Cari lettori, vi presento la seconda parte (qui la prima) dell’articolo sui processi produttivi del nostro autore Nessuno. Buona lettura e grazie a Nessuno per il suo contributo.
4.0 14 vs 16nm, i protagonisti
Il riassunto di tutto quanto detto precedentemente può essere questo: l’avanzamento di tutti i parametri di miglioramento per il funzionamento di un chip si attua riducendo la dimensione del transistor (descrizione semplificata che comunque è sufficiente per la trattazione del nostro argomento), che implica l’uso di macchinari più sofisticati oltre che a una complicata ricerca di abbattimento di tutte le problematiche secondarie che nascono man mano che le dimensioni dei transistor scendono (alcune saranno descritte in seguito). Ecco perché l’evoluzione dei processi produttivi è così lenta, costosa ma anche dannatamente utile per progredire.
Da sempre un PP è identificato da un numero che indica una dimensione, un tempo lontano espressa in micrometri (milionesimi di metro, o millesimi di millimetro), poi più recentemente in nanometri (miliardesimi di metro, o milionesimi di millimetro). Storicamente questo numero descriveva la dimensione media (perché non tutti i transistor riescono perfettamente uguali) del gate del transistor realizzabile con quel PP. Oggi, però, non è più così.
Da diverso tempo infatti la “moda” è quella di usare i nanometri come indice di prestazioni del PP piuttosto che della sua reale capacità di realizzare i componenti fondamentali dei circuiti ad una determinata dimensione. Così abbiamo Samsung che ha chiamato il suo nuovo PP 14nm mentre TSMC lo ha definito 16nm. Quali caratteristiche siano state usate per definire “la nanometria” (o indice prestazionale) lo vedremo presto.
Il confronto tra i due PP può essere fatto solo paragonando i risultati ottenuti dai prodotti realizzati con essi.
Quando si hanno architetture diverse su stesso PP (vedesi per esempio le architetture AMD e NVIDIA sui processi produttivi precedenti con tutte le differenze che mostrano) abbiamo un confronto dei risultati che somma automaticamente tutte le differenze tra le architetture. Se il PP è il medesimo, non c’è alcun dubbio che le prestazioni migliori o peggiori di un prodotto rispetto ad un altro sia dovuto esclusivamente per come questo è stato disegnato e realizzato e quali compromessi si sono scelti (es. maggiori prestazioni a scapito di consumi o silicio usato o viceversa). Il confronto è quindi più semplice, anche tenendo conto del fatto che che i costi per mmq sono sostanzialmente uguali. Con architetture realizzate su PP diversi come nel caso delle ultime soluzioni di AMD e NVIDIA, la comparazione dei meriti, problemi o scelte strategiche sui compromessi ritenuti ragionevoli si fa più difficile perché le variabili da considerare sono maggiori; tale comparazione rimane comunque ricca di spunti di riflessione.
Abbiamo visto che la prima a realizzare un prodotto finito arrivato sugli scaffali con un processo produttivo post 28nm è stata TSMC con i suoi 16nm+ che sono una evoluzione ad alte prestazioni dei 16nm usati per la realizzazione di SoC ARM, tra cui gli A9 di Apple, a loro volta evoluzione con transistor FinFet (o 3D) dei 20nm planari sempre per SoC e mai evoluti a processo per circuiti ad alto consumo energetico, ovvero lo step che era necessario affinché Maxwell e GCN 1.2 fossero realizzati a nanometria inferiore rispetto a quella iniziale. A 20nm e alle frequenze richieste dalle GPU, pare che le dispersioni fossero tali da non permettere di realizzare circuiti così complessi con le giuste prestazioni.
Sarebbero dovuti girare a frequenze inferiori per non fondere, quindi con prestazioni che non ne giustificavano la spesa. Per quanto visto prima praticamente non si aveva un risultato conveniente a fronte dei soldi necessari a costruire nuovi chip, quindi il PP a 20nm è un processo produttivo che è stato scartato da entrambe AMD e NVIDIA. Come abbiamo sottolineato prima, le ragioni economiche hanno il loro peso per decidere se, come e quando realizzare una determinata soluzione. Questo è solo un chiaro esempio di questa importanza spesso trascurata a favore di lunghe discussioni e digressioni su numeri puramente tecnici ed astratti.
