L’avvento degli anni ’90 sembra dare una scossa concreta al settore dei microprocessori CISC, che con l’introduzione e la diffusione delle architetture di tipo RISC hanno subito un duro colpo relativamente a prestazioni, costi e consumi.
Apre le danze Intel nell’89 col suo 80486 (di cui parleremo in qualche futuro articolo), realizzando una CPU in grado di erogare ben 15 MIPS (e 1 MFLOPS) a 25Mhz: numeri da fantascienza se consideriamo la sua complicata ISA, che si porta dietro la famigerata e mai abbastanza indigesta retrocompatibilità x86.
Motorola, che è solita marcare stretta la grande rivale, si presenta l’anno successivo con un gioiello tecnologico che riesce a fare molto meglio: 20 MIPS (e 3,5 MFLOPS) a 25Mhz. Quasi un’istruzione per ciclo di clock per un 68040 che conta 1,17 milioni di transistor: più di 4 volte quelli del suo predecessore, il 68030 (di cui abbiamo parlato nel precedente articolo).
Numeri da RISC, insomma, anche se questi ultimi continuano ad avere la meglio sui consumi. Ma il tabù della velocità appannaggio dei RISC comincia a vacillare, e il segnale è forte: i CISC posso finalmente dire la loro. Infatti uno dei più quotati RISC dell’epoca, lo SPARC v7, alla stessa frequenza veniva dato per 16 MIPS (e 2,6 MFLOPS), e costava più del doppio.
Ovviamente MIPS e MFLOPS di per sé non vogliono dire nulla, visto che si tratta di architetture completamente diverse e le prestazioni è meglio valutarle sul campo, con le applicazioni reali. Al solito, si tratta di numeri buoni per il marketing, ma certamente fa impressione vedere cifre così elevate accostate a dei CISC, specialmente in un’epoca in cui i RISC davano battaglia e infliggevano umiliazioni a colpi di MIPS (per non parlare dei MFLOPS).
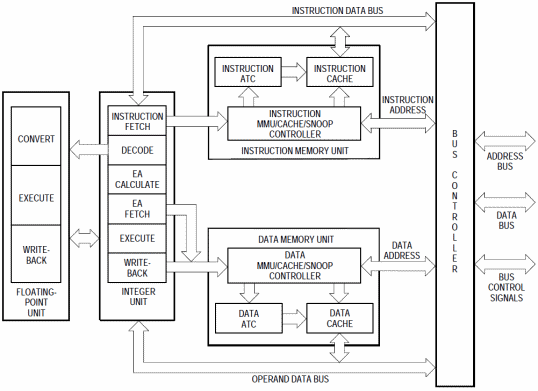
Tutto ciò è frutto del sapiente lavoro di Motorola, che con questa CPU ha introdotto un’architettura completamente Harvard con la cache istruzioni e dati completamente indipendenti (avendo ognuna un’MMU associata), una pipeline intera a 6 stadi e una in virgola mobile a 3:
Mentre col 68030 la singola MMU doveva occuparsi della traduzione di tutti gli indirizzi, le due presenti adesso provvedono separatamente e in maniera del tutto indipendente e parallela all’operazione per gli indirizzi delle istruzioni e dei dati.
Infatti ognuna presenta due master page table (una per le pagine della modalità utente, e una per quella supervisore), registri di controllo, una coppia di registri per la traduzione trasparente di due aree di memoria e 64 elementi nell’Address Translation Cache (ATC) che memorizzano gli ultimi 4 indirizzi virtuali tradotti.
In realtà proprio sulle MMU si registrano le maggiori differenze rispetto al suo predecessore, e non si tratta di scelte positive. Mentre in precedenza era possibile utilizzare la stessa master page table per la modalità utente e quella supervisore, oppure usarne due diverse, adesso quest’ultima è l’unica via.
Viene meno anche l’enorme flessibilità garantita dalla possibilità di poter definire arbitrariamente da 1 a 4 livelli per gli alberi di traduzione, e pagine di dimensione variabile da 256 byte a 32KB. Col 68040 ci sono solo 3 livelli fissi e le pagine possono essere soltanto di 4 o 8KB; sparisce anche qualche caratteristica minore, come pure alcune istruzioni (ne sono rimaste soltanto due: PTEST e PFLUSH).
