Il nostro autore “nessuno” mi ha mandato la seconda parte dell’articolo su Maxwell.
Premessa, questo articolo è stato scritto molto lentamente nei mesi scorsi e oggi sembra un po’ poco aggiornato rispetto agli avvenimenti avventi nel frattempo.
Ho modificato all’ultimo momento qualche paragrafo per aggiornarlo con gli ultimi avvenimenti, ma tutto il discorso è basato su quello che si sapeva a Ottobre 2018.
Tenente conto, dato che i tempi tra scrittura degli articoli e loro pubblicazione sono un po’ altini.
# 4.0 Analisi di Turing
## 4.1 Le dimensioni contano
Qual è il motivo per cui queste GPU hanno questi die enormi?
Le ragioni, sono varie, a cominciare dal fatto che non c’è ancora un processo produttivo migliore dei 16nm di TSMC che possa ridurre le dimensioni al punto tale di rendere questi chip della solita dimensione a cui siamo abituati nel mercato consumer.
Come avevo anticipato nell’articolo precedente, anche Maxwell era stato costruito sulla stessa filosofia: invece che creare una revisione senza infamia né lode sullo stesso PP in attesa di un PP migliore, Nvidia ha osato creare die più grandi (quindi dal costo superiore) ma con prestazioni maggiori. La storia le ha dato ragione. Ora ci tenta con Turing, con una differenza non secondaria: i die sono enormi ma le prestazioni con i giochi classici, nonostante tutte le ottimizzazioni a livello di architettura, non sono aumentate di chissà quale gap rispetto alle GPU high end della generazione precedente (che costa decisamente meno). Il loro valore aggiunto si basa su delle promesse, quelle della possibilità del ray tracing in tempo reale e del DLSS.
Gli handicap di questa rivoluzione della pipeline di calcolo sono due: uno è che non si hanno prestazioni sufficienti per abbandonare completamente la pipeline vecchia e le sue unità fixed function, l’altra è che in qualche modo bisogna necessariamente rimanere compatibili a quanto fatto finora (una GPU che fa girare solo un paio di giochi scritti espressamente solo per lei non la comprerebbe nessuno).
In entrambi i casi il problema è che la vecchia pipeline comunque occupa lo stesso spazio di prima e finché lo sviluppo dei giochi non comincerà a vertere maggiormente sull’uso delle nuove unità di calcolo quelle vecchie non possono essere né diminuite né tanto meno rimosse. Per un periodo più o meno lungo dovranno coesistere insieme e pestarsi i piedi a vicenda (aumentare le prestazioni in rasterizzazione vorrà dire rubare spazio alle capacità ray tracing, aumentare quelle ray tracing significherà sacrificare qualche pezzo della pipeline di rasterizzazione, tipo meno ROPs o meno TMU o meno cache).
Ma c’è dell’altro… avete dimenticato il connettore NVLink per lo SLI? Ovviamente non sta lì perché Nvidia è impazzita o crede ancora che lo SLI sarà il futuro, è lì solamente perché queste GPU sono di livello professionale, ovvero destinate alle Quadro e Tesla dove le nuove unità sono decisamente sfruttabili in maniera più rapida e con maggiore soddisfazione per chi ne farà uso. E non ultimo, usate per creare i futuri giochi che le sfrutteranno nel mercato consumer.
Invece che creare un die apposta per il mercato consumer e risparmiare qualche mm2, Nvidia sembra aver deciso che lo stesso die poteva essere usato anche per il mercato enthusiast: d’altronde con schede che vanno dai mille dollari in su, lasciare l’NVLink non è che sia questo sacrificio di guadagno, e riprogettare un die nuovo per solo qualche particolare diverso costa e parecchio.
La GPU creata per il mercato mainstream è chiaramente il TU106, la più piccola della serie RTX, dove manca completamente il connettore per lo SLI. Non c’è quindi supporto neanche per la versione povera di tale caratteristica, ma d’altronde seppure questa volta montata su una scheda di serie x70 le GPU di serie x06 è da qualche generazione che mancano della funzionalità SLI, quindi nulla di cui stupirsi, se non che sembra evidente che la modalità multi GPU sta piano piano per essere abbandonata in tutte le fasce che non siano il top, dove 2 schede, (se e quando) ben supportate possono far ottenere prestazioni altrimenti impossibili.
## 4.2 Turing per la massa?
Abbiamo visto che Nvidia ha finora rilasciato 3 GPU con base Turing con le unità dedicare al ray tracing, tutte destinate al mercato enthusiast per i prezzi praticati (update: a Gennaio 2019 con la 2060 ha lanciato una scheda con prezzo non propriamente mainstream a $350 ma neanche proibitivo come le altre Turing).
Si è vociferato anche della possibilità che Nvidia possa rilasciare anche una nuova GPU, il TU108, nel 2019 per il (vero) mercato mainstream che andrà a popolare la scheda il cui nome dovrebbe essere GTX11xx. Purtroppo non si conoscono quali siano le caratteristiche di questa GPU ma sembra che non avrà le unità ray tracing (infatti pare che sarà denominata GTX non RTX e la serie dovrebbe essere la 11 e non la 20). Le ragioni per tale scelta sarebbero ovvie e vanno di pari passo con la strategia che Nvidia ha messo in campo per l’introduzione sul mercato di questa nuova tecnologia rivoluzionaria.
Per prima cosa i costi: la nuova GPU dovrà scontrarsi con le soluzioni di dimensione (e prezzo) inferiore della concorrenza che molto probabilmente non avrà nessuna delle nuove unità di calcolo che lei ha introdotto e non può battagliare se il suo costo è troppo alto. Il successore a 7nm di questa architettura arriverà non prima di un anno, forse inizio 2020 e nel frattempo AMD rilascerà Navi a 7nm per la fascia mainstream (per ora si parla di Q3 o forse Q4 2019), quindi i costi di produzione per volumi così elevati per così lungo tempo saranno importanti nei mesi precedenti l’arrivo della serie 3000.
Inoltre la quantità delle unità RT con questa GPU non sarebbero sufficienti per garantire prestazioni decenti neanche per gli effetti più semplici, quindi sarebbero sostanzialmente inutili, esattamente come sarebbe tentare di fare ray tracing in real time con Pascal, o anche con il GV100 (che come abbiamo visto con 10 TFLOPS per GigaRay non arriverebbero a raggiungere nemmeno 1/3 delle capacità di TU106).
Inoltre nel 2019 i giochi che potranno sfruttare bene le unità ray tracing si conteranno sulla punta delle dita di una sola mano e non saranno di certo un incentivo per la vendita di una GPU destinata alla fascia mainstream che costerebbe troppo (non solo tanto come nella tradizione Nvidia) e quindi permetterebbe alla concorrenza di occupare l’enorme spazio lasciato libero in tale fascia.
Nonostante queste mancanze che apparentemente metterebbero la nuova GPU allo stesso livello di Pascal, le differenze architetturali tra Turing e Pascal che abbiamo evidenziato permettono di avere una GPU diversa (e migliore) anche con meno CUDA core per via della maggiore capacità di eseguire più lavoro a parità di risorse a disposizione (e di consumare ancora meno di quanto non facesse Pascal).
Non è escluso che la GPU, forse priva dei core RT, possa essere dotata dei tensor core che possono essere usati sia per il DLSS, funzione su cui Nvidia sembra puntare parecchio per differenziare la propria offerta rispetto alla concorrenza e renderla capace di buone prestazioni a risoluzioni maggiori nonostante la mancanza di forza bruta, sia per come detto prima, per supportare altre funzionalità avanzate come l’IA.
Se il TU108 dovesse non avere le nuove unità di calcolo aggiunte, sarà curioso metterlo a confronto con le dimensioni di Pascal per vedere quanto effettivamente occupano le nuove unità di calcolo e comprendere quanto velocemente possano scalare in futuro le prestazioni del ray tracing e se mai sarà possibile una GPU solo ray tracing senza rasterizzazione.
