di Quickcalls è stato minore, e ciò ha consentito di recuperare un po’ di quanto si perderebbe normalmente, probabilmente perché l’ABI è cambiata (rispetto a x86) e si fa meno uso dello stack.
Infine il passaggio alla versione v10 dell’ISA fa sentire il suo peso in maniera abbastanza similare, e lo stesso si può dire dall’apporto della versione v11.
Anche qui, dati più completi e suddivisi per le singole applicazioni utilizzate si possono analizzare nell’Appendice C.
Distribuzione delle istruzioni
Finita l’analisi delle due più importanti metriche che vengono utilizzate quando si parla di architetture degli elaboratori, fornisco anche qualche statistica che può essere interessante per gli appassionati e studiosi in materia, mostrando dei grafici sulla distribuzione degli opcode delle istruzioni in base alla loro lunghezza.
Cominciamo con x86 (e, quindi, con codice a 32 bit):
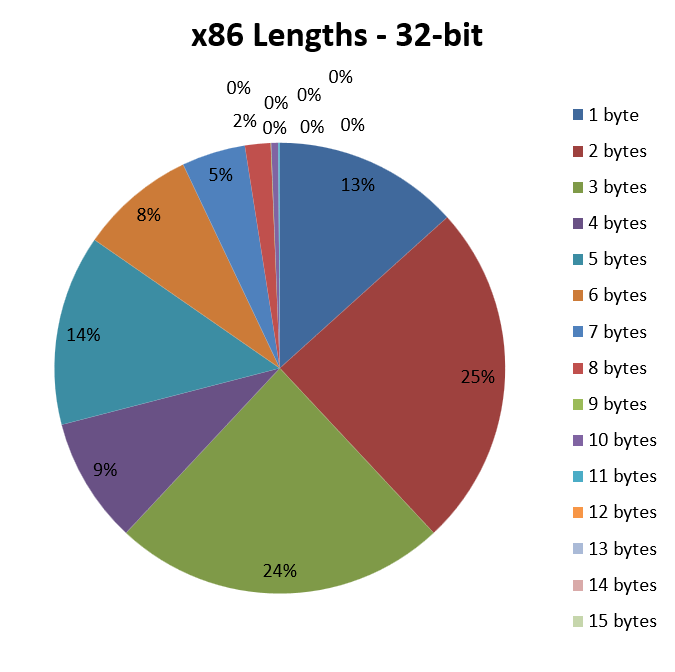
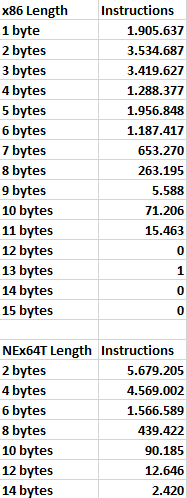
Come si può vedere, la parte del leone la fanno gli opcode lunghi due o tre byte, che sono presenti rispettivamente nel 25% e 24% delle istruzioni disassamblate e analizzate. Letta in un altro modo, significa che circa il 50% delle istruzioni ha una lunghezza media pari a 2,5 byte.
Molto importanti sono anche gli opcode costituiti da un solo byte, che si accaparrano ben il 13% della torta, e che contribuiscono anch’essi a far scendere un po’ la lunghezza media delle istruzioni.
Per contro, il 14% degli opcode è lungo ben cinque byte. Il che significa che, mettendo assieme opcode di un byte e di cinque byte, quasi il 30% delle istruzioni ha una lunghezza media di 3 byte, che è ancora un ottimo valore.
Purtroppo sono tutti gli altri casi che rimangono a far alzare l’asticella, fino a giungere ai 3,42 byte di lunghezza media per le istruzioni, che rimane in ogni caso un risultato lusinghiero, per il quale x86 è anche famosa (ha una buona densità di codice, infatti).
