
Quello che stiamo vivendo è un momento di grande fermento, perché l’introduzione dei netbook da parte di Asus ha sconvolto gli equilibri del mercato dei PC, non soltanto in termini di modello e prezzo, ma anche di consumi.
Se da un lato l’economicità ha portato all’adozione in massa di soluzioni quali Atom di Intel (preferendolo nettamente alle versioni low-cost della linea Pentium, i Celeron), dall’altro ha fatto scoprire quanto importante e vantaggioso sia l’ultimo parametro citato.
A scombinare ulteriormente i piani di Intel (alla quale non fa certo piacere vendere più soluzioni economiche), sembra essere arrivata ARM, che con le ultime incarnazioni promette ottime prestazioni (da verificare sul campo, comunque) a fronte di consumi drasticamente ridotti.
Di questo abbiamo parlato recentemente in un articolo, che spiega soltanto in parte (sebbene molto importante) da dove derivano alcuni dei vantaggi. E’ giunto, pertanto, il momento di tuffarci nuovamente nel passato, per cercare di comprendere meglio il perché del successo di questa famiglia di microprocessori RISC, che hanno fatto la fortuna dell’altrettanto microscopica ARM Ltd.
Intanto si rende necessaria una doverosa premessa. ARM nasce come progetto dell’allora Acorn, azienda inglese molto nota e apprezzata per i suoi famosi BBC Micro, volto a sostituire il cuore degli home & personal computer che produceva, che erano per lo più basati sul MOS 6502 o da suoi derivati, sulla nuova linea Archimedes.
A causa di alcuni requisiti che si erano posti di soddisfare (in primis un’elevata velocità di risposta agli interrupt), i diversi processori disponibili all’epoca non si rivelarono all’altezza, e costrinsero la società a prendere atto che sarebbe stato meglio partire con un progetto totalmente nuovo.
Progetto che, manco a dirlo, fu comunque fortemente ispirato al 6502, sebbene la filosofia RISC su cui si basava fosse ben distante da quella del piccolo, ma pur sempre rappresentante dell’avversa famiglia CISC.
Il risultato di questi sforzi ha portato a una CPU snella (la prima incarnazione, anche se mai integrata in nessun computer, contava circa 25mila transistor), ma molto versatile e, sembra strano, anche estremamente veloce per i canoni dell’epoca. A circa 8Mhz era, infatti, quotata sui 4-5 MIPS.
Velocità così elevate non sorprendono di certo, considerato che siamo di fronte a un processore RISC, per i quali la maggior parte delle istruzioni vengono eseguite in un ciclo di clock (e qui ribadisco sempre di tenere a mente il contesto storico; per l’intero articolo).
Nello specifico, dobbiamo considerare che l’ARM era dotato di una pipeline a 3 stadi (fetch, decode ed execute). Questo vuol dire che in un determinato ciclo di clock il processore sta eseguendo un’istruzione, decodificando la successiva, e caricando la terza.
Con questa “catena di montaggio” le prestazioni più elevate si raggiungono ovviamente quando non si presentano “intoppi” e, quindi, il chip può procedere a piena velocità, arrivando al picco di 8 MIPS.
Ma, come ho detto prima, le stime che ho riportato parlano di 4-5 MIPS reali. Una bella differenza rispetto agli 8 teorici. Ciò è dovuto al fatto che esistono quattro tipologie di istruzioni che vengono eseguite:
- quelle che richiedono un solo ciclo di clock (tipicamente si tratta di operazioni aritmetico/logiche e manipolazione di registri);
- che richiedono più cicli di clock (moltiplicazione, load & store, swap, load & store multiplo);
- quelle “scartate” (in pratica è come se la CPU avesse eseguito una NOP, cioé un’istruzione che non fa niente, invece del lavoro che era “previsto”; in sostanza un ciclo di clock è stato sprecato senza eseguire concrete operazioni);
- salti che hanno provocato un cambio del flusso del programma (e quindi uno svuotamento e ricaricamento della pipeline).
Mentre il primo e ultimo caso sono ordinaria amministrazione, il secondo e il terzo meritano una spiegazione più dettagliata, per comprendere meglio alcune scelte e i meccanismi che stanno dietro l’implementazione di questo processore.
Il secondo caso dimostra che l’ARM è un RISC abbastanza atipico, in quanto risulta dotato di istruzioni particolarmente complesse. Non tutti i RISC posseggono istruzioni che eseguono moltiplicazioni (la cui circuiteria dedicata, tra l’altro, richiede non pochi transistor): essendo queste “complicate”, la “prassi” è quella di scrivere apposite routine per il loro calcolo.