La possibilità è che RT e Tensor Core ormai facciano parte della nuova unità SM di Turing (e probabilmente future architetture) che Nvidia non vorrà ridisegnare per le sole GPU di fascia inferiore di questa generazione. Le unità RT (e forse anche i tensor core) potrebbero essere disabilitate su TU108 ma occupando comunque spazio. In questo caso non sapremo mai quanto effettivamente le nuove unità incidano sulle dimensioni rendendo più difficile capire lo scaling futuro possibile.
## 4.3 E i 7nm?
Un capitolo a parte merita l’analisi del vicino futuro delle scelte di Nvidia dopo l’introduzione del ray tracing HW nelle sue GPU, che la differenzia (ma che per il momento la penalizza nei costi) rispetto alla concorrenza.
Sappiamo che Turing è realizzato con lo stesso processo produttivo con cui fu realizzato l’unico chip con architettura Volta, ovvero i 12nm di TSMC. Questo PP, nonostante il suo nome, non ha poi molto di 12nm (vedesi l’articolo precedente relativo ai processi produttivi). Rispetto ai 16nm con cui sono realizzate le GPU dal GP104 e più grandi (le altre più piccole sono realizzate da Samsung con il PP a 14nm, uguale a quello usato da AMD per Polaris e Vega) i nuovi 12nm non prevedono un vantaggio in termini di spazio occupato (la densità per transistor è la medesima) e neanche in termini di frequenze maggiori raggiungibili. Avevamo già visto che il GV100 non aveva frequenze maggiori rispetto al GP100, e anche in questo caso le nuove GPU non hanno frequenze differenti rispetto a Pascal. L’unico vantaggio è in termini di consumo, dove a parità di lavoro da svolgere, Turing impiega meno tempo e con consumi inferiori. Ovviamente se vogliamo avere il massimo possibile, i consumi non saranno inferiori, anche perché il chip è abbastanza grande e non è chiaro se le nuove unità siano completamente disabilitate quando non usate, essendo parte integrante dei nuovi SM.
Non possiamo parlare di un vero passo avanti di quei termini che abbiamo visto quando parlavamo di avanzamento tra processi produttivi: densità, frequenze, consumi.
Anche per questo motivo le dimensioni di queste nuove GPU sono elevate: le nuove unità di calcolo, le cache aggiunte, la suddivisione degli SM in 2 blocchi separati con diverse parti replicate, l’uso del bus nvlink, tutti hanno contribuito a renderle piuttosto grandi in termini di silicio usato.
Il prezzo di vendita quindi non può che riflettere questo enorme costo, e infatti vediamo la 2080Ti prezzata di listino ad un prezzo persino superiore a quello che era della Titan delle scorse generazioni.
D’altra parte sappiamo anche che AMD ha iniziato già a produrre a 7nm (con processo High Power, non quello che era dedicato ai SoC ARM) i die di Ryzen 2 ed ha già annunciato una nuova GPU Vega 20 sullo stesso processo produttivo (update di Gennaio 2019: Vega 20 è stata rilasciata anche su scheda gaming). Navi, previsto per la metà del prossimo anno, sarà a 7nm. Quali costi siano associati oggi a queste produzioni non lo sappiamo: come abbiamo visto nell’articolo relativo ai PP, le rese, cioè il numero di chip funzionanti rispetto al totale prodotto, influisce parecchio sul costo finale e l’esperienza dice che processi produttivi nuovi non hanno mai rese alte (chiedere a Intel e ai suoi 10nm per conferma). Nonostante ciò ad un certo punto nel tempo, oggi individuato dopo la metà 2019, i 7nm dovrebbero essere sufficientemente maturi da permettere la produzione di massa di chip dedicati al mercato consumer.
Cosa ci attente quindi con i 7nm?
Dai dati forniti da TSMC stessa le prestazioni dei 7nm (il cui nome commerciale è N7) vs 16nm+ (il cui nome commerciale è N16+) sono:
+------------+-------------+------------+---------+ | | Perf. at | Power at | Gate | | N7 vs N16+ | const power | const perf | Density | | | >35% | -65% | 3.3x | +------------+-------------+------------+---------+
Che significa:
– triplicazione (teorica) della densità del chip, anche se in verità non avremo chip grandi un terzo a parità di circuito perché non tutte le parti del chip scalano al massimo possibile.
– riduzione dei consumi a un terzo a parità di frequenza.
– aumento delle frequenze che può superare il 35% a parità di consumi.
Possiamo ipotizzare a grandi linee che con i 7nm avremmo quindi GPU Turing grandi circa la metà di quelle che abbiamo oggi con un incremento prestazionale dovuto al solo PP di circa il 35%. Praticamente si avrebbero GPU delle dimensioni ragionevoli che possono competere in termini di dimensione / prestazioni, e quindi costo / prestazioni per i giochi basati sulla rasterizzazione, che saranno ancora per lungo tempo lo standard di sviluppo. Sempre basandoci su questi numeri, possiamo ipotizzate che le prestazioni potranno aumentare grazie all’aumento di frequenza di almeno il 30% (che vorrebbe dire andare andare in modalità di funzionamento standard ben oltre i 2GHz che le GPU Nvidia raggiungono con il massimo OC possibile oggi quasi sempre a liquido).
Come abbiamo detto sempre nell’articolo relativo al processo produttivo, sappiamo che numero di unità di calcolo e frequenza operativa sono 2 parametri intercambiabili per ottenere un determinato livello di prestazioni: all’aumentare di uno dei due, può diminuire il secondo.
Le controindicazioni sono nell’aumento dei consumi più elevato rispetto al guadagno prestazionale per l’uso di frequenze maggiori o di maggiori costi in caso di aumento di unità di calcolo a stessa frequenza.
I limiti sono il consumo massimo (che deve essere gestibile in un case casalingo) o i costi di produzione (che devono essere congrui con le richieste del mercato).
Agendo su questi due parametri, lasciando in sospeso la questione dei possibili ignoti vantaggi della nuova architettura, possiamo fare qualche ipotesi di quelle che saranno le probabili scelte per le prossime GPU partendo dalla versione base (la meno probabile):
– GPU con dimensione dimezzata, consumi inferiori alla metà, stesse prestazioni minore costo, minore prezzo. Questo scenario si avrebbe con il semplice shrink di Turing.
– GPU con dimensione dimezzata, consumi uguali, aumento delle frequenze per +30% di prestazioni, minore costo, minore prezzo
– il naturale compromesso, GPU con dimensione aumentata in relazione al nuovo PP (con unità di calcolo che potranno essere ripartite anche in maniera diversa, a seconda di quanto Nvidia vuole spingere sul ray tracing stando bene attenta a non rimanere indietro nella rasterizzazione rispetto alla concorrenza), aumento delle frequenze ma inferiore al 30% per risparmiare sui Watt, costi diminuiti rispetto a quanto necessario ora e prezzi… dipendenti da quello che offrirà la concorrenza che dovrebbe essere già disponibile sul mercato quando Nvidia rilascerà il seguito di Turing.
Possiamo fare una stima di quello che potrebbe essere il compromesso tra frequenza e aumento di dimensioni del die facendo due semplici calcoli sui consumi, secondo la tabella riportata sopra con i dati di targa delle nuove GPU. Abbiamo che a parità di consumi (parlando della top di oggi, con TU102, i W necessari sono 250) possiamo aumentare le prestazioni di circa il 30%. Per un aumento complessivo più consistente di circa il 50% servirebbe aumentare il numero delle risorse di calcolo di un ulteriore 15% circa con un aumento dei consumi proporzionale:
250W * 1.15 = 290W ~ 300W
Questo dovrebbe essere il massimo raggiungibile contenendo i consumi ad un livello alto ma ancora accettabile per il mercato consumer e una scheda che si propone come il non plus ultra del momento (AMD ha già questi consumi da qualche generazione, dunque non sarebbero impossibili da proporre. Update di Gennaio 2019, sembra che anche la nuova Vega a 7nm avrà consumi elevati nonostante prestazioni che sembrano vicine a quelle di una 2080, o meglio, visto che è sprovvista di qualsiasi nuova funzionalità rispetto alla versione precedente, con prestazioni vicine alla 1080Ti).
