Così come i linguaggi di programmazione Object Oriented hanno quasi completamente sopraffatto quelli procedurali, per lungo tempo si è pensato che i Database Object Oriented OODBMS fossero destinati a prendere il posto di quelli relazionali.
La storia di questi database inizia alla fine deli anni ‘80 e trova tra i suoi protagonisti Won Kim ed il suo progetto ORION.

Won Kim
Tra i principali vantaggi degli OODBM troviamo: ereditarietà, poliformismo, templates, e clustering individuale degli oggetti, tutti elementi noti al mondo della programmazione ad oggetti.
In realtà questa tipologia di DB ha sempre incontrato grandi difficoltà nella propria diffusione, in primis la mancanza di una versione standardizzata di OQL (Object Query Language, l’omologo si SQL) che obbliga gli utilizzatori ad imparare un nuovo “dialetto” e a riscrivere buona parte del codice in caso di sostituzione dell’OODBMS. Inoltre le vari implementazioni sono tutt’altro che affidabili e non sempre le interrogazioni rispondo nel modo atteso.
Esiste anche un discorso “concettuale” legato al fatto che quando un oggetto non è presente in memoria, in sostanza, smette di essere un oggetto e i suoi attributi vengono visti in modo naturale come elementi da memorizzare in una forma tabellare, sfruttando le capacità di aggregazione ed elaborazione dei dati dei classici sistemi relazionali.
Per cercare di superare parte di questi limiti, nel 1989 viene istitutio l’ Object Management Group (OMG) con l’obiettivo di standardizzare lo sviluppo e le funzionalità (in particolare OQL) degli OODBMS e il cui ultimo lavoro è lo standard ODMG 3 rilasciato nel 2001.
 Versant e O2 sono sicuramente tra gli OODBMS più noti, oltre alle soluzioni ibride chiamate ORDBMS che permettono di memorizzare i dati o come oggetti o come tabelle, cercando di sfruttare le peculiarità sia degli OODBMS che degli RDBMS.
Versant e O2 sono sicuramente tra gli OODBMS più noti, oltre alle soluzioni ibride chiamate ORDBMS che permettono di memorizzare i dati o come oggetti o come tabelle, cercando di sfruttare le peculiarità sia degli OODBMS che degli RDBMS.
Sempre nel campo delle soluzioni evolutive/alternative agli RDBMS, una proposta anch’essa passata negli anni in secondo piano è quella dei database basati su XML e sui linguaggi di interrogazione XQuery e XPath. In realtà questo tipo di sistemi sono nati sotto la spinta di utilizzare un linguaggio di mark-up universale e indipendente a tutti i costi, portando però a soluzioni poco performanti, espansive (ogni singolo elemento richieste una serie di tag descrittivi), e senza nessun controllo sugli accessi ai dati e sulla loro consistenza.
La GUI di BaseX 6.6, uno dei database XML based più noti
Al contrario quello che invece sembra la nuova linea evolutiva dei database è identificabile sotto il cappello NoSQL o anche NRDMBS. Si tratta di sistemi concepiti in modo diametralmente opposto a quelli relazionali e che devono la propria denominazione all’italiano Carlo Strozzi, già presidente dell’Italian Linux Society, che conia il termine nel 1998 per indicare il proprio progetto inerente un piccolo database non relazionale.

Carlo Strozzi
Nel 2000 un contributo fondamentale ai sistemi NoSQL arriva da Eric Brewer, che, in un KeyNote alla conferenza “Principle of Distributed Computing”, presenta il CAP Theorem relativo all’utilizzo delle basi dati in ambito distribuito. Ogni lettera di CAP sta a rappresentare una caratteristica del sistema distribuito su cui si sta lavorando:
- Consistency (Consistenza): tutti i nodi del sistema distribuito devono riflettere le modifiche effettuate;
- Availability (Disponibilità): il sistema è sempre in grado di rispondere alle richieste, risultando praticamente sempre operativo;
- Partition Tollerance (Tolleranza al Partizionamento): anche se la comunicazione si interrompono tra due punti del sistema, il sistema deve comunque continuare ad essere raggiungibile.
e di queste, secondo il teorema, se ne possono avere contemporaneamente valide solo 2, potendo scegliere quali prediligere in base alle proprie necessità.
 La prima società ad abbracciare questo “mondo” è Amazon grazie all’intuito del suo CTO Werner Vogels che, basandosi sul white paper redatto da Seth Gilbert e Nancy Lynch nel 2002, avvia il progetto interno noSQL SampleDB (sviluppato in Erlang). Wogels sceglie di prediligere i fattori AP, sacrificando la Consistenza dei dati e introducendo il concetto di “eventualmente consistente”, ovvero la propagazione ritardata delle informazioni a tutti i nodi.
La prima società ad abbracciare questo “mondo” è Amazon grazie all’intuito del suo CTO Werner Vogels che, basandosi sul white paper redatto da Seth Gilbert e Nancy Lynch nel 2002, avvia il progetto interno noSQL SampleDB (sviluppato in Erlang). Wogels sceglie di prediligere i fattori AP, sacrificando la Consistenza dei dati e introducendo il concetto di “eventualmente consistente”, ovvero la propagazione ritardata delle informazioni a tutti i nodi.
 Le soluzioni NoSQL sono oggi alla base di quasi tutte le grandi web application: dall’App Engine Data Store di Google fino ad arrivare a Cassandra utilizzato da Facebook e Twitter e sviluppato dalla Apache Software Foundation che cura anche CouchDB.
Le soluzioni NoSQL sono oggi alla base di quasi tutte le grandi web application: dall’App Engine Data Store di Google fino ad arrivare a Cassandra utilizzato da Facebook e Twitter e sviluppato dalla Apache Software Foundation che cura anche CouchDB.
Con gli NRDBMS è possibile memorizzare un elemento atomico, con tutte le informazioni rilevanti, senza dover ricorrere ai costosi (in termini computazionali) join per aggregare i dati e senza spreco di spazio dovuto a campi non significativi. Un altro punto di forza è, inoltre, la possibilità di scalare orizzontalmente il sistema, aggiungendo nuovi nodi ai cluster senza provocare alcun blocco operativo unitamente al fatto che questo tipo di storage si adatta particolarmente allo sviluppo di applicazioni object oriented abbattendo la necessità di realizzare livelli di mapping/scambio dati.

Ma ance i NoSQL hanno i propri limiti e il principale è la mancanza dell’integrità dei dati. Infatti non esistendo relazioni (in senso stretto), il sistema non può garantire che le operazioni effettuate mantengano in uno stato consistente le informazioni esistenti. Questo sposta al livello applicativo tutti i controlli necessari, trasformando di fatti l’NRDMBS in uno storage altamente flessibile ma sostanzialmente “poco intelligente” (come piace al sottoscritto).
In conclusione è doveroso precisare che con “NoSQL” si identificano famiglie di storage molto differenti tra loro: Column Family, Document Store, Graph Database e Key-Value Stores,, ognuna con caratteristiche esplicitamente pensate per ambiti ben precisi.
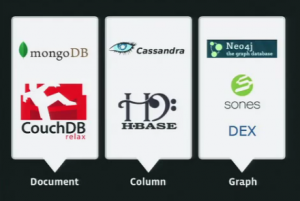
Famiglie NoSQL
Si chiude così il nostro viaggio attraverso l’evoluzione dei database che non mancherà in futuro di riservarci straordinarie innovazioni. Come sempre ringrazio tutti i lettori e un arrivederci al prossimo viaggio nella storia dell’informatica.