La prima versione dell’ARM, infatti, non aveva supporto per la moltiplicazione, come da “tradizione” RISC. Questa, assieme alle istruzioni di “swap” (che eseguono operazioni di scambio con la memoria, mantendo il bus bloccato per evitare problemi di concorrenza; utili per implementare sistemi di sincronizzazione come lock e semafori), fu introdotta nella seconda versione di questo microprocessore.
Invece le istruzioni di load & store “multiple” sono un retaggio tipico dei CISC “più complicati” , e riguardano la possibilità di caricare o salvare un insieme di registri da o verso la memoria. Possedendo molti registri (ben 16), risulta uno strumento estremamente comodo (si risparmiano n istruzioni; una per ogni registro coinvolto), anche se per la sua esecuzione blocca la pipeline per un certo numero di cicli di clock.
Tornando all’ultimo caso rimasto, quello delle istruzioni “scartate”, questa è una prerogativa di alcune architetture RISC che consentono l’esecuzione condizionale delle istruzioni. Ciò vuol dire che se la condizione (legata ai flag del registro di stato) risulta soddisfatta, l’istruzione viene eseguita, altrimenti non ha alcun effetto e si passa all’istruzione successiva (esattamente come una NOP).
Questa funzionalità è stata introdotta nell’ARM per cercare di minimizzare l’uso dei salti che, come ho già detto, risulta penalizzante a causa dello svuotamento e del necessario riempimento della pipeline nel caso in cui il flusso dell’esecuzione del codice è costretto a cambiare.
Riporto un esempio che ho trovato per esporre in maniera precisa il funzionamento di questo meccanismo. Supponiamo di dover sommare R1 a R6 ed R2 a R5 se R3 vale zero, o sottrarre R1 a R6 e R2 a R5 altrimenti. Il codice assembly è il seguente:
A seconda del contenuto di R3 ci sono due possibilità. Se risulta zero vengono eseguite le due ADDEQ, mentre le RSBNE sono eseguite, ma non producono alcun effetto (sono esattamente come fossero delle NOP). Viceversa, se R3 è diverso da zero, le ADDEQ non producono effetti, mentre le RSBNE sì. A prescindere dal caso, la CPU impiega sempre 5 cicli di clock, perché tutte le istruzioni vengono comunque eseguite.
Riporto adesso l’equivalente per un microprocessore “tradizionale”, che non abbia alcuna forma di esecuzione condizionale o predicativa. Nello specifico, si tratta di codice Thumb (che è una particolare ISA e modalità di esecuzione introdotta negli ARM a partire dall’ARM7, e di cui forse parlerò in futuro), che non possiede il meccanismo di cui ho parlato finora:

Come si può notare, il codice è molto diverso, più complicato, e fa uso di istruzioni di salto. Questo vuol dire che il comportamento del processore non sarà lineare (e sarà penalizzato) a seconda dei due casi.
In particolare, se R3 vale 0, verrà eseguito un salto a .L13, per cui il bilancio in termini di cicli di clock è il seguente: 1 + 3 (per la BEQ, che provoca un ricaricamento della pipeline e una penalizzazione di 2 cicli) + 2 per le ADD = 6 cicli in totale.
Se R3 è diverso da zero, non verrà eseguito il salto a .L13, ma l’esecuzione continuerà normalmente, quindi il bilancio sarà di: 1 + 1 per la BEQ + 2 per le SUB e infine 3 per la B (anche qui, il salto provoca un ricaricamento della pipeline) = 7 cicli.
Il vantaggio della prima soluzione è evidente, ma non bisogna lasciarsi trascinare dall’entusiamo perché questo tipo di codice non è sempre utilizzabile, e questo per due motivi.
Il primo è che, all’aumentare delle istruzioni presenti nei due blocchi di codice mutuamente esclusivi, diventa più conveniente effettuare i due salti. Questo perché, a prescindere dalla condizione, tutte le istruzioni vanno necessariamente eseguite.
Il secondo è che le istruzioni eseguibili condizionalmente non possono, ovviamente, modificare i flag del registro di stato, pena il cambiamento della condizione iniziale e, quindi, l’alterazione del flusso di esecuzione che ci si aspettava.
C’è da dire che il primo caso dipende strettamente dall’implementazione del microprocessore e, quindi, dalla lunghezza delle pipeline. Infatti per i primi modelli (oggetto del presente articolo), come detto, è a 3 stadi; i successori hanno aumentato, e anche di molto (vedi i Cortex-A8, ad esempio) il loro numero, per cui l’uso dell’esecuzione condizionale è caldamente consigliato.