Riassumendo e facendo dei ragionamenti inversi, abbiamo che le prestazioni massime della prossima GPU top di Nvidia dovrebbero essere non superiori al 50% di quello che oggi offre la 2080Ti, non vi sarà una diminuzione dei consumi apprezzabile (semmai saranno diminuiti e non aumentati) e i prezzi, sebbene rimarranno alti come da “tradizione” Nvidia (e per via di die comunque più grandi), dovrebbero scendere abbondantemente per permettere alle nuove schede di competere con la proposta di AMD che quasi sicuramente avrà die più piccoli con prestazioni focalizzate sulla rasterizzazione e quindi area e consumi dedicati solo a quel tipo di lavoro.
Ovviamente quelli calcolati sono numeri ipotetici con una certa variabilità: riduzione della dimensione finale del die (che comprende le scelte se usare ancora NVlink e quanti canali), reale diminuzione dei consumi, aumento delle prestazioni tramite revisione dell’architettura possono tutti incidere in modo da cambiare il valore delle prestazioni che le GPU potranno offrire. Anche se dal lato tecnologico non credo che si possa discostare molto da quanto qui previsto (diciamo + o – 10%?).
Maggiore variabilità potrà essere introdotta dalle scelte strategiche che entrambe le aziende concorrenti vorranno adottare: prestazioni, costi (quindi margini), consumi sono le tre variabili su cui si combatte e ognuna storicamente ha scelto valori diversi di ciascuno per i propri prodotti, con risultati e successi differenti.
## 4.4 Perché i 12nm?
Molti si sono chiesti perché mai Nvidia abbia voluto proporre la tecnologia di accelerazione per il ray tracing con un processo produttivo che le ha imposto un numero di unità di calcolo a quanto pare insufficiente per ottenere prestazioni accettabili anche in uno scenario di rendering ibrido in cui il ray tracing è solo una parte secondaria della scena. Tale dubbio nasce guardando le prestazioni degli effetti aggiunti all’ultimo momento nei pochi giochi che per ora supportano la nuova tecnologia. Bisognerebbe valutare le performance nel tempo con il miglioramento dei tool, delle tecniche e una migliore integrazione all’interno dei motori di rendering nati e pensati per ora solo per la rasterizzazione, ma comunque il dubbio è lecito.
Cominciamo con il dire che le scelte di questo tipo non sono cose che si fanno oggi per vederne i risultati domani, ma è richiesto almeno un paio di anni di lavoro, da quando si dà il via, perché si realizzi qualcosa di concreto.
Quindi perché usare i 16nm (nella versione denominata 12nm di cui abbiamo visto non cambiare poi molto se non qualcosa nei consumi) invece che i più promettenti 7nm?
A interpretare la strategia Nvidia in una certa maniera sembra che il lancio di questa architettura sia allo stesso tempo in ritardo e in anticipo.
In ritardo perché probabilmente erano pronte diverso tempo fa (i 12nm con cui sono prodotte sono vecchi di oltre un anno ora e sono stati messi a punto con il GV100, GPU da oltre 800mm2, quindi probabilmente pienamente maturi) ma le vicissitudini legate al mining che faceva vendere quantità inaudite di Pascal hanno suggerito che non era il caso di introdurre qualcosa di così “enormemente” diverso. La frenata repentina del fenomeno mining ha lasciato Nvidia con qualche scheda Pascal di troppo invenduta che deve essere riassorbita dal mercato gaming. Quindi altri mesi in più di attesa prima di poter anche solo annunciare che era pronto il successore di Pascal (il cui nome è rimasto nel limbo fino all’ultimo, tanto per comprendere quale aura di segretezza circolava su questo progetto).
Però è anche in anticipo: die così grandi per feature promesse e nessun reale vantaggio a suon di reali (e non promesse) banconote da cento dollari/euro da parte di chi le compra significa che è tecnologia acerba, come lo sono state tutte le nuove tecnologie apparse improvvisamente con questa o quell’altra nuova architettura.
Ma allora perché questa decisione di fare una rivoluzione a metà?
La risposta potrebbe essere legata ad un momento particolare di congiuntura favorevole (per Nvidia), attenta pianificazione dell’impatto delle nuove funzionalità sul mercato e una situazione di evoluzione delle tecnologia prossima ad un rapido cambiamento (MCM, Multi Chip Module).
A oggi, fine 2018, Nvidia gode di una situazione particolare: ha sul mercato una architettura vecchia di 2 anni e mezzo e nessuna pressione da parte della concorrenza. Come illustrato negli articoli precedenti, Nvidia gode del vantaggio totale nei tre termini che caratterizzano i propri prodotti: performance / area che determina costi inferiori (= margini superiori a parità di prezzo finale), performance / Watt che fanno apparire il proprio prodotto migliore e lo rendono adatto all’uso anche nel mercato mobile, prestazioni assolute più elevate (e non di poco) che la rendono leader del mercato agli occhi del consumatore.
Il vantaggio di Nvidia sulla concorrenza si è concretizzato nello stop che AMD ha preso per la realizzazione di quella che dovrebbe essere l’architettura post Polaris (Navi) che dovrebbe essere decisamente migliore di quanto visto finora (un approfondimento dopo). In questo particolare momento Nvidia ha completa libertà di azione sul mercato delle GPU ed è un momento che è cominciato con il lancio di Vega (poco più di un anno fa) e che terminerà molto probabilmente proprio con l’arrivo di Navi. Si parla quindi di voler sfruttare questa finestra di circa 2 anni o poco più di completo monopolio (update Gennaio 2019: il lancio di Vega 20 nel settore gaming avrà un impatto nullo sulla strategia di Nvidia essendo anche questa ultima scheda prodotta da AMD un mostro di tecnologia che però partorisce prestazioni che Nvidia ha da oltre 2 anni con il GP102 e per tanto, sarà prodotta in quantità ridotta perché il prezzo di vendita è sostanzialmente insostenibile, come è stato per la precedente Vega).
La strategia di Nvidia è stata quella di lanciare la tecnologia ray tracing in modo “soft”: con Turing, realizzato a 12nm, la tecnologia non sembra assolutamente matura, ma soprattutto non è sostenibile nei costi (GPU da 700 e rotti mm2 non possono essere competitive nel mercato consumer, qualsiasi siano le loro caratteristiche). Il motivo è duplice: da una parte, come abbiamo già detto, queste GPU sono state pensate per i produttori di contenuti che possono quindi iniziare a usarla e a prendere confidenza con essa. Dall’altra parte si è voluto iniziare la rottura con il passato cominciando a mostrare quello che dovrebbe diventare il supporto per il futuro, andando ad agire direttamente sui bisogni del consumatore.
Storicamente il lancio di nuove feature ha sempre avuto il problema del tempo di adozione da parte degli sviluppatori e quindi anche un ulteriore ritardo di percezione della novità da parte del consumatore. Arrivare il anticipo sui tempi proponendo feature nuove non è mai stato particolarmente vantaggioso, dato che il ritardo ha sempre portato la concorrenza ad arrivare allo stesso livello di supporto nel momento in cui le nuove feature sono state prese in considerazione dagli sviluppatori.
Con Turing Nvidia si è portata una generazione in vantaggio rispetto a quello che dovrebbe essere il supporto alla nuova tecnologia. Supponendo che Navi, il concorrente della prossima generazione, non abbia le stesse capacità di accelerazione di ray tracing, Nvidia potrebbe trovarsi con un HW finalmente in grado di essere usabile sia in termini di potenza bruta che di sfruttamento reale, dato che gli sviluppatori hanno già potuto aggiungere il supporto ai propri motori con mesi di lavoro anticipato. E’ quindi possibile che il seguito di Turing già al day one potrà godere di giochi e applicazioni in grado di sfruttare ray tracing e le altre innovazioni (penso soprattutto alla mesh geometry, vedere dopo) al massimo, mentre la concorrenza dovrà presentarsi sul mercato con la sola “vecchia” pipeline di rasterizzazione.