Fortunatamente permane la possibilità di utilizzare un meccanismo di indirezione (di cui non avevo parlato in precedenza; ne approfitto adesso per farlo) per i descrittori di pagina, oppure per le page table, che ne consente la condivisione fra più task (o processi che dir si voglia):
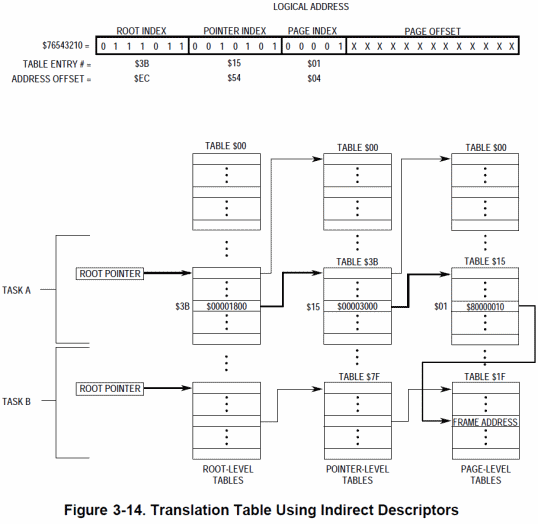
Molto utile per risparmiare memoria e facilitare la condivisione di codice e/o dati.
Sono, inoltre, presenti due bit che implementano la Physical Address Extension (PAE; sigla che ricorda un’estensione analoga che Intel introdurrà soltanto coi PentiumPro) e che il processore riporta sul bus esterno assieme alle linee d’indirizzo; quindi possono servire per estendere lo spazio d’indirizzamento della memoria oltre i canonici 4GB (fino a 16GB, per la precisione) o per altri usi. Anno: 1990, ed è bene rimarcarlo.
I tagli non sorprendono e non devono deludere: si tratta sicuramente di un compromesso necessario per semplificare le due MMU senza aumentare troppo i costi e la complessità del chip (che per l’epoca era un autentico mostro). D’altra parte bisogna ricordare che la gestione di queste unità generalmente è a carico del sistema operativo e non delle applicazioni, per cui questi cambiamenti non sono direttamente percepibili.
Sempre rispetto al 68030, le cache sono state portate ciascuna da 256 byte a 4KB, per un totale di 8KB. E’ cambiata la loro organizzazione (associativa a 4 vie), in quanto adesso sono suddivise in 64 insiemi da 4 linee ciascuna, con ogni linea che, come in precedenza, contiene fino a 4 longword.
Una così elevata quantità di cache consente di ridurre sensibilmente l’accesso al bus, ottimizzando l’uso della banda di memoria e riducendo al contempo la latenza per la lettura dei dati. Per quanto riguarda la scrittura, è presente la modalità write-through, ma rispetto al passato è disponibile anche la nuova copyback, la cui implementazione ha richiesto una modifica nel formato delle linee della sola cache dati:
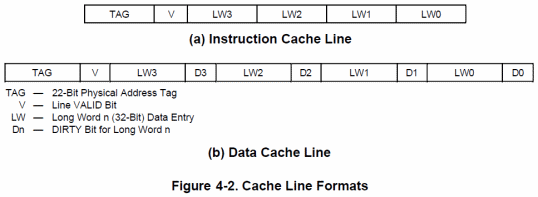
Il concetto è che le operazioni di scrittura non comportano automaticamente la memorizzazione dei dati, oltre che nella cache, anche nella memoria esterna, come avviene usualmente. I dati scritti in cache, ma non ancora copiati in memoria, vengono marcati con un bit chiamato dirty.
La scrittura avviene soltanto a seguito di particolari condizioni, come ad esempio per la sostituzione della linea di cache in cui risiedono (perché è diventata “vecchia” e dev’essere rimpiazzata con una nuova), oppure in maniera programmatica (tramite l’uso di apposite istruzioni che invalidano la linea). In questo modo c’è un notevole risparmio di banda di memoria, perché gli accessi vengono accorpati e, ove possibile, sfruttato il veloce burst mode per i trasferimenti (in precedenza era utilizzabile soltanto in lettura).
Burst mode che trova la sua incarnazione nella nuova (e unica) istruzione MOVE16 che, come suggerisce il nome, è in grado di spostare (copiare, in realtà) 16 byte alla volta, ovviamente a indirizzi multipli di 16 (cioè 4 longword, o una linea di cache).