La new entry nel mondo delle GPU, Global Foundries, è arrivata in seguito con un processo a 14nm rivolto ai circuiti ad alte prestazioni preso in licenza da Samsung, evoluzione di quel 14nm FinFet usato anch’esso per la costruzione del SoC A9 di Apple, tra gli altri. L’evidenziazione che gli antenati degli attuali PP siano stati usati per realizzare entrambi il chip di punta della scorsa generazione di Apple non è casuale ma ci permette di fare una rara comparazione diretta, che ci consente di ottenere interessanti informazioni.
Lo stesso chip (su carta) realizzato con due differenti PP ovviamente esce dalle fabbriche con caratteristiche diverse proprie dei limiti che il PP impone (per tutto quello che abbiamo detto sopra). A produzione iniziata, la comparazione diretta dei chip immessi sul mercato dice che il SoC Apple realizzato con i 16nm di TSMC risulta essere il 10% più grande rispetto a quello realizzato con i 14nm di Samsung, ma (perché c’è un ma, altrimenti non ci sarebbe nulla di interessante in tutto questo lungo discorso :) ) il chip a 16nm sale in frequenza passando dalla modalità idle a quella pienamente operativa consumando meno corrente. Sembrerebbe il contrario di quanto detto prima, cioè che la miniaturizzazione aiuta ad aumentare la densità (e infatti i 14nm sono più densi dei 16nm) e a diminuire i consumi. Ma in questo caso i 16nm disperdono meno corrente dei 14nm. I test sugli A9 di Apple, alla frequenza massima imposta al SoC (che non è la massima assoluta di cui sarebbe capace), indicavano consumi più alti fino al 30% per il chip realizzato da Samsung. Come è questa storia vi chiederete?
Da quanto detto all’inizio, la nanometria è usata come indice prestazionale e vi sono moltissimi parametri che definiscono un processo produttivo: bisogna solo capire quali sono quelli usati per attribuirgli un numero piuttosto che un altro. Il confronto diretto ci permette di dire che Samsung ha messo più enfasi a indicare come il suo PP fosse più piccolo (quindi denso), mettendo in secondo piano il fatto che la tensione da applicare al transistor per farlo funzionare molto velocemente come un interruttore non sia proprio quella che la denominazione “14nm” potrebbe suggerire. A questo aggiungiamo che anche la dispersione di corrente (che dipende da molti fattori, non ultimo i materiali isolanti usati e la tensione stessa) sia parecchio alta.
Viceversa TSMC ha usato una numerazione più conservativa per via della minore densità possibile con il suo PP ma con prestazioni decisamente più alte per quanto riguarda correnti disperse e tensioni applicate, che sono decisamente più basse.
È chiaro ora che confrontare due PP usando solo la nanometria “suggerita” non sia così semplice come sembra. Fermarci al numerino del nome è un po’ come confrontare le prestazioni di due auto tenendo conto solo della loro cilindrata.
I dati a noi sconosciuti per una analisi completa sono il costo per millimetro quadro all’origine, cioè il costo di un wafer finito, e sopratutto le rese, che abbiamo visto definire i costi finali dei chip funzionanti. Quindi non sappiamo, al netto dei risultati prestazionali ottenuti, quale dei due PP sia più conveniente. Non di meno possiamo tentare di fare qualche analisi interessante.
4.1 Il confronto reale
Dopo tante chiacchiere, ecco il confronto tra i due nuovi PP usati da AMD e NVIDIA. Attenzione, non è un semplice confronto tra le prestazioni assolute ottenute dai prodotti realizzati con essi: è un confronto che cerca di determinare se e come questi PP siano uno migliore dell’altro (portando quindi evidenti vantaggi a chi lo adotta) e quanto entrambi siano migliori del precedente a 28nm. Inoltre, a fronte delle differenze che riscontreremo, cerchiamo di capire se alla fine uno dei due attori ha scommesso sul PP sbagliato per la produzione dei propri dispositivi. Ovviamente il confronto è imprescindibile dalle architetture che implementano, e questo è ovvio.
