Dopo aver passato in rassegna le varie fasi della “costruzione” delle geometrie di una scena 3D ed aver visto come avvenga la transizione da uno spazio di oggetti tridimensionali ad uno a due sole dimenzioni, ovvero il nostro monitor, adesso vediamo qualche implementazione pratica
Poichè, per semplicità di trattazione, si era fatto riferimento ad una generica pipeline 3D, al momento lasciamo da parte le directX10 e gli shader unificati e iniziamo dalle architetture a shader dedicati; anzi, per la precisione, partiamo dalla Fixed Function Pipeline, quella tipica delle dx7, per intenderci, ricordando che, prima di allora, le operazioni di illuminazione e trasformazione erano interamente a carico della CPU.
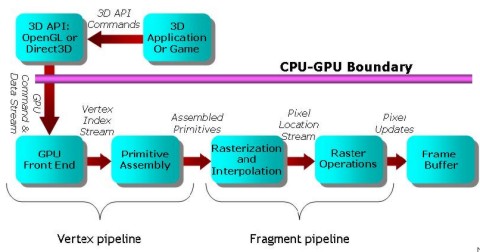
Poichè si è già diffusamente parlato del funzionamento dei singoli stadi di una FF pipeline, mi limito a postarne l’immagine per rinfrescare la memoria a qualcuno e dare la possibilità di fare un confronto immediato con la pipeline di tipo programmabile.
in cui quella che è definita come vertex pipeline, andando più in dettaglio, si può schematizzare come segue

dove la vertex pipeline è composta da tutti i blocchi di colore giallo, per la cui funzione rinvio a questo articolo ed ai due seguenti.
Una FF pipeline ha un set fisso di funzioni che consente un uso limitato e vincolante delle operazioni di trasformazione ed illuminazione.
Al contrario, una pipeline di tipo programmabile, sempre tenendo conto dei limiti dell’hardware su cui si lavora, permette una libertà pressochè totale. Da qui, l’importanza dell’introduzione delle funzioni di pixel e vertex shading e delle unità fisiche, presenti sulla GPU, che hanno finito con l’assumere lo stesso nome degli algoritmi su cui erano destinate ad operare.

La pipeline raffigurata qui sopra potrebbe schematizzare, ad esempio, quella reale dell’R200, oppure quella delle nVidia NV20 ed NV25, ma anche, ad esempio, quella dell’NV30 e derivati, su cui erano state mantenute le fixed fuction unit per le operazioni geometriche. NV20, noto come Geforce 3, è stato il primo chip ad adottare questo tipo di soluzione con pipeline di tipo programmabile e, pur condividendo formalmente la stessa architettura di base, con 4 pipeline capace ciascuna di applicare 2 texel per pixel per ciclo, presentava, rispetto alla generazione precedente, delle differenze sostanziali dettate dall’adozione del nuovo shader model (PS1.1 e VS1.1) che prevedevano, ad esempio, la possibilità di applicare fino a 4 texture per pass (contro le 2 delle dx7) e l’utilizzo di precisione INT12 per le operazioni di pixel shading ed FP32 per quelle di vertex shading, dove INT sta per Integer e FP per Floating Point (le dx7 si fermavano a 4 o 8 bit INT per canale). Altra grossa novità, vista per la prima volta su NV20, il Memory Controller (MC) di tipo crossbar (ne vedremo più avanti un esempio).
Il primo chip ad abbandonare completamente delle FF unit di tipo fisico, invece, è stato l’R300 di ATi, di cui riporto lo schema a blocchi e qualche dettaglio.

R300 schema a blocchi
Anche R300 introduce diverse novità: innanzitutto è il primo chip dx9, Shader Model 2.0, il che significa, ad esempio, che è in grado di applicare fino a 16 texture per pixel per pass, utilizzando, al pari dei chip dx8, come R200, NV2x e, come faceva anche il Kyro di PowerVR, dei buffer di tipo FIFO con dei texture combiner che permettono di immagazzinare i risultati delle operazioni di texturing ottenuti ad ogni ciclo. Tecnicamente, un’operazione è eseguita in un singolo ciclo se il tempo necessario a portarla a compimento è pari ad un ciclo del clock interno del microprocessore; si definisce, invece, eseguita in single pass se per portarla a termine non è necessario fare accessi al frame buffer esterno, ovvero quello sulla ram video. Quindi, è possibile esegiore in single pass operazioni che richiedono più cicli facendo uso di cache o buffer interni o di registri temporanei in cui accumulare o immagazzinare i risultati intermedi. Altra grossa novità, a livello macroscopico, è l’abbandono dell’architettura 4×2 vista con R200 per ATi e con NV15, NV20 ed NV25 per nVidia (architettura che sarà riproposta anche su NV30). Un cenno ai vantaggi di questa scelta si può trovare qui.
Un’altra novità, dettata unicamente dalle specifiche dello SM2.0, l’adozione, per molte delle operazioni di pixel shading, della precisione fp24. Se R200 ed NV20 avevano una unità di vertex shading, che diventavano 2 su NV25, affiancate dalle FF unit, R300 arriva ad avere 4 unità di vertex shading che, per di più, al pari delle unità di pixel shading, presentano anche un’architettura particolare. Ma entriamo un po’ nel dettaglio, iniziando a proporre il bus di tipo crossbar, il primo a 256 bit, ripreso da quello a 128 di NV20.