Avesse atteso i 7nm, non avrebbe avuto alcun vantaggio il giorno del lancio, o meglio proponendosi esattamente come ora con Turing rispetto a Polaris, quindi con davvero poco o nulla a fare la differenza.
Il valore di innovazione percepita potrebbe essere decisamente differente e quindi aumentare il valore aggiunto ai prodotti, che dovrebbe andare a compensare le dimensioni (e quindi i costi) maggiori delle GPU di Nvidia rispetto alle analoghe di AMD con le stesse prestazioni di rasterizzazione (se Navi sarà GCN based, Nvidia comunque avrà “uno sconto” sulla differenza delle dimensioni visto la differenza di risorse che GCN richiede per ottenere le stesse prestazioni di Pascal e quindi a maggior ragion rispetto a Turing e i suoi successori).
Tutto perfetto per la strategia Nvidia quindi? Ovviamente no. La percezione di questa innovazione, e quindi di valore aggiunto, non è così scontata. Bisognerà valutare una serie di fattori, quali il costo aggiuntivo, le prestazioni e la resa qualitativa per decidere se, come e quando il ray tracing diventerà una feature di cui i giocatori non possono fare a meno, pena un peggioramento dell’esperienza ludica. Non è neppure detto che anche se Nvidia si sia preparata con anticipo, la rivoluzione del ray tracing parta proprio con il post Turing, magari sarà alla generazione successiva, lasciando tempo a AMD di portarsi in pari in termini di prestazioni e funzionalità extra rasterizzazione aggiunte con l’architettura post Navi.
Da aggiungere che Navi sarà l’architettura di base delle GPU della prossima generazione di console (Xbox e PlayStation) e quindi senza l’accelerazione HW del ray tracing potrebbe in qualche modo rallentare l’adozione di tale tecnologia fino appunto al dopo Navi, e quindi al dopo-dopo Turing (come rimpiango le vecchie roadmap dove erano indicati i nomi delle architetture delle generazioni per diversi anni successivi).
Ciò che è sicuro ed importante è che finalmente il percorso verso il ray tracing che sostituirà poco a poco la ormai obsoleta rasterizzazione è cominciato ed è il sogno di molti che si sta realizzando (speriamo prima che l’artrosi mi impedisca di usare il mouse per giocare).
# 5.0 Ray tracing e basta?
Con Turing Nvidia non ha solo portato il ray tracing come nuova feature. Oggi si parla principalmente solo di questa perché “è la rivoluzione” della grafica. Insieme però c’è anche una nuova feature non meno promettente in termini di prestazioni e qualità della scena da renderizzate: la mesh geometry.
Nel nostro excursus riguardante le differenze tra GCN e Kepler (e architetture Nvidia successive) avevamo evidenziato come il motore geometrico di Nvidia fosse stato pensato per essere scalabile in maniera automatica con le risorse di calcolo (numero di SM) a differenza della scelta di AMD di porlo a livello molto più alto nella gestione delle risorse (dipendente dal numero di CU).
Ebbene, con Turing Nvidia propone una nuova pipeline di gestione della geometria che rimanendo sempre a basso livello, utilizza maggiormente gli shader tradizionali per ottenere quello che oggi si realizza tramite unità a funzione fissa (vertex, tessellation, and geometry shading) e così avere un miglioramento della flessibilità di applicazione delle trasformazioni, oltre che una maggiore velocità dovuta alla eliminazione precoce delle primitive che non devono essere elaborate e il mantenere i risultati riutilizzabili all’interno della GPU stessa.
Questo metodo permette di alleggerire il lavoro che oggi è a carico della CPU che deve usare mesh ad alta complessità tranne in quei pochi casi in cui la tessellazione può essere di aiuto.
Si dà quindi in carico alla GPU la maggior parte del lavoro di gestione della geometria potendo beneficiare di una serie di vantaggi intrinseci alla GPU stessa, come la possibilità di modificare a piacimento questa geometria e di tenerla in cache in modo che gran parte del lavoro svolto precedentemente non debba più essere rifatto.
Mentre con la pipeline tradizionale la geometria era gestita tramite draw call, con questa nuova implementazione la geometria è gestita tramite mesh shader, ovvero lavori che elaborano piccole geometrie (meshlet) che operano nella massima libertà di esecuzione di codice generico esattamente come ora si fa con i pixel (che dall’introduzione delle unità di calcolo unificate si elaborano tramite diversi thread di compute shader). La flessibilità è così alta che è possibile modificare o addirittura creare in maniera procedurale la geometria direttamente nella GPU senza alcun contributo della CPU, potendo quindi elaborare deformazioni ed animazioni procedurali, tipo le espressioni facciali, che richiedono molti passaggi e gran lavoro da parte della CPU con la pipeline tradizionale o la geometria particellare o quella volumetrica, dove non si è più vincolati alle capacità (limitate) delle unità fisse.
Nvidia, anche in questo caso, non ha pensato ad una funzionalità “tutto o niente”, ma come per il ray tracing che può essere usato in modalità ibrida insieme alla ormai collaudata (e ricca di unità di calcolo dedicate) rasterizzazione, anche in questo caso la scelta se elaborare ogni singolo oggetto della scena tramite la nuova o la vecchia pipeline geometrica è lasciata al programmatore che se vuole usare la nuova, deve creare i relativi shader di elaborazione che emulano quello che prima facevano le unità fixed function potendo però, come detto, godere di maggiore libertà di azione. Per ora la nuova pipeline è direttamente usabile tramite OpenGL o Vulkan, mentre per quanto riguarda le Direct3D dovrebbe essere necessario una estensione da parte di Microsoft che per ora rimane legata all’uso della pipeline geometrica tradizionale che lei stessa ha definito.
Il vantaggio in termini di prestazioni della nuova pipeline mesh, secondo i dati della stessa Nvidia, può arrivare ad essere superiore a un ordine di grandezza (10 volte) rispetto a quella tradizionale, scaricando allo stesso tempo la CPU di lavoro e diminuendo la banda necessarie per il passaggio di dati tra CPU e GPU.
Questa nuova feature segue quella simile introdotta da AMD con Vega e il Primitive Shader e include anche la “draw-stream binning rasterizer” meglio conosciuta come DSBR. Sfortunatamente queste feature in Vega non sono mai state usate (AMD ha addirittura sospeso il supporto al Primitive Shader lasciando tutto il lavoro per il suo sfruttamento sulle spalle dei programmatori che ovviamente non lo hanno mai preso in considerazione) mentre Nvidia ha creato una semplice demo che mostra come il suo HW funziona con tale nuova funzionalità con un numero impressionante di triangoli gestiti (dell’ordine di qualche miliardo) mentre quelli effettivamente renderizzati ovviamente sono molti di meno (l’eliminazione dei triangoli nascosti è effettuata sempre tramite la nuova pipeline programmabile).
Stiamo mettono qui a confronto due feature simili, ma con capacità totalmente diverse: AMD sostiene che il usando il Primitive Shading si può ottenere fino al doppio di poligoni processati per ciclo di clock (quindi arriverebbe più o meno alle stesse capacità di Pascal e i suoi Polymorph Engine), Nvidia dichiara un ordine di grandezza superiore (10 volte).
E’ chiaro che l’investimento per adottare queste tecniche ha un ritorno in termini prestazionali completamente diverso e che quindi rende la nuova pipeline di Nvidia decisamente più appetibile rispetto a quanto offerto in passato.
Un’ultima feature aggiunta a Turing è il supporto dell’Adaptive Shading in grado di operare una rasterizzazione con qualità (e quindi velocità) diversa a seconda dell’importanza e della differenza tra frame di singole zone dell’immagine. A detta di Nvidia questa tecnica se usata correttamente può aumentare le prestazioni anche oltre il 25% senza una perdita di qualità percepibile dall’utente.