Ma a fare la parte del leone è, manco a dirlo, la nuova pipeline a 6 stadi che rappresenta un grosso passo in avanti rispetto a quella a 3 stadi del 68030, in quanto il lavoro complessivo necessario per portare a termine l’esecuzione di un’istruzione consente una maggior parallelizzazione delle operazioni interne, e una più efficace loro sovrapposizione.
Per essere più chiari, questo significa che il calcolo dell’indirizzo dell’operando da prelevare dalla memoria non rappresenta più un collo di bottiglia, come nel suo predecessore, in quanto adesso viene effettuato in un apposito stadio. Quindi in quello successivo, che si occupa di recuperare effettivamente il dato, l’indirizzo è già disponibile e il controller della memoria può verificare se è presente in cache oppure recuperarlo dalla memoria.
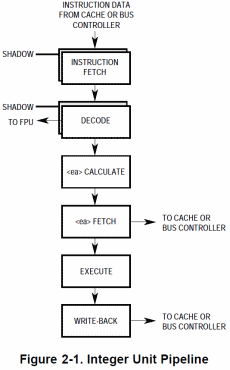 Da notare la presenza di due stadi “nascosti”, denominati shadow, che consentono di eseguire rispettivamente il fetch e la decodifica della futura istruzione da eseguire a seguito di un salto condizionato. In un flusso normale, le istruzioni vengono eseguite una dopo l’altra e, quindi, nel momento in cui la CPU sta completando l’esecuzione dell’istruzione “corrente”, nella pipeline sono presenti le successive 5 istruzioni parzialmente in lavorazione.
Da notare la presenza di due stadi “nascosti”, denominati shadow, che consentono di eseguire rispettivamente il fetch e la decodifica della futura istruzione da eseguire a seguito di un salto condizionato. In un flusso normale, le istruzioni vengono eseguite una dopo l’altra e, quindi, nel momento in cui la CPU sta completando l’esecuzione dell’istruzione “corrente”, nella pipeline sono presenti le successive 5 istruzioni parzialmente in lavorazione.
La “magia” (e, soprattutto, le prestazioni) si spezza a seguito dei famigerati salti, e in particolare di quelli che non sono prevedibili, in quanto la diramazione avviene soltanto se si verifica una certa condizione. In questo caso la pipeline dev’essere “svuotata” (come si dice in gergo), cioè tutto il lavoro fatto per le rimanenti istruzioni va annullato e dev’essere “riempita” ripartendo dall’inizio, quindi caricando la prima istruzione utile da eseguire, e così via. In genere la penalizzazione in cicli di clock è pari al numero di stadi della pipeline, ma ciò dipende strettamente dall’implementazione.
Nello specifico, un salto non prevedibile che fa variare il flusso dell’esecuzione dovrebbe richiedere 6 cicli di clock (0 se il flusso non venisse interrotto). Col meccanismo degli stadi shadow, invece, si ha soltanto 1 ciclo di clock di penalizzazione (2 se il salto non avviene), in quanto nella pipeline l’istruzione obiettivo del salto risulta già parzialmente “lavorata”.
Ricapitolando, un salto taken (sempre come si dice in gergo) richiede 2 cicli di clock, mentre se not taken ne prende 3. Tutto sommato si tratta di un buon compromesso (2 / 3, molto più bilanciato di un 6 / 0), in quanto questo microprocessore non è dotato di alcuna logica di predizione dei salti, per cui un salto condizionato in linea teorica ha la stessa probabilità di cambiare il flusso oppure no (in realtà sono leggermente avvantaggiati i salti taken, che richiedono soltanto 2 cicli di clock).
Cambiamenti significativi sono presenti anche nella logica d’interfacciamento col bus esterno. Il 68040 non è in grado, ad esempio, di variare dinamicamente la dimensione del bus rispetto a quella della “porta” (memoria o dispositivo di I/O) con cui sta comunicando.
In altre parole, se esegue un accesso richiedendo un dato di una certa dimensione, la corrispondente porta deve fornirlo della medesima dimensione (prima, invece, CPU e porta si “accordavano” e provvedevano, eventualmente, a eseguire più accessi per soddisfare la richiesta iniziale). Comunque per sistemi che hanno bisogno del precedente meccanismo, Motorola ha realizzato un chip che ne emula il funzionamento.