Ci aspettiamo comunque che i risultati ci possano suggerire quanto bene è stato fatto il lavoro per sfruttare al meglio i PP e quanto margine ancora eventualmente c’è di miglioramento per dei processi produttivi che non si prevede siano sostituiti tanto presto (anche se già si parla di 12nm nell’imminente e 7nm per il futuro); tali PP sono per esempio la base per l’architettura Vega di AMD che arriverà un anno dopo la commercializzazione della prima soluzione post 28nm (che significa che un anno dopo i 14nm sono ancora un PP su cui scommettere per il futuro, che significa che ci sarà abbastanza tempo prima di un nuovo PP per recuperare gli investimenti fatti su esso).
Abbiamo visto che la densità tra i due PP è diversa. E’ un parametro fisico del PP sul quale il design dell’architettura ben poco può fare, se non sfruttare i transistor in più a disposizione rispetto a quelli concessi alla concorrenza su PP meno denso per chip con uguale superficie. Non conoscendo il costo per millimetro quadro non possiamo però fare un analisi di costi e convenienza precisi. Però possiamo farci un’idea considerando che la differenza di densità non è alta (intorno al 10%).
Addentriamoci quindi un po’ più nei dettagli delle differenze di funzionamento delle GPU realizzate con tali PP.
La analisi più interessante risulta quelle sulle frequenze e i consumi che i vari prodotti mostrano. Sono due parametri correlati tra loro come abbiamo visto: in generale più alta la frequenza, più alti i consumi.
Ogni circuito complesso ha una curva caratteristica che indica quanto è il consumo a seconda di quale è la frequenza a cui lo si fa operare. È una curva all’inizio quasi lineare all’aumentare della frequenza fino ad un certo punto, dove diventa esponenziale, ovvero all’aumento minimo della frequenza vi è un corrispondente consumo di corrente molto più alto.
Normalmente i produttori cercano di porsi il più vicino possibile a questo punto di migliore efficienza, perché sotto di questo non ha senso perdendo prestazioni per un guadagno minimo in termini di consumo (sezione lineare della curva) e andando oltre invece si ha un enorme consumo con pochi benefici prestazionali (sezione esponenziale della curva). Il punto esatto dove porsi è dipendente dal target a cui il chip è destinato (maggiore efficienza o maggiori prestazioni assolute), ma non è mai troppo distante da quello ideale posto in prossimità del cambio di comportamento della curva. Allontanarsi troppo ha più controindicazioni che vantaggi.
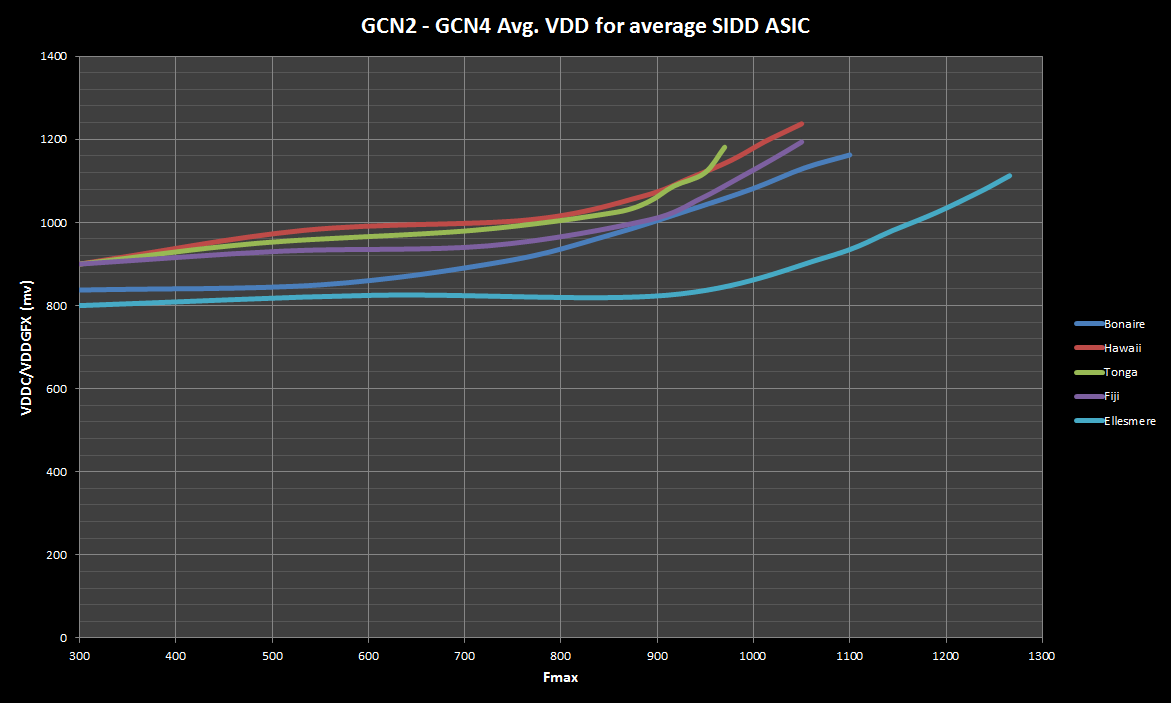
4.1.1 Frequenze
I due PP presi in esame (insieme alle rispettive architetture che come abbiamo già detto nel confronto tra prodotti fatti e finiti non si può fare a meno di considerare) permettono curve notevolmente differenti, e infatti vediamo come il processo produttivo di TSMC permette di avere un punto di maggiore efficienza intorno ai 1500MHz per le GPU NVIDIA (che guarda caso è la frequenza a cui è posto il GP100, la grande GPU destinata al mercato server HPC dove l’efficienza è molto importante) e quello di GF con l’architettura AMD invece ha un punto ottimale intorno ai 1000MHz.