Passando a NEx64T e per il solo codice a 32 bit abbiamo il seguente grafico:
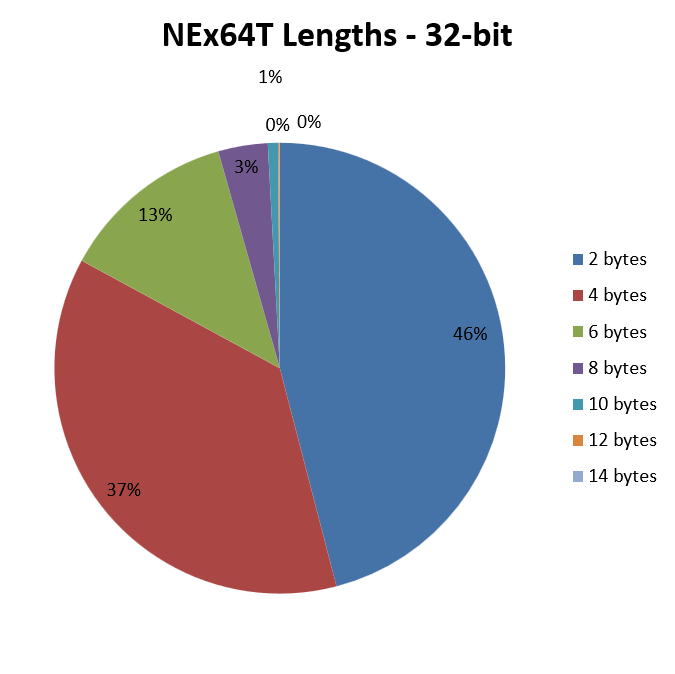
E’ lampante come, in questo caso, il punto di forza sia rappresentato dalle istruzioni facenti uso di opcode di soli due byte, le quali rappresentano poco meno della metà del totale e, quindi, che pesano tantissimo sul contributo alla lunghezza media.
Anch’esse molto importanti sono, poi, le istruzioni con opcode di quattro byte, che arrivano a quasi il 40%. E’ interessante notare che, sovrapponendo idealmente il grafico con quello di x86, questi opcode coprono fino a quasi tutta la torta di quelli da cinque byte di quest’ultima, mitigando quindi lo svantaggio dovuto agli opcode da tre byte di x86.
Il resto dei casi è abbastanza simile a x86. D’altra parte le istruzioni molto lunghe non sono certo quelle più comuni.
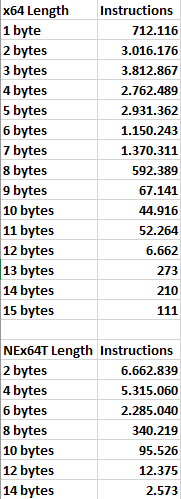
Passando adesso al codice a 64 bit, x64 ci mostra il seguente grafico:
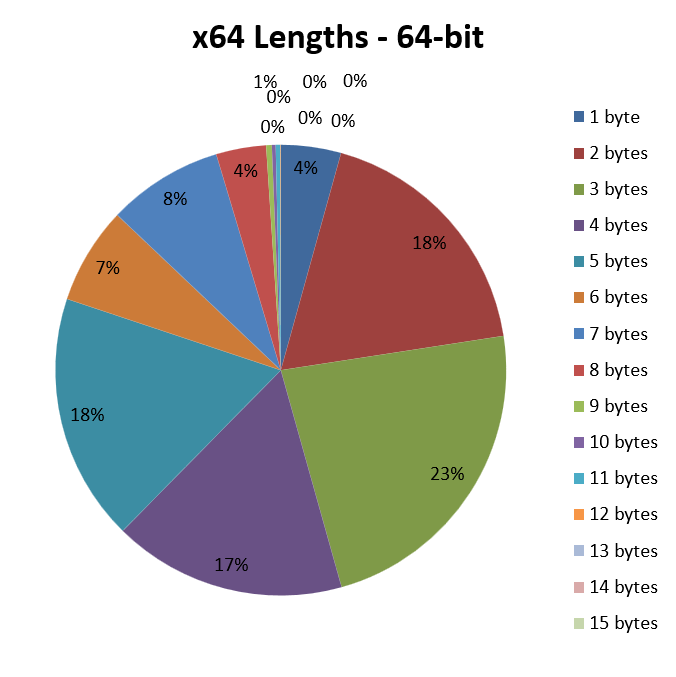
Tutto il vantaggio degli opcode da un solo byte di x86 è andato perduto, visto che soltanto il 4% delle istruzioni ne fa uso, con una parte abbondante che si è “trasformata” in opcode da due byte.
Ovviamente la situazione non può che peggiorare, partendo da queste premesse: gli opcode fanno via via uso di più byte, facendo di conseguenza crescere molto la lunghezza media delle istruzioni, e portandola ai 4,05 byte che abbiamo già visto.
D’altra parte sappiamo che x64 richiede spesso l’uso di un prefisso aggiuntivo, rispetto a x86, per poter accedere agli 8 nuovi registri, come pure per estendere la dimensione dei dati da 32 e 64 bit, e ciò si riflette in maniera molto chiara dai numeri qui sopra riportati.