A fronte di una caratteristica in meno, ne arriva un’altra nuova e decisamente più interessante: lo snooping dei dati. Entrambi i controller della memoria (quello delle istruzioni e quello dei dati) monitorano continuamente il bus analizzando gli accessi effettuati dagli altri dispositivi, ricavando l’indirizzo e controllando se appartiene a uno di quelli presenti nella cache.
Se il risultato è positivo, si tratta di un’operazione di lettura (da parte del dispositivo), e nella cache è presente un dato aggiornato, l’accesso al bus viene bloccato dal processore che provvede egli stesso a fornire il dato al richiedente. Se invece l’operazione è di scrittura, la cache viene aggiornata col nuovo dato che viene successivamente immesso nel bus dalla periferica.
Inutile dire che in ambienti multiprocessore un meccanismo del genere è un’autentica manna dal cielo, visto che consente di interfacciare più CPU o dispositivi con relativamente poca logica (e quindi usando chipset più semplici ed economici), mantenendo la coerenza dei dati nelle rispettive cache.
Altro pezzo forte di questo microprocessore è l’FPU, che adesso si trova integrata e risulta particolarmente veloce. Infatti, com’è possibile vedere dal diagramma interno che si trova all’inizio dell’articolo, quando la logica di decodifica si accorge di essere in presenza di un’istruzione per il coprocessore matematico, la passa immediatamente alla relativa pipeline, che provvede a elaborarla in maniera indipendente dal flusso delle istruzioni (salvo in caso di eccezioni sollevate o dipendenza dei dati).
Purtroppo, come per le MMU, sono stati apportati dei “tagli” a quest’unità, che non permette di utilizzare il formato packed BCD e supporta soltanto un ristretto insieme di operazioni (soltanto quelle più comuni):
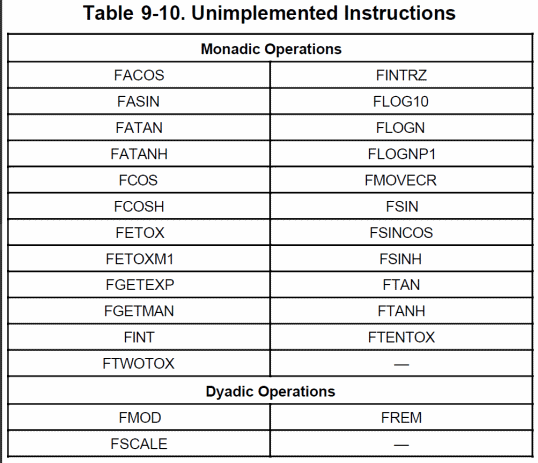
Si tratta si scelte dolorose, ma condivisibili alla luce dei risultati. Il 68040, infatti, eroga 3,5 MFLOPS: più di 10 volte rispetto al coprocessore 68882 di pari frequenza (che arriva a poco più di 0,5 MFLOPS nella sua versione più veloce), e Motorola garantisce che l’emulazione delle istruzioni mancanti, tramite un’apposita libreria che fornisce, risulta mediamente più veloce.
Qui è bene fare una riflessione. A differenza di Intel, che s’è trascinata dietro qualunque aspetto delle varie versioni dell’ISA x86 che si sono succedute nel tempo, Motorola con la sua famiglia 68000 ha deciso, a partire dal 68030, di sacrificare l’assoluta compatibilità col passato in cambio di un’architettura che le rendesse la vita più facile (ed economica) nella corsa alle prestazioni.
Si giustifica in questo modo l’eliminazione del supporto ai “moduli” (istruzioni CALLM/RTM) introdotto col 68020, ma defenestrato già col modello successivo, e il sottoinsieme di funzionalità implementato nell’MMU integrata del 68030. Il 68040 rimarca il concetto, con delle MMU ancora più semplificate e incompatibili, un’FPU a cui mancano diversi pezzi, e alcuni “stack frame” (di cui abbiamo parlato nell’articolo sul 68020) che sono stati eliminati (e altri, nuovi e più semplici, aggiunti).
Da programmatore sono scelte che non condivido, perché l’ISA rappresenta una sorta di “contratto” che il produttore della CPU stipula con chi la dovrà programmare, e chi sviluppa software si aspetta che, tenendo conto delle debite circostanze, possa girare su qualunque modello della famiglia. Per contro, da utente mi aspetto prestazioni sempre più elevate.