Se qualcuno dovesse storcere il naso davanti a questi “trucchi” per aumentare le prestazioni come il DLSS o l’Adaptive Shading, si ricordi che tutta la pipeline di rasterizzazione è un susseguirsi di “trucchi” (uno da sempre usato sono texture abilmente posizionate al posto di un numero maggiore di poligoni per aumentare i dettagli percepiti ma non realmente esistenti geometricamente) ed è appunto solo con l’uso del ray tracing che queste modalità saranno rimpiazzate da algoritmi sempre più precisi man mano che la capacità computazionale aumenterà.
# 6.0 Il futuro del monolite
## 6.1 MCM è il futuro delle GPU?
Con Turing siamo arrivati ad un punto estremo dello sviluppo delle GPU per quanto riguarda le dimensioni nel mercato consumer.
In precedenza avevamo già avuto modo di constatare che le dimensioni delle GPU avevano toccato valori estremi, con il GM200 (601mm2, al limite delle dimensioni possibili a 28nm), poi con il GP100 (610mm2 a 16nm) e infine con la GPU più grande mai prodotta, il GV100 (815mm2).
E’ evidente che lo sviluppo di GPU sempre più veloci è limitato dalle possibilità che il processo produttivo impone, come abbiamo visto nell’articolo relativo ai processi produttivi e che la voglia di andare oltre trova un enorme ostacolo nelle dimensioni che affondano le rese e quindi fanno impennare i costi relativi.
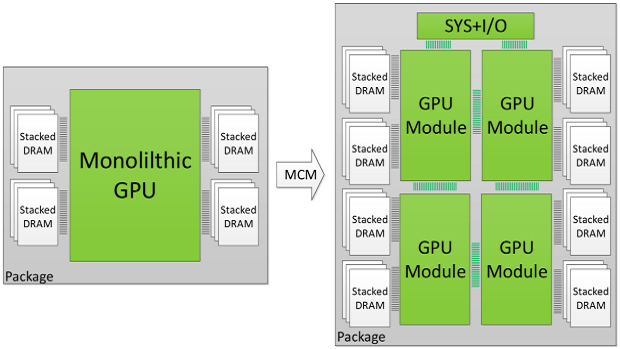
I modi per ottenere prestazioni sempre maggiori, come descritto sempre nello stesso articolo, sono sostanzialmente due: o si alzano le frequenze di lavoro oppure si aumenta il numero di unità di calcolo. Siccome la prima è limitata dalla fisica del silicio e la seconda dagli enormi costi che aumentano sempre di più ad ogni nuovo PP, la soluzione che si sta delineando è quella di creare chip in modalità MCM (Multi Chip Module), ovvero chip che sono formati da più die separati poi “incollati” su un substrato comune che permette loro la comunicazione reciproca.
Il vantaggio evidente è la possibilità di creare un chip formato da die molto più piccoli rispetto ad uno monolitico che contiene le stesse funzionalità di tutti i singoli die. Non tutto è gratis però, visto che questo approccio conduce a problemi di natura diversa, dalla banda necessaria per fare comunicare tutti i moduli tra di loro e verso le memorie (risorsa principale per accedere ai dati, fondamentali per poter fare un lavoro utile), di latenze che aumentano man mano che il numero di singoli die aumenta e di montaggio meccanico dei singoli moduli che risulta essere più critico.
I costi di questo tipo di approccio devono quindi essere valutati attentamente, perché una eventuale diminuzione di costi di produzione non deve corrispondere a limitazioni troppo alte in fatto di prestazioni, previa inutilità della scelta MCM.
## 6.2 MCM, un paio di numeri di esempio

Comparazione tra una soluzione monolitica rispetto ad una MCM
Per rendere la cosa più comprensibile facciamo un semplice esempio senza la necessità di avere numeri precisi (che purtroppo non abbiamo perché a conoscenza dei soli produttori, ma il senso rimane): voglio raddoppiare le prestazioni di un chip di 100mm2 a cui non posso aumentare la frequenza perché già piuttosto alta. Come abbiamo già detto, l’unica altra strada che posso percorrere è raddoppiare le risorse di calcolo del suddetto chip, coerentemente con tutto il supporto necessario perché la computazione sia sostenibile a quel valore nel tempo (quindi cache, banda etc..)
Con una scelta di die monolitico vuol dire raddoppiare le dimensioni del chip e come già sappiamo a doppia area equivale quasi la quadruplicazione dei costi di produzione.
Con una scelta di tipo MCM devo considerare che non basterà solo il doppio del silicio per via di un calo di efficienza ineliminabile dovuto al partizionamento delle risorse di calcolo in più parti separate che devono comunicare su un bus più lento e con maggiore latenza rispetto a quanto possibile in un chip monolitico. Vero che il costo di produzione complessivo in questo caso subisce meno il rapporto esponenziale della crescita con l’uso di die più piccoli: supponendo di dover produrre 2 chip da 120mm2 per avere le stesse prestazioni di uno monolitico da 200mm2 (overhead del 20%), avremo un costo relativo ai 100mm2 di partenza di 1.2*1.2*2 = 2.88 volte invece che i quasi 4 che abbiamo detto prima (rapporto tra costi del silicio: 2.88/4 = 0.7, ovvero risparmio del 30% dei costi di produzione). A questo però dobbiamo aggiungere il costo del montaggio più critico e la costruzione di un interposer.

Connessione tramite interposer di silicio
Ci sono diversi modi per collegare i die tra loro sul substrato che fa da base a tutte le parti di un chip. Fino a certe densità, complessità e frequenze è possibile evitare di dover creare un interposer di silicio grande quanto tutta l’area del chip decisamente (troppo) costoso che invaliderebbe la scelta di una architettura MCM per abbattimento dei costi. Certo si potrebbero fare GPU enormi impossibili con l’approccio monolitico ma il costo sarebbe comunque decisamente molto alto. Comunque anche senza interposer di silicio un certo costo aggiuntivo rispetto all’approccio monolitico c’è. Mettiamo che il costo totale del nostro chip formato da due parti sia 2.88 volte per il silicio e 0.12 (abbastanza ottimistico) per montaggio e interposer = 3 volte quello del chip di partenza da 100mm2. L’approccio multi die ha senso se le prestazioni finali che raggiungiamo con questi costi sono davvero il doppio rispetto al chip di riferimento, esattamente come le raggiungerebbe il chip monolitico raddoppiato di dimensioni.
Ipotizziamo invece che il chip MCM da 120*2=240mmq totali raggiunga solo 1.7 volte le prestazioni rispetto al chip da 100mm2 (ipotizzando quindi un overhead totale del 40%) avremmo che l’aumento della dimensione a 170mm2 per un chip monolitico per raggiungere 1.7 volte le prestazioni del chip da 100mm2 equivale ad un aumento dei costi di 1.7*1.7 = 2.9 volte. Ecco che quindi i costi finali tra chip monolitico e chip multi die non sarebbero così diversi.
I chip MCM hanno quindi senso se la suddivisione del lavoro non porta a overhead troppo elevati e se l’assemblaggio delle parti non comporta costi extra tipo il dover usare un interposer di silicio, come è necessario per il GP100, il GV100 o Vega, che sì sfruttano un approccio MCM per montare le HBM vicino al die di computazione così da favorire bande e latenze verso la memoria diminuendo nel contempo i consumi, ma lo fanno con costi elevati che non sono sostenibili nel mercato consumer esattamente come non lo sono le GPU oltre i 500mm2 se non a prezzi fuori da ogni ragione, e quindi relegati a piccole percentuali di mercato.
## 6.3 Un ritorno dal passato
I primi esempi di chip MCM nel mondo consumer li abbiamo avuti con l’ormai antico Pentium D, il primo dual core di Intel costituito da 2 die separati “incollati” tra di loro che erano la soluzione di Intel trovata per combattere il primo dual core monolitico di AMD, l’Athlon64 X2.
Mentre il Pentium D e sopratutto il successivo Core2 Quad, erano concorrenziale alle soluzioni monolitiche contemporanee di AMD, con l’introduzione del Memory Controller direttamente nel die della CPU (con l’architettura Phenom), la soluzione monolitica otteneva vantaggi prestazionali tali per cui la versione multi chip non era più concorrenziale, e infatti anche Intel passò allo stesso modello monolitico con l’architettura Nehalem.