Come si vede, ci sono 4 MC ognuno dei quali controlla un canale bidirezionale a 64 bit (32+32) che mette in comunicazione la GPU ocn la VRAM. Al centro, c’è uno SWITCH che permette di indirizzare le richieste da uno qualunque dei 4 MC a qualsiasi banco di ram. Ogni MC è dotato di un ARBITER che si occupa di gestire il traffico da e verso la GPU. L’arbiter opera in modalità Out of Order (OoO) ed è programmato a basso livello per privilegiare le operazioni relative alle elaborazioni 3D rispetto a tutte le altre che possono richiedere un accesso alla VRAM da parte della GPU. Ovviamente, anche all’interno delle operazioni relative al 3D, esistono delle priorità che, solitamente, sono assegnate tenendo in debito conto l’architettura della GPU.
Torniamo allo schema a blocchi dell’R300, in cui segnalo un errore relativo alla connessione del blocco denominato Hyper-z III che non riceve i dati dalla VRAM ma al termine delle operazioni di vertex shading. L’hyper-z III non è altro che un insieme di feature atte ad effettuare operazioni di HSR prima del rendering e dell’eventuale applicazione del MSAA box
Passiamo alle unità di Vertex Shading

Qui si vedono le 4 vertex pipeline con il collegamento, stavolta posizionato correttamente, relativo all’hyper-z.
Nel dettaglio si ha

In questo schema sono riportate tutte le operazioni che abbiamo già visto essere necessarie per la “costruzione” di un’immagine 3D e, nella parte alta, lo schema delle ALU (Arithmetic Logic Unit) di R300. La particolarità di queste ALU è che sono composte da una unità di tipo full vect4, ovvero un vettore completo a 128 bit (formato da 4 unità scalari fp32) affiancato da una unità fp32 scalare. Anche se le unità sono di tipo co-issue, ovvero lavorano su dati appartenenti allo stesso thread, questa configurazione consente una maggior flessibilità e, in alcuni casi, garantisce una capacità elaborativa superiore rispetto alle unità, fino ad allora classiche, di tipo full vect4, sia per i PS che per i VS (presenti su R200 e su tutti i chip nVidia fino ad NV3x e derivati compresi).
Questo tipo di architettura per le unità geometriche sarà ripresa da nVidia con NV40 e G70 di cui riporto lo schema di un singolo VS

Come si può vedere, lo schema è formalmente identico a quello di R300, con una unità full vect4 affiancata da una fp32. In aggiunta, per la compatibilità con lo SM3.0, ci sono una unità di dynamic branching in serie alle unità di vertex shading (ATi, con R5x0 sceglierà di metterla in parallelo) ed una unità di vertex texture fetch per permettere le operazioni di vertex texturing.
Passiamo alle unità di pixel shading: anche qui, ATi propone uno schema con 2 unità affiancate ma, stavolta, all’unità scalare fp32 è affiancata una unità di tipo vect3. Questo perchè, al contrario delle operazioni geometriche, in quelle di pixel shading è molto più raro avere a che fare con vettori completi nello spazio omogeneo. Quindi, qualora si debba operare su un vettore completo (x, y, z, w) l’unità scalare va ad affiancare la vect3 completando il quartetto. In caso contrario, le modalità con cui la alu può operare sono 3+1, 2+1 e 1+1; ovviamente, negli ultimi due casi, 1 o 2 alu fp32 restano, rispettivamente, inattive nell’esecuzione di quella particolare istruzione. Non è il massimo ma rappresentava un passo avanti riapetto alla configurazione con alu full vect4.