Ovviamente entrambe le case hanno portato sul mercato consumer schede con frequenze superiori al punto di massima efficienza, perché in questo mercato le prestazioni sono più importanti dei consumi e qualche punto percentuale in più di prestazioni significa, per quanto detto prima, qualche dollaro in più di margine che per milioni di pezzi significano milioni di dollari. Per valutare meglio a che punto della curva le schede sono cloccate di default, valutiamo i risultati visibili con l’overclock, ovvero valutiamo le differenza applicando un delta di clock rispetto a quello di fabbrica: le schede NVIDIA salgono di frequenza fino a 2000MHz di massimo boost, vicino al fisico di stabilità dei transistor intorno ai 2100MHz, alla tensione massima che ha fissato senza che i consumi ne risentano particolarmente (crescita lineare).
Oltre, la crescita risulta meno lineare come si vede dal grafico. Per AMD il grafico mostra solo le frequenze di funzionamento standard. Prove condotte sull’overclock oltre i 1250MHz mostrano che le schede cominciano a consumare moltissimo. Polaris 10 da 1250MHz e 160W passa a 1350MHz e 220W (+8% OC +37% consumi).
Addendum dell’ultimo minuto: la nuova serie 500 dimostra quanto avevo già visto. Le nuove schede che portano le stesse identiche GPU Polaris 10 già montate sulla 480 a frequenze intorno ai 1400MHz, arrivano a consumare fino a 240W (+12% OC, +50% consumi!).

Abbiamo quindi che le GPU NVIDIA costruite con il processo produttivo di TSMC hanno una curva la cui parte esponenziale inizia molto più tardi rispetto alla frequenza applicata e la curva è molto meno ripida di quella delle GPU AMD costruite con il PP di GF.
Fortunatamente (ecco la sorpresa) abbiamo un’altra possibilità di confronto che ci è offerta dall’ultima GPU proposta da NVIDIA.
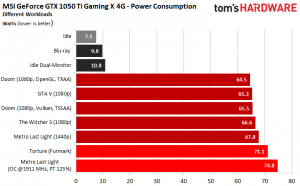
Il GP107 (montato sulle GTX1050/1050Ti) infatti a differenza di tutte le altre GPU di NVIDIA è fabbricata con lo stesso processo produttivo a 14nm licenziato a GF da Samsung, ma nelle fabbriche di Samsung.
La piccola GPU di NVIDIA di 132mmq, comparabile a Polaris 11 per numero di transistor integrati, raggiunge i 1800MHz rimanendo sotto i 65W contro i 1200MHz della concorrente a 75W. All’aumentare del clock i consumi di quest’ultima salgono enormemente, tanto che aumentare il clock di boost di soli 50MHz equivale a aumentare i consumi di ben 15W.

Da notare come le frequenze di riferimento siano riportate in maniera diversa dalle due aziende: AMD indica il valore del boost massimo oltre la quale la scheda non va, NVIDIA invece dichiara sia il clock base minimo sia il valore più basso a cui il boost si porta, lasciando in verità che siano le condizioni di temperatura e alimentazione a determinare il valore massimo di frequenza a cui la scheda può spingersi, valori molto più alti anche di quelli di boost dichiarato. Così, nei nostri esempi, la 1050Ti si spinge fino a 1800MHz di boost rimanendo nei consumi imposti di 66W.