Dopo anni di creazione di CPU monolitiche con sempre più core (2,4,6,8,10,12,14,18,28 ma anche 72 con le architetture Xeon Phi) più recentemente, il modello MCM è stato ripreso da AMD per creare la sua architettura Zen, in cui fino a 4 die sono collegati tra di loro tramite un bus proprietario (Infinity Fabric) a formare un chip di classe server con 32 core (8 core per ciascun die). Per confronto, Intel arriva a 28 core con il suo approccio monolitico il cui costo di produzione sembra però essere decisamente maggiore per via delle rese minori (sebbene il PP in uso, i 14nm++, sia ormai più che maturo).
L’approccio MCM di Zen però ha reso evidente la problematica della configurazione nUMA (non Uniform Memory Access), dove ogni singolo die è connesso direttamente solo ad una parte della memoria, usufruendo della banda massima di questa, mentre la restante parte della memoria deve essere acceduta tramite la richiesta su Infinity Fabric (il bus che collega i die tra di loro) agli altri die che devono recuperare il dato nella propria memoria locale e trasferirlo al richiedente, sempre tramite il bus comune IF. Tale lavoro, come si vede, impone un overhead abbastanza alto con relativo aumento della latenza che in alcuni casi portano le prestazioni a calare drasticamente (come nota a parte sottolineiamo che le CPU sono molto suscettibili all’aumento della latenza, tanto che le cache sono ottimizzate proprio per questo parametro). Questo problema non si pone sulle CPU monolitiche dove l’accesso è di tipo uniforme (configurazione UMA) e ogni core può accedere liberamente a qualsiasi parte della memoria con il vantaggio della banda totale aggregata di tutti i canali. Ciò ha reso la soluzione AMD appetibile per certi tipi di lavoro e meno per altri, dove creare workaround per evitare i colli di bottiglia dovuti alla configurazione nUMA costa molto in termini di lavoro, codice e RAM, visto che i dati devono essere replicati in più parti della memoria e comunque rimanendo con problemi di prestazioni quando i risultati di un lavoro svolto in parallelo sui core di più die separati devono essere messi insieme (ed eventualmente elaborati ancora).

Il processore EPYC di AMD realizzato con la prima versione di Zen, in configurazione nUMA e MCM. Ogni chiplet ha il suo bus verso una parte della memoria (2 degli otto canali), dividendo così la memoria di sistema in 4 parti distinte.
Il problema della memoria nUMA è ancora più marcato per le GPU che fanno della necessità di accedere a grandi quantità di dati (non replicati) una delle loro maggiori caratteristiche. Le GPU, a differenza delle CPU, soffrono meno dell’aumento di latenza e infatti usano le memorie GDDRx che sono ottimizzate per la banda piuttosto che per la latenza, in parte mascherata dalle grandi cache interne.
Incollare più die come in Zen prima versione produrrebbe una serie di colli di bottiglia che non permetterebbe di avere prestazioni che scalano tanto quanto sono le risorse messe in campo. Pensiamo alle configurazione SLI e CrossFire, sono la cosa più vicina al funzionamento di una GPU MCM in configurazione nUMA. Infatti per evitare colli di bottiglia che renderebbe la configurazione multi-GPU inutile, si replicano i dati nel buffer di ciascuna GPU in modo che la GPU che non li ha nella sua memoria locale non debba chiedere i dati sul lento bus di comunicazione che la collega all’altra.
Anche se i die sono separati e più piccoli di uno monolitico, hanno sempre un costo che aggregato per tutti i die che compongono il chip non può essere superiore a quello del chip monolitico per avere prestazioni simili, altrimenti come detto non ha senso la scelta di un approccio MCM. La configurazione nUMA impedisce di avere prestazioni adeguate ai costi in una GPU MCM. Chiariamo che non è che le prestazioni assolute massime non siano possibili: sono i costi associati per ottenerle che non sono adeguate perché servirebbe un bus che collega ogni die con capacità pari alla banda di accesso alla memoria locale e anche una gran quantità di cache. Tanto silicio e complessità in più che in una configurazione monolitica non sono necessari.

EPYC realizzato con la nuova architettura Zen2 con l’approccio UMA su configurazione MCM. Notare il chiplet più grande in mezzo che è quello dedicato agli I/O. Come si vede c’è un certo overhead di uso del silicio per questo tipo di soluzione. Gli altri 8 chiplet sono quelli che contengono i core di computazione, 8 ciascuno, per un totale di 64 core in un singolo package.
Con la nuova architettura Zen2, AMD ha fatto quello che era naturale fare ma che sembra una mossa di ritorno al passato: rimettere i memory controller fuori dal die (ora chiamato chiplet) che contiene i core, come lo erano prima del Phenom e di Nehalem. A differenza di prima ora comunque rimangono nello stesso package del chip collegati con un bus super veloce. Per questa sua nuova architettura AMD ha usato un chiplet dedicato al solo I/O, cioè un die che è l’unico in grado di operare sulla memoria (e sui bus di comunicazione esterni) in maniera omogenea esattamente come un chip monolitico (configurazione UMA, Uniform Memory Access, ovvero ogni core ha eguale capacità di accesso a tutti gli indirizzi di memoria), ma che poi distribuisce i dati ai chiplet richiedenti attraverso il bus Infinity Fabric (che a loro volta li indirizzeranno alla cache del core interno che ha fatto la richiesta). Rispetto al chip monolitico, la latenza è maggiore (sono richiesti due passaggi in più su un bus esterno prima di avere la risposta) ma elimina il problema principale che nasce da una configurazione nUMA che è l’incostanza dei tempi di accesso ai dati (e quindi esecuzione) che sono visibili in alcune applicazioni sui processori Zen di rima generazione. La eventuale modifica dello scheduler non cambia il fatto che l’accesso non è uniforme e quindi ci sono penalità con alcune operazioni di calcolo che prevedono l’uso di un gran numero di core (che è poi lo scopo di avere un chip con tanti core, no?). NOn ci sono miracoli che si possono fare quando le limitazioni sono di tipo HW.
## 6.4 Una base per il futuro
AMD in teoria potrebbe “incollare” in un progetto MCM un chiplet con una GPU che fa accesso alla memoria tramite il die di I/O come fanno i chiplet che contengono i core di una CPU. La GPU compierebbe il proprio lavoro in parallelo alla CPU, con l’aggiunta che la comunicazione tra CPU e GPU non avverrebbe più tramite bus PCI esterno (se confrontato con una scheda video discreta) ma tramite l’Infinity Fabric che ha banda molto maggiore.
Questo porterebbe alla creazione di un nuovo tipo di APU, con la GPU non più inserita nel die monolitico ma separato dalla CPU. Permetterebbe di avere un chiplet per la GPU con una quantità di risorse di calcolo maggiore rispetto a quelle che oggi possono essere incluse in una APU dal costo ragionevole.
La flessibilità dell’approccio MCM di AMD però non si ferma a questo tipo di soluzioni: infatti permette di creare una intera GPU MCM formata da un numero arbitrario di chiplet, il cui limite è solo la banda garantita a ciascuno per operare senza subire un decadimento prestazionale tale per cui diventa inutile aggiungerne altri (senza tenere conto del costo che diventa un altro limite).
Questa soluzione potrebbe porre fine all’attuale problema delle dimensioni massime possibili con le GPU. Ovviamente non si parla di poter avere una dimensione infinita mettendo un numero arbitrario di die in connessione tra loro su un sub strato, perché comunque le “dimensioni contano”. Le distanze tra i die non possono superare certi valori perché ne risentirebbero le frequenze massime adottabili sul bus (e i consumi) e sappiamo che c’è una limite di scalabilità che è imposto dall’overhead che non può essere zero (legge di Amdahl).
E Nvidia?