In realtà, nello schema sopra indicato manca una seconda alu, in serie alla prima, la cui architettura è identica alla alu principale, ovvero 3+1, ma che è in grado di svolgere solo alcune funzioni limitate (le alu principali si possono schematizzare come MADD, ovvero in grado di compiere, in un solo ciclo, un’operazioni di moltiplicazione ed una di addizione, mentre quella secondaria, in questo caso, è una MUL, ovvero capace di compiere una moltiplicazione. Ovviamente non ci si limita solo a questo, ma questa schematiuzzazione serve per far capire che si tratta di unità di tipo differente).
Questo schema sarà superato, a livello di flessibilità, da nVidia con NV40 e G70, di cui mostro una immagine dello schema a blocchi

Dove si intravedono le 24 pixel pipeline (quelle in verde ed arancio al centro dell’immagine) formate, ciascuna, da 2 coppie di 4+1 alu scalari fp32, ognuna organizzata come nella figura sottostante

Quelle che nell’immagine sono indicate, erroneamente, come FP32 shader unit, sono, di fatto, composte, ciascuna, da 4 alu fp32 scalari che possono operare su una singola istruzione e lavorare in modalità sia co-issue che dual issue con le mini alu che le affiancano; questo significa che le minialu possono svolgere operazioni relative alla stessa istruzione della alu principale, oppure ad operazioni di istruzioni differenti. Come NV3x e NV4x, anche G70 lavora sia fp16 che ad fp32 e come gli le altre due serie di chip, presenta una dipendenza della alu principale dalle operazioni di texturing, per cui se si fa un accesso a texture la alu principale può svolgere solo un numero limitatissimo di operazioni. Le alu sono tutte MADD e nVidia afferma che G70, in fp16, può arrivare a svolgere fino a 27 operazioni elementari o miniops per alu (8 MADD per ciscuna delle due alu vettorial e una MADD per ogni alu fp32 scalare o minialu, più una operazione di normalizzazione vettoriale), oltre ad una operazioni di branching. In fp32, le operazioni teoriche si riducono a 20, perchè non è eseguibile la normalizzazione.
Concludioamo questo breve excursus con le ROP’s e, come modello, scegliamo ancora quelle di G70

Il compito delle ROP’s è quello di “scrivere” sul frame buffer tutto ciò che le unità di shading hanno calcolato, sia a livello di gemetrie che di colori o illuminazione. Inoltre contengono il circuito che si occupa delle operazioni di resolve del MSAA box che, almeno fino alle dx10, opera ancora in INT8.
Le ROP’s di G70, come quelle di NV3x e di NV4x, sono in grado di raddoppiare l’output in caso di sole z-ops, ovvero quando si scrivono i dati dello z-buffer. Questo grazie alla duplicazione dei circuiti contenuti nel ramo indicato come Z Comp e Z ROP anche all’interno del ramo relativo alle color ops.
Come si può vedere anche, almeno in parte, nello schema di G70, tra i vari blocchi (VS, PS e ROP’s), sono presenti dei crossbar che hanno lo scopo di minimizzare i cicli di idle delle unità di calcolo. Il problema principale di un’architettura a shader dedicati, come quelle viste finora, è che spesso capita che uno dei blocchi lavori a pieno carico mentre gli altri restano in attesa dei dati. Questo perchè manca la flessibilità da parte delle unità di calcolo che sono specializzate in determinate operazioni (in realtà sto etremizzando, poichè un minimo di flessibilità c’è, sia alivello di capacità delle alu, sia a livello di possibili ottimizzazioni). Avere dei crossbar tra i blocchi, in luogo di una struttura a cascata, permette di indirizzare i dati in uscita ad esempio, da un vertex shader verso la prima unità di pixel shading libera. Per lo stesso motivo, si usa posizionare dei buffer tra i vari blocchi, in modo che se, ad esempio, le unità di pixel shading sono cariche di lavoro, le unità di vertex shading non restano in idle, almeno fino a che non è riempito il buffer deputato a contenere i dati in uscita dalle unità geometriche.
Il motivo per cui ho preferito iniziare dalle architetture a shader dedicati e, per di più, di qualche anno fa, è presto spiegato: partendo dagli articoli sulla realizzazione di un’immagine 3D, è più semplice introdurre l’argomento architetture delle gpu partendo da modelli più semplici sia concettualmente che visivamente. E’ molto più semplice seguire uno schema in cascata che districarsi tra concetti come parallelizzazione e bilanciamento dei carichi di lavoro, tanto per citarne un paio. Inoltre, partendo dall’analisi di questi chip, è facila anche arrivare a capire i motivi che hanno portato ATi e nVidia a prendere strade così differenti per risolvere lo stesso problema.