È evidente che le frequenze per la GPU AMD siano già poste ben oltre il punto di massima efficienza che abbiamo descritto prima, se per un overclock del 5% abbiamo un aumento dei consumi del 20%: siamo già sulla parte alta della curva esponenziale, come abbiamo visto anche per Polaris 10.
La GPU di NVIDIA invece è su un punto completamente diverso della sua curva. La frequenza a cui la scheda è posta, è limitata solo per poter funzionare senza connettore ausiliario (lo slot PCIe può erogare al massimo 66W o 5.5A a 12V da specifica). Liberata da questo limite commerciale la GPU può superare i 1900MHz a 75W, come si vede con le versioni custom della 1050Ti dotate di connettore ausiliario.
4.1.2 Tensioni
Confrontiamo le tensioni applicate da AMD e NVIDIA ai diversi PP usati per cercare una relazione tra frequenze e consumi dovuti al PP stesso.
Il sito techPowerUp offre molte informazioni a riguardo ed è da lì che provengono tutti questi grafici.
Le tensioni di alimentazione sono direttamente responsabili dei consumi dei chip, quindi le ziende tenderanno a tenerle più basse possibili. Viceversa, più alte sono le tensioni, più velocemente può commutare un transistor, quindi andare a frequenze maggiori. Quindi le aziende teneranno di applicare le maggiori tensioni possibili.
Siccome le due cose non sono ovviamente compatibili, si raggiunge un compromesso che è quello che si trova nel punto di maggiore efficienza visto precedentemente, dove la tensione è la migliore sia per i consumi che per le frequenze (ovvero le performance).
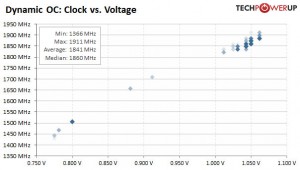
Tensioni applicate per i due PP da NVIDIA:
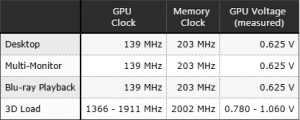
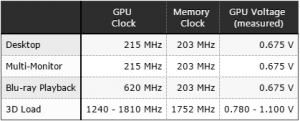
Vediamo come i valori per i 14nm Samsung siano più elevati che per i 16nm TSMC sia a bassa che ad alta frequenza.
La tensione massima per i 14nm Samsung è di 1.100V per raggiungere i 1800MHz.
la tensione massima per i 16nm di TSMC è di 1.050V per raggiungere i 1900MHz.
Vediamo per curiosità i grafici delle frequenze a seconda della tensione applicata, valori gestiti automaticamente dal BIOS della scheda che qui sono stati solo registrati:
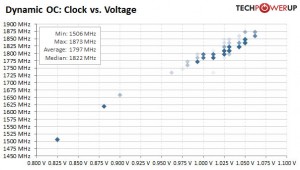
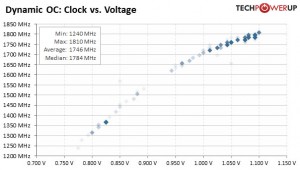
Tensioni applicate da AMD ai 14nm di GF
Vediamo che le tensioni a bassa frequenza rimangono più alte di quelle usate da NVIDIA sul PP di Samsung.
Per la 460 la tensione massima rimane simile a quella di NVIDIA con la GPU che raggiunge i 1270MHz
Per la 480 la tensione massima è invece inferiore a quella usata da NVIDIA sui 14nm con la GPU che raggiunge le stesse frequenze della 460.
Per dare un senso a questi grafici in poche parole, i numeri sono questi:
a 1.0V le GPU di AMD raggiungono i 1200MHz circa mentre quelle di NVIDIA, sia su PP di TSMC che su quello Samsung, arrivano a 1700MHz.
4.1.3 Conclusioni
Abbiamo quindi uno scenario con diverse informazioni sparse da analizzare.
NVIDIA, valutabile sia sul processo a 16nm di TSMC sia sul processo a 14 di Samsung (gemello di quello di GF):
- sui 16nm è in grado di arrivare oltre ai 2000MHz senza creare una fusione nucleare delle sue GPU e non le serve alzare la tensione a livelli stratosferici.