Viste le dimensioni attuali delle GPU e delle prossime, come anticipato, non è impossibile credere che anche lei sia sul punto di creare una GPU MCM. Quali caratteristiche avranno è difficile dirlo: nUMA o meno, simmetriche o ibride, cioè formate da chiplet uguali o con caratteristiche diverse, su interposer o substrato organico, con o senza HBM (a seconda del mercato cui sono destinate), sono tutte ipotesi valide in egual modo (anche se l’approccio nUMA comporterebbe non pochi problemi da risolvere e quindi credo sia da scartare a priori).
Per ora le uniche tecnologie che conosciamo per la possibile creazione di una architettura MCM da parte di Nvidia sono quelle adottate per creare le GPU per il mercato HPC: GP100 e GV100.
Per queste sono stati utilizzati un bus ad alte prestazioni punto-punto, l’NVLink e un interposer di silicio su cui montare l’enorme die della GPU e quelli delle HBM. Con queste tecnologie è difficile prevedere la creazione di una GPU MCM per il mercato consumer sufficientemente economica da poter essere creata in massa. Per fare ciò deve usare un approccio diverso, con l’uso di substrati organici come AMD o con qualcosa simile alla tecnologia EMIB di Intel che permette la connessione tra die senza creare un interposer grande quanto la somma di tutti i die che deve sostenere.
Nel mercato di fascia alta invece la creazione di GPU MCM potrebbe creare scenari interessanti anche solo per il fatto di massima libertà di scaling limitata solo dai consumi, tanto i costi in quel mercato se il prodotto è più che valido non sono un problema.
Il fatto che entrambe AMD e Nvidia non abbiano ancora dato alcuna roadmap oltre alle architetture imminenti (AMD si è fermata a Navi, Nvidia all’attuale Turing) credo sia dovuto ad un momento di estrema criticità nelle scelte da fare per la realizzazione delle GPU future. MCM o meno già dal “prossimo giro”, rimarrà comunque interessante vedere quali scelte strategiche saranno condotte per creare GPU sempre più performanti e quali tecnologie saranno supportate per superare quello che ormai sembra un approccio obsoleto al 3D quale la pipeline di rasterizzazione.
Attenzione, non voglio dire che dalla prossima generazione questa sparirà, ma è probabile che, almeno nelle intenzioni di Nvidia che ha da una a due generazioni di vantaggio rispetto ad AMD, questa smetterà di crescere in prestazioni come nel passato per poter lasciare spazio (sia in termini letterali di spazio fisico sul die, sia in termini di investimenti e supporto) al ray tracing.
Credo che Nvidia sia ben conscia del fatto che con il dopo Navi, le cose potranno essere molto diverse da come sono andate finora e l’interesse è vedere cosa creerà per mantenere la sua posizione di vantaggio.
# 7.0 Futuro prossimo
## 7.1 Navi
Sarà quindi Navi una GPU MCM?
Difficile prevederlo ma non sarebbe così sbalorditiva questa configurazione ora che sappiamo come è fatto Zen2 e quali modifiche, in un certo senso rivoluzionarie (anche se prese dal passato), sono state introdotte con essa.
Sarà Navi ancora GCN e quindi con unità stile Turing assenti?
Non è semplice prevedere le mosse che AMD ha intenzione di fare per il prossimo futuro. Possiamo solo fare qualche ipotesi conoscendo quello che ha fatto finora:
– l’allontanamento di Koduri e l’arrivo della nuova dirigenza probabilmente significa che GCN non ha futuro. GCN, per tutto quanto detto negli articoli precedenti è una architettura che si è dimostrata inferiore alle capacità della concorrenza su tutti i fronti, specialmente in quelli costi/performance. Il suo abbandono è quindi auspicabile se AMD vuole tornare a fare reale competizione anche nel campo mobile dove è una generazione indietro per quanto riguarda i consumi.
– AMD si è presa due anni di tempo dopo il fallimentare Vega, per creare una nuova architettura (o revisione di GCN) in grado di cambiare le carte in tavola. Un deja vù di Fiji, che ha condotto a Polaris. Turing nel frattempo però ha portato l’asticella ancora più in alto (anche senza considerare le nuove funzionalità) e AMD non può aver creato Navi solo per aver un vantaggio limitato nel tempo contro Turing. Nvidia passerà ai 7nm anche lei prima o poi (probabilmente inizio 2020) e se Navi non sarà all’altezza sarebbero ulteriori 2 anni buttati via, fino all’arrivo della prossima architettura. Il PP post 7nm non sembra essere tanto vicino (i 7nm+ con EUV non saranno questo gran cambiamento che porterà chi lo adotterà a fare meglio solo per i vantaggi del PP, praticamente forse porterà solo una diminuzione dei costi, sempre utile, ma non sufficiente come abbiamo visto) e altri anni ad inseguire Nvidia non le farebbero proprio bene sia in termini di immagine che di bilanci.
– Navi andrà ad equipaggiare le nuove console. E’ notizia di questi giorni che Sony punta al 4K a 60FPS con una GPU da 11TFLOPS. AMD non può arrivare a quelle prestazioni consumando 200W come fa ora e ci deve arrivare con una GPU che scala decentemente, cosa che GCN sia con Fiji che con Vega ha dimostrato essere in difetto.
– Sappiamo che GCN ha un forte problema nello scalare con grandi quantità di unità di calcolo (vedesi come detto Fuji e Vega) e quindi deve cambiare approccio per realizzare GPU che possano competere nel mercato di alta gamma. Il fatto che abbia annunciato che Navi non avrà GPU create per tale fascia lascia un po’ perplessi. I motivi potrebbero essere l’adozione del nuovo PP a 7nm, che potrebbe costare molto e fare GPU grandi con margine basso per il mercato consumer non sarebbe economicamente sostenibile come imparato con Vega, oppure la presa di coscienza che è inutile creare il terzo costoso flop di fila fino all’arrivo di una architettura radicalmente diversa che possa davvero trarre beneficio dei mm2, dei W e delle eventuali costose HBM.
– Se AMD non ha alcuna delle feature che Nvidia ha portato con Turing e che probabilmente saranno realmente sfruttate proprio quando Navi farà la propria apparizione (molto probabilmente autunno 2019) l’esito della competizione sarà già decisa. Non parliamo solo del ray tracing come lo abbiamo visto nelle 2 patch realizzate in un mese e applicate a motori di rendering tradizionali che hanno prestazioni terribili con effetti esagerati. Come detto le nuove unità di accelerazione possono essere usate in diversi modi, più subdoli ma lo stesso con notevoli impatti grafici e non averle potrebbe essere un handicap. Di certo essere fornitore unico delle GPU per il mercato delle console può rallentare l’adozione delle nuove feature, ma la percezione del valore aggiunto (che non c’è) potrebbe porre Navi a gareggiare con la fascia più bassa nel mercato PC.
Potrà Navi aggiungere le unità di accelerazione ray tracing e inferenza come quelle di Turing in un chiplet apposito se realizzato come MCM?
Le probabilità sono molto basse: sia le unità RT che i tensor core lavorano a stretto contatto con le unità FP e INT degli shader e quindi aggiungerle come unità separate che agiscono sugli stessi dati imporrebbe un overhead non indifferente di continue copie di dati tra i chiplet al punto tale che non credo si avrebbero reali vantaggi prestazionali anche se fossero in numero superiore a quelle introdotte su TU102.
Presupporre la presenza di tali unità inserite direttamente negli Streaming Processor significa pensare che AMD abbia rivisto completamente l’architettura rispetto a quello che è GCN. Come detto, non possiamo dire con gli elementi che abbiamo oggi se Navi sarà ancora basata su GCN oppure un reale step avanzato rispetto a questo, anche se le ultime dichiarazione di AMD fanno prevedere che Navi non avrà il supporto all’accelerazione ray-tracing e che questa dovrebbe arrivare solo con le architetture future.
# 7.2 E Intel?
Come è noto Intel sta attraversando un periodo un po’ “oscuro” della sua vita.