Raggiungere le prestazioni, però, richiede compromessi che a volte sono difficili da realizzare e/o digerire. Guardando al 68040 sembra che, tutto sommato, si possa chiudere un occhio davanti ai favolosi 20 MIPS che eroga a 25MHz. Tanto tutte le cose che mancano possono venire emulate, a quanto sembra. Peccato che ciò possa avvenire soltanto in presenza di un sistema operativo. aggiornato che provveda a riconoscere la CPU su cui gira, intercettare le eccezioni scatenate dalle istruzioni mancanti, e a provvedere di conseguenza.
Questo, però, non è sempre possibile. Presuppone l’aggiornabilità del s.o., condizione che non sempre si può verificare: basti pensare a quelli che risiedono su ROM, com’era molto comune all’epoca. Peggio ancora, presuppone la presenza di un s.o. e, sembrerà assurdo, anche questo non è affatto garantito!
Chi ha sviluppato giochi per Amiga sa che la stragrande maggioranza di essi “uccideva” il s.o., per impadronirsi poi di tutte le risorse del sistema, tabella delle eccezioni inclusa. Dunque i pezzi che mancano in questi casi non possono essere sostituiti in maniera trasparente, quindi se c’è qualche porzione di codice che fa uso di qualcuna delle caratteristiche assenti, semplicemente… non girerà. Con buona pace dei propositi di Motorola.
A ciò aggiungiamo che, manuale utente alla mano, la realtà risulta ben diversa. 20 MIPS a 25Mhz significa eseguire quasi un’istruzione per ciclo di clock, ma le tabelle degli opcode mostrano tutt’altro scenario. Anzi, si arriva tranquillamente a decine di cicli di clock per alcune istruzioni particolarmente “complesse”.
Motorola ha, dunque, mentito? Non esattamente. La situazione è simile a quella di tanti altri microprocessori, come lo SPARC v7 di cui parlavo prima che, essendo RISC, dovrebbe eseguire anch’esso le istruzioni in più o meno 1 ciclo di clock. Sono soltanto le istruzioni più “semplici” a godere di questa proprietà.
Poiché spesso sono anche le più comuni, ecco spiegato il perché di quei 20MIPS. Certo, dipende sempre dall’applicazione, perché il codice in giro è piuttosto variegato, per cui ci si affida a stime, basate magari sull’analisi degli opcode che si trovano nei software più comuni e utilizzati.
Ad esempio, se avessero dovuto fare i conti con l’emulatore 80186 che avevo scritto per gli Amiga dotati almeno di un 68020, quel numero sarebbe stato decisamente più basso, a causa delle istruzioni “esotiche” e delle modalità d’indirizzamento indirette che utilizzavo massicciamente.
Ma un’applicazione scritta in assembly e ottimizzata accuratamente a manina non è un campione rappresentativo, specialmente perché la tendenza è stata quella di affidarsi ai compilatori di linguaggi ad alto livello, che non possono prevedere l’impiego di qualunque caratteristica anche oscura che l’ISA di un processore può mettere a disposizione, se ciò non è riconducibile a pattern predefiniti (da chi ha scritto il compilatore).
Una ricerca delle migliori combinazioni di opcode basata sulla forza bruta non sarebbe proponibile, perché i pattern da testare arrivano anche a miliardi per piccolissime porzioni di codice. Né è ipotizzabile, almeno al momento, un sistema che riesca a comprendere l’algoritmo che ha implementato il programmatore, e tirare fuori trucchetti “fantasiosi” (come, ad esempio, quello menzionato dal lettore pleg nel commento #17 a un precedente articolo) per sfruttare il più possibile ciò che la CPU offre.
Il risultato è che i compilatori difficilmente riescono a tirare fuori istruzioni rare e/o complesse, per cui il codice generato sarà abbastanza semplice da essere velocemente digeribile dal microprocessore su cui girerà.
In definitiva la via rimane quella tracciata dai RISC: accelerare il più possibile le istruzioni più “semplici” e comuni, tagliando o non sprecando risorse per fare lo stesso con le altre. Motorola ne era cosciente, ed è per questo che, nonostante il 68040 sia il rappresentante di una delle famiglie “più CISC”, riesce a ottenere mediamente prestazioni molto elevate.
Col successivo 68060 la linea rimane la stessa, ma vedremo che, purtroppo, sarà destinata a interrompersi bruscamente…