- sui 14nm è in grado di arrivare a 1900MHz con un delta di pochi W (lineare) rispetto a girare a 1400MHz. La tensione applicata rimane comunque più elevata rispetto a quella usata dal processo di TSMC, testimonianza che i due PP hanno molte più differenze rispetto a quanto il “numerino” che dà loro il nome suggerisce.
AMD, valutabile solo sul processo a 14nm di Global Foundries
- sui 14nm raggiunge frequenze non più alte di 1300MHz, oltre le quali i consumi letteralmente esplodono (last minute: testimonia la cosa la nuova serie 500 di AMD cloccata a oltre 1400Mhz).
- le tensioni sono simili a quelle usate da nvidia per i 14nm e solo marginalmente superiori a quelle usate per i 16nm (anche se in teoria dovrebbero essere inferiori).
Abbiamo visto uno scenario simile anche con il precedente PP che era comune ad entrambe: NVIDIA raggiungeva frequenze più alte di quelle AMD con consumi inferiori (a pari prestazioni).
Facendo una rapida analisi sembra che il problema principale per AMD non sia il processo produttivo (che ha la sua influenza comunque), ma bensì l’architettura (o come è realizzato il layout per la sua implementazione). Sia con i 28nm che con i 14nm, su 2 PP differenti le frequenze non si sono alzate molto (dai 1000MHz ai 1300MHz, +30%) e l’efficienza di Polaris è molto lontana da quella che ci era stata promessa (2.5x quella di GCN) pur AMD non avendo “tirato” i chip a frequenze elevate come ha fatto NVIDIA.
Di contro quest’ultima che già partiva da una situazione con frequenze più alte (1300MHz di base per Maxwell) è riuscita a portarle ancora più in alto vicino ai 2GHz (+50%) mantenendo i consumi perfettamente sotto controllo e quindi sfruttando questo vantaggio per creare chip più piccoli con frequenza maggiore a discapito dell’efficienza che rimane comunque migliore di quanto già non fosse quella ottima di Maxwell anche se non ai 2x promessi da NVIDIA, almeno non sulle schede consumer.
Ecco che abbiamo visto che a seconda dei vantaggi che si hanno a disposizione è possibile scendere a compromessi diversi per ottenere prodotti con le stesse prestazioni originariamente pianificate. Silicio contro frequenze, frequenze contro consumi. Questi ultimi sono quindi importanti per poter dare più margine di manovra alla strategia che l’azienda vuole perseguire. Con consumi inferiori abbiamo visto che c’è possibilità di risparmiare ulteriormente rispetto ad aumentare le prestazioni moltiplicando le unità di calcolo e quindi usando più silicio.
Ribadiamo che qui non si fa una comparazione diretta tra le due architetture in termini di prestazioni per Hz. Che è una cosa senza senso come molti sanno. Si fa un confronto tra la capacità di guadagnare prestazioni per le frequenze permesse dal nuovo PP (che è abbiamo detto essere una caratteristica importante per l’aumento di prestazioni nei PP nuovi) e di posizione sulla curva di efficienza (che indica quanto ci si è spinti oltre quello che sarebbe dovuto essere il target, ovvero il punto di massima efficienza più qualcosina) in circuiti dalla dimensione simile.
Questa semplice e superficiale analisi effettuata pone alcuni dubbi sul lavoro che AMD ha fatto su Polaris, quasi a significare che non ci abbia investito molto (di fatti è più che altro uno shrink di GCN) mentre la lunga attesa per quella che dovrebbe essere la nuova architettura Vega potrebbe far pensare (e sperare) che i risultati per questa siano completamente diversi.
Anche questo articolo è stato scritto in un lasso di tempo abbastanza lungo durante i quali sempre più fatti hanno confermato l’analisi, non ultimo il rilascio della serie 500 di AMD con le sue frequenze innalzate per ulteriori consumi extra, come se i precedenti non fossero sufficienti, ma a quanto pare come dicevo all’inizio di tutto, l’importanza (e il guadagno) di qualche punto percentuale di prestazioni in più è maggiore dei disagi che i maggiori consumi comportano. Vedremo se questa politica premierà la strategia di AMD. Quello che rimane una sicurezza è che questa mossa non aiuterà Polaris a entrare nel mercato mobile.