Rimasta per anni ancorata all’architettura monolitica Core che le ha dato grande vantaggi contro le architetture Phenom e sopratutto Bulldozer della concorrente AMD, oggi con l’arrivo dei chip realizzati con l’architettura MCM Zen che ha come miglior caratteristica, oltre ad un IPC molto vicino a quello di Intel, il poter scalare facilmente e quindi offrire molti più core rispetto al passato in tutte le fasce di mercato, soffre la possibilità di una offerta competitiva.
Nel mercato grafico di Intel non c’è né una lunga né una esaltante storia da raccontare.
Il suo focus, fino a poco tempo fa, è stato sempre quello di realizzare architetture grafiche per processori grafici integrati, prima nei North Bridge, poi nel die della CPU, senza particolare investimenti sull’aumento prestazionale di quello che sono sempre stati acceleratori grafici sufficienti un po’ per tutto tranne che per il gioco più estremo (ultime novità: uso di enormi quantità di eDRAM per garantire un buffer con grande sui portatili e fusione tra una CPU Intel e una GPU AMD + HBM per realizzare sistemi portatili ad alte prestazioni).
Il passato di può riassumere così. 10 anni or sono Intel tentò una mossa a sorpresa di creare una GPU senza unità fixed function di rasterizzazione (quelle che ancora oggi infarciscono le architetture delle rivali) con un numero elevato di unità di calcolo (x86 based) che avrebbero dovuto farne le veci.
Risultò un fiasco totale, dato che nessuna potenza computazionale general purpose può fare lo stesso lavoro in maniera efficiente quanto unità costruite ed ottimizzate ad hoc (le suddette unità fixed function che sono in numero abbondate nelle GPU moderne) e la dimensione, nonché il consumo di questo tipo di computazione non è sostenibile Ricordando l’articolo sui processi produttivi applicati alle GPU dove di diceva che consumi e dimensioni sono teoricamente scalabili a piacere per ottenere un valore prestazionale qualsiasi, Intel ha tentato di usare una soluzione che richiedeva 300W e 700mm2 di silicio (a 45nm) per fare quello che faceva ai tempi una scheda del 2006 (quando in contemporanea Nvidia immetteva sul mercato il GT200 da 576mm2 a 65nm con prestazioni completamente diverse).
Nonostante il flop clamoroso, Intel fu la prima a cercare di abbandonare la pipeline di rasterizzazione basata su unità fixed function, e forse se le condizioni fossero state diverse, magari sarebbe anche potuto nascere una soluzione grafica diversa. Dalle ceneri di quel fallimento nacque comunque il progetto MIC (Many Integrated Core) che partorì le varie schede Knight per finire nel più famoso Xeon Phi che fino a poco tempo fa erano le concorrenti di Nvidia nel mercato HPC, prima che Nvidia mettesse le unità ad hoc per l’IA in GP100, il mercato HPC si spostasse sul calcoli non necessariamente FP64 o maggiori e Intel non avesse nuovamente un processo produttivo più avanzato per realizzare le proprie soluzioni, terminando la possibilità di questa di concorrere (sia tecnologicamente che economicamente) con core general purpose x86 dove in verità a fare la parte del leone erano le enormi unità AVX esterne e dove l’architettura x86 non era mai stato un vantaggio reale rispetto ad altre architetture.
La domanda che uno si pone è se queste condizioni ci sono ora.
La risposta è dipende da qual è l’orizzonte temporale che si vuole prendere in considerazione. Ricordando che una architettura richiede dai 3 ai 4 anni di sviluppo prima di comparire sul mercato, e pensando alla svolta che Nvidia ha dato al marcato con l’introduzione delle unità RT, si può dire che Intel ha la possibilità di poter creare una architettura che sia competitiva (se non superiore) dal punto di vista della capacità puramente computazionale rispetto a quanto AMD e Nvidia siano riuscite a fare finora che potrebbero compensare una minore efficienza delle unità fixed point in cui Intel ha molta meno esperienza e che comunque saranno nel tempo sempre più marginali alla creazione finale dell’immagine (che non vuol dire inutili, alcune unità fixed funzioni rimarranno comunque in uso e probabilmente altre diverse ne verranno create, come lo sono le RT per esempio).
Probabilmente non sarà la prima architettura di Intel quella che turberà i sogni di Nvidia e forse anche di AMD, anche se sarà comunque da valutare l’aggressività dei prezzi di Intel che potrebbe anche voler “svendere” per fare velocemente quote di mercato, ma nel futuro Intel sarà sempre più un avversario di cui tenere conto anche in termini tecnologici che non permetterà a nessuna delle storiche rivali di prendersi dei periodi di pausa.
Quindi quali processi produttivi userà Intel?
Sicuramente non potrà permettersi di usare un PP sorpassato per risparmiare sui costi di produzione dato che sia Nvidia ma sopratutto AMD puntano ad usare il più nuovo ed avanzato disponibile sul mercato. Vista la data di rilascio della prima architettura grafica “discreta” nel 2020, di sicuro si parla di 10nm o forse anche dei futuri 7nm di Intel stessa. Ma se Intel dovesse avere problemi di capacità produttiva con i nuovi PP (che ricordiamo costano sempre di più e oggi siamo a decine di miliardi di investimenti per ciascuno d essi) potrebbe comunque rivolgersi anche lei alle fonderie terza come TSMC e Samsung allineandosi a quanto disponibile agli altri concorrenti.
Questo vorrebbe dire che conterà per tutti davvero realizzare architetture efficienti sotto tutti i punti di vista, pena essere lasciato indietro in tutti quegli indici che oggi sono il cruccio di AMD (performance/mm2 e performance/W oltre che in termini di prestazioni assolute) e di diver recuperare terreno (e quote di mercato) a suon di prodotti svenduti.
# 8.0 Considerazioni finali
Siamo giunti alla conclusione di questo piccolo viaggio.
Non è stato breve e comunque molti dettagli e argomenti sono stati tralasciati ma l’intenzione non è quella di sostituire l’enciclopedia britannica con dati e informazioni fine a se stesse, ma di creare una veduta complessiva che metta le cose insieme e al loro posto e che stimoli una analisi critica dei fatti che sia quanto più oggettiva possibile.
L’oggettività di misura nella predicibilità che permettono le teorie che si creano per spiegare gli eventi.
Qui mi permetto di dire che nonostante certi commenti negli articoli precedenti di persone completamente ignoranti della materia ma con il desiderio di far sembrare le cose diverse da quella che in realtà sono solo per mera e inutile “tifoseria”, i fatti sono rimasti quelli e la loro interpretazione con collegamento causa-effetto ha finora dimostrato di essere corretta, visto che da quanto scritto nel 2015 a oggi il tutto è tornato con ben poche sorprese.
GCN è purtroppo sempre quella dal day one e ha i problemi del day one che abbiamo raccontato. Oggi, inizio 2019, GCN è ancora l’architettura “che la prossima versione farà meglio”. Ovviamente pensando che la concorrenza se ne starà ferma e lascerà AMD con un PP di vantaggio.
Inutile continuare a battere un cavallo morto, ma ormai è chiaro a tutti che GCN non importa se sarà, il problema è che non è mai stata. La conferma di tutto ciò è quanto prospettato nel 2015: in mancanza di una svolta nel miglioramento di tale architettura avremmo avuto un dominio completo da parte di Nvidia con conseguente continuo aumento dei prezzi. Fine 2018, lancio di Turing, i prezzi sono schizzati a valori stellari con AMD che sta vendendo Vega sottocosto pur di avere in catalogo una scheda che sia mediamente potente quanto la fascia media della concorrenza.
Quando Nvidia porterà il successore di Turing a 7nm nel mondo consumer (ovvero come sta facendo da diversi anni a questa parte solo quando il PP è maturo a sufficienza) si vedranno nuovamente le differenze tra le architetture a parità di PP e non sarà certo una sorpresa vedere l’architettura Nvidia consumare meno per andare di più. E non essere nemmeno tanto diversa in dimensioni, pur avendo le nuove unità di calcolo e le pipeline per il Mesh shading