Infine arriviamo al grafico del codice a 64 bit per NEx64T:
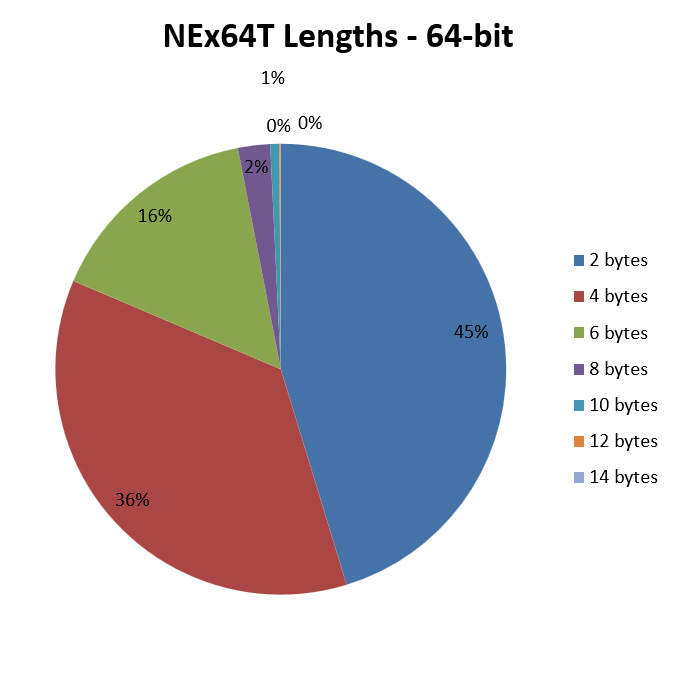
Qui non ci sono particolari sorprese, visto che rispecchia quasi del tutto il medesimo per il codice a 32 bit, a parte un leggero aumento delle istruzioni facenti uso di opcode di 6 byte.
D’altra parte avevo già riportato che la struttura degli opcode è sostanzialmente la stessa, qualunque sia il codice (32 o 64 bit), e ciò si riflette in maniera abbastanza chiara nelle due immagini.
Per chi fosse interessato, l’Appendice D riporta i dati utilizzati dai tutti e quattro i grafici.
Conclusioni
Con ciò si chiude una lunga digressione sulle due metriche più importanti, intervallate da parecchi grafici per rendere più distensiva la lettura.
Penso che i vantaggi di NEx64T siano palpabili nei confronti di x86 e, soprattutto, di x64 (che è ormai l’architettura di riferimento, considerato che non vengono più prodotte CPU che implementino soltanto x86 e non x64. Inoltre la maggior parte dei s.o. supporta ormai da anni soltanto quest’ultima).
Devo, però, sottolineare che si tratta soltanto di dati preliminari che sono stati ottenuti disassemblando circa 30 milioni di istruzioni di poco più di 50 applicazioni (sebbene siano abbastanza eterogenee, come si può vedere dalla prima appendice).
Servono, quindi, a fornire un’indicazione: un trend delle potenzialità di questa nuova architettura, anche se sono convinto che la situazione non possa che migliorare ulteriormente. Questo perché dobbiamo tenere conto del fatto che al momento è stato utilizzato codice generato appositamente per x86 e x64, che è stato “riciclato” e “riadattato”, ove possibile, per NEx64T.
Quindi non v’è nulla di generato e ottimizzato appositamente per quest’ISA e, soprattutto, non si fa uso di tante innovazioni che essa porta rispetto altre altre due più blasonate.
Il prossimo articolo illustrerà le sue nuove funzionalità e una panoramica generale dell’architettura, in modo da far comprende meglio il perché possa fare ancor di più rispetto ai già ottimi numeri che sono stati presentati a corredo.