Il secondo caso viene parzialmente mitigato dal fatto che non tutte le istruzioni cambiano i flag del registro di stato. Ciò avviene soltanto se viene specificato un apposito campo (S) nell’opcode, per cui si possono tranquillamente eseguire somme, and logici, spostamenti, ecc.. Le uniche istruzioni che forzano l’aggiornamento dei flag sono quelle “di test“, ma è anche logico che sia così.
Un’altra interessante caratteristica di quest’architettura è data dalla flessibilità offerta per il secondo operando di un’istruzione (che sono quasi sempre costituite da tre operandi: registro destinazione, sorgente, e il terzo che può essere un valore immediato o un altro registro con apposite “variazioni”), che può essere costituito da:
- un valore immediato (una costante, ma con range ovviamente limitato, causa lunghezza fissa a 32 bit degli opcode);
- un registro;
- un registro a cui viene applicata un’apposita istruzione di shift (il cui valore può essere, a sua volta, prelevato da una costante o da un altro registro).
Di seguito un paio di esempi presi dal datasheet:
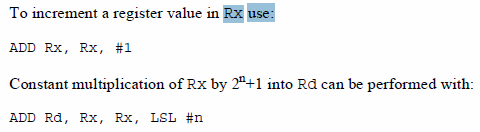
Ciò consente di sfruttare meglio il barrel shifter integrato, ottenendo prestazioni più elevate e richiedendo anche meno istruzioni perché, fatemi passare il termine, le istruzioni di shift risultano sostanzialmente “gratuite”.
Infatti se devo eseguire uno shift a un valore che mi servirà per una successiva operazione, questo può essere calcolato “al volo” nella stessa operazione. Il risultato è che viene impiegata una sola istruzione, non viene “sporcato” un registro (altrimenti necessario per contenere il risultato temporaneo), e soprattutto viene eliminata una dipendenza fra istruzioni (non rilevante in buona parte delle versioni dell’ARM, ma in quelle superscalari sì).
A completare il roseo quadro ci sono le istruzioni di load & store, che dispongono di comode modalità d’indirizzamento. Chi ha lavorato col PDP-11 o col 68000 si troverà a casa con quelle di pre-incremento e post-incremento, che permettono di aggiornare il registro indice, consentendogli di puntare alla “successiva” (o “precedente”, a seconda del segno dell’offset specificato) locazione di memoria.
Dicevo all’inizio che una delle più rilevanti necessità che ha spinto Acorn a progettarne uno completamente nuovo è stata quella di poter servire velocemente interrupt. Per far questo ha introdotto, oltre ai 16 registri disponibili in modalità utente, altri dedicati e riservati alla particolare modalità d’esecuzione (utente, supervisore, interrupt, e fast interrupt).
Tutte le modalità hanno dei propri registri R13-R15, ma, per fare un esempio, quella fast interrupt possiede anche dei propri registri R8-R12. Il vantaggio rispetto ad altre architetture è notevole: all’occorrenza di un (fast) interrupt, la CPU commuta modalità, ma non ha alcun bisogno di conservare i registri R8-R15 da qualche parte (usualmente lo stack), per poi ripristinarli all’uscita. In pratica l’interrupt può essere immediatamente servito, facendo uso dei propri registri.
Veniamo a questo punto, e concludo, alla croce e delizia di questo microprocessore. L’efficienza e la compattezza del codice è stata un pallino fisso di Acorn, come si è visto finora, e ciò traspare anche dalla soluzione adottata per gestire i flag del registro di stato.
In realtà non esiste un vero e proprio registro di stato, poiché tutti e 6 i bit sono stati impacchettati nei 6 bit alti del registro R15, che è… il Program Counter. Del quale si sfruttano anche i due bit bassi, che normalmente sarebbero sempre posti a zero poiché gli opcode sono sempre a 32 bit, e l’indirizzo di memoria è sempre allineato a questa quantità.

Questo significa che il cambio di modalità, oppure il salto a un routine, conserva sempre sia il PC che i flag di stato, quando altre architetture necessitano di apposite istruzioni allo scopo, o di maggior spazio nello stack.
Il prezzo da pagare, però, è molto salato: in questo modo lo spazio d’indirizzamento del processore è stato limitato a un massimo di 64MB, e questo sia per il codice che per i dati. Se non è stato un problema per i primi anni (dove la memoria si misurava in KB), è diventato un enorme limite nella seconda metà degli anni ’90.
Ciò ha costretto ARM a rimettere mano al progetto eliminando questo pericolosissimo collo di bottiglia, che avrebbe relegato l’architettura soltanto al ruolo di economico microcontroller per sistemi embedded e nulla di più. Ma di questo ne parlerò meglio quando affronterò il tema caldo del momento: l’architettura Cortex-A8, che tanto sta facendo discutere.