Appendice A – Dettagli delle statistiche
Appendice B – Dettagli della lunghezza delle istruzioni
Appendice C – Dettagli del numero di istruzioni eseguite
Appendice D – Dettagli della distribuzione delle istruzioni
Appendice E – Alcune trasformazioni eseguite dall’ottimizzatore peephole
MOV Reg1,Immediate64 ARITHMETIC Reg2,Reg1 --> ARITHMETIC Reg2,Immediate64 MOV Reg1,Operand1 MOV Operand2,Reg1 --> MOV Operand2,Operand1 CMP Reg1,Reg2 JNZ Label --> JNZ Reg1,Reg2,Label CMP Operand,0 Jcc Label --> Jcc Operand,Label CMP Operand,Reg Jcc Label --> CMPJcc Operand,Reg,Label TEST Reg,Reg Jcc Label --> Jcc Reg,Label LEA Reg,Operand PUSH Reg --> PEA Operand MOV [Reg1],Reg2 ADD Reg1,4 --> MOV [Reg1]+,Reg
Quickcalls, x86/32-bit: PUSH EBP MOV EBP, ESP PUSH EBX --> QCALL 8 Quickcalls, x64/64-bit: POP RDI POP RBP RET --> QCALL 59
Appendice F – Alcune trasformazioni possibili, ma non effettuate dall’ottimizzatore peephole
INSTRUCTIONS THAT CANNOT BE FUSED DUE TO REORDERING 0x0090ed6d (6) 8d85dcfcffff LEA EAX, [EBP-0x324] 0x0090ed73 (2) 6a00 PUSH 0x0 0x0090ed75 (1) 50 PUSH EAX -> 0x0090ed73 (2) 6a00 PUSH 0x0 0x0090ed6d (6) 8d85dcfcffff PEA [EBP-0x324]-2 bytes, -1 instructions executed, -1 register used0x0090ee2f (6) 8d85dcfcffff LEA EAX, [EBP-0x324] 0x0090ee35 (2) 1adb SBB BL, BL 0x0090ee37 (3) 8945fc MOV [EBP-0x4], EAX -> 0x0090ee35 (2) 1adb SBB BL, BL 0x0090ee2f (6) 8d85dcfcffff LEA [EBP-0x4], [EBP-0x324]-1 instructions executed, -1 register used0x004b5366 (3) 8b430c MOV EAX, [EBX+0xc] 0x004b5369 (2) 33f6 XOR ESI, ESI 0x004b536b (6) 8985bcf5ffff MOV [EBP-0xa44], EAX -> 0x004b5369 (2) 33f6 XOR ESI, ESI 0x004b5366 (3) 8b430c MOV.L [EBP-0xa44], [EBX+0xc]-1 instructions executed, -1 register used0x004b53d7 (7) 80bdc7f5ffff00 CMP BYTE [EBP-0xa39], 0x0 0x004b53de (1) 59 POP ECX 0x004b53df (1) 59 POP ECX 0x004b53e0 (2) 7421 JZ 0x4b5403 -> 0x004b53de (1) 59 POP ECX 0x004b53df (1) 59 POP ECX 0x004b53d7 (7) 80bdc7f5ffff00 JZ.B [EBP-0xa39], 0x4b5403-1 instructions executed0x00994539 (3) 8b4818 MOV ECX, [EAX+0x18] 0x0099453c (1) 49 DEC ECX 0x0099453d (3) 894808 MOV [EAX+0x8], ECX -> 0x0099453d (3) 894808 DEC.L [EAX+0x8], [EAX+0x18]-2 bytes, -2 instructions executed, -1 register used0x0093ba0d (2) 8a06 MOV AL, [ESI] 0x0093ba0f (2) 8807 MOV [EDI], AL 0x0093ba11 (1) 46 INC ESI 0x0093ba12 (1) 47 INC EDI -> 0x0093ba0f (2) 8807 MOV.B [EDI]+, [ESI]+-4 bytes, -2 instructions executed, -1 register used0x0044fc70 (2) 8a02 MOV AL, [EDX] 0x0044fc72 (1) 42 INC EDX 0x0044fc73 (2) 84c0 TEST AL, AL -> 0x0044fc70 (2) 8a02 MOV! AL, [EDX]+-2 instructions executed0x0093b9d0 (4) f30f6f06 MOVDQU XMM0, [ESI] 0x0093b9d4 (5) f30f6f4e10 MOVDQU XMM1, [ESI+0x10] 0x0093b9d9 (4) f30f7f07 MOVDQU [EDI], XMM0 0x0093b9dd (5) f30f7f4f10 MOVDQU [EDI+0x10], XMM1 0x0093b9e2 (3) 8d7620 LEA ESI, [ESI+0x20] 0x0093b9e5 (3) 8d7f20 LEA EDI, [EDI+0x20] -> 0x0093b9d9 (4) f30f7f07 PMOVU.Q [EDI]+, [ESI]+ 0x0093b9dd (5) f30f7f4f10 PMOVU.Q [EDI]+, [ESI]+-4 instructions executed, -2 registers used0x004522db (3) 0f57c0 XORPS XMM0, XMM0 [...] 0x004522f1 (5) 660f1345ec MOVLPD [EBP-0x14], XMM0 -> 0x004522f1 (5) 660f1345ec PMOVL.D [EBP-0x14], 0-2 bytes, -1 instructions executed, -1 register used







