Questa settimana ho deciso di alterare l’ordine dei post della rubrica, per cui non rispetterò l’alternanza tra sensori digitali e architettura dei chip grafici e continuerò a parlare delle operazioni di tessellation.
Questa scelta è basata su una motivazione ben precisa che sarà più chiara nei prossimi giorni e riguarda una novità, anzi, un nuovo acquisto di AD, che sarà, per il momento, ospite della mia rubrica e colmerà le mie lacune in campo fotografico. Si tratta di qualcuno molto noto nel forum di fotografia digitale di Hardware Upgrade. Per il momento non aggiungo altro e sono sicuro che si tratterà di una gradita sorpresa per tutti gli appassionati di fotografia.
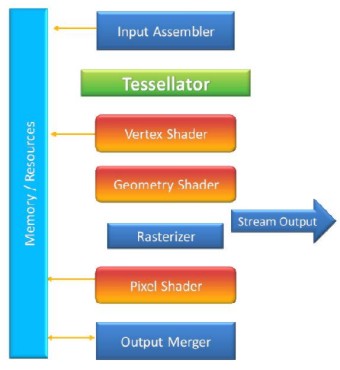
Fatta questa premessa, partiamo subito con l’argomento di oggi, riprendendo da dove ci eravamo lasciati la settimana scorsa. Nell’ultima parte avevamo messo a confronto la pipeline DX9 classica con quella modificata per aggiungere un hardware tessellator su Xenos. Nel passaggio alle DX10, la pipeline di rendering si arricchisce di un nuovo stadio, quello noto come Geometry Shader (GS), che fanno tante belle cose, di cui parleremo in altra sede (poichè non sono argomento del presente articolo): mi limiterò a dire che il loro input è costituito da primitive e il loro output da nuove primitive che saranno la base per le successive operazioni di rasterizzazione.
Nei GS si supera il limite tipico dei VS in cui ad un vertice in input corrispondeva un vertice in output, poichè danno la possibilità di eseguire operazioni di “amplificazione/deamplificazione” delle geometrie permettendo di aumentare o ridurre il numero dei vertici in uscita a seconda dell’occorrenza. La sottostante immagine rappresenta una pipeline DX10 e DX10.1 con l’aggiunta di un hardware tessellator (la cui presenza, ricordo, non è contemplata nelle suddette API)
La combinazione di una pipeline DX9 con l’aggiunta di un tessellator e dei GS, permette di ottenere alcuni interessanti risultati a livello di elaborazione.
- Combinare la tessellation con le operazioni di instancing; abbiamo visto che il GI permette la ripetizione di una singola mesh presa come modello all’interno di un frame. Il risultato è che è possibile, ad esempio, partendo dalla struttura di un albero, creare un’intera foresta semplicemente replicando la pianta presa come modello e, in caso, variando alcuni parametri come il colore, per dissimulare l’impressione di ripetitività. In pratica, diventa possibile, ad esempio, rappresentare un’intera armata di un RTS, con una singola mesh.
- Altra possibilità è quella di utilizzare una combinazione di tessellation e GS per stabilire dinamicamente il LoD e, di conseguenza, il livello e la tipologia id tessellation da applicare; il che permette il ricorso alla adaptive tessellation che permette di ottenere notevoli incrementi prestazionali rispetto al continuous tessellation mode (in seguito si entrerà un po’ più nel dettaglio, presentando queste due m,odalità di tessellation).
- E’ possibile usare l’output dei vertex shader per calcolare l’edge tessellation factor e per eseguire, sui control point tutte le operazioni necessarie. I dati in uscita dai VS, infatti, come si vede dallo schema, possono essere immagazzinati all’interno di appositi buffer o fatti ricircolare all’interno della pipeline, tornando all’input assembler e, quindi, al tessellator, oppure essere inviati ai GS.
Occorre sottolineare che, nella prima parte di questa nostra trattazione, avevamo affermato che i vertici in input potevano variare da un minimo di 1 ad un massimo di 32. Di fatto, fino alle DX10 comprese, il limite messimo era fissato a 16 e solo a partire dalle DX10.1 è stato innalzato a 32. Questo significa che i chip DX9 e DX10 che svolgono operazioni di tessellation non possono avere in ingresso ai VS ed agli HS più di 16 vertici mentre per i chip DX10.1 e DX11 questo limite è pari a 32.
Le innovazioni elencate in precedenza che agli occhi di un profano possono sembrare di poco conto, aumentano in maniera considerevole la flessibilità del tessellator e fanno, in pratica, la differenza tra una tessellation di tipo programmabile ed una di tipo fixed function.
Infine arriviamo alla pipeline DX11 di cui riporto lo schema logico (che non coincide necessariamente con quello fisico, ovvero con il modo in cui sono disposti i circuiti all’interno del chip)
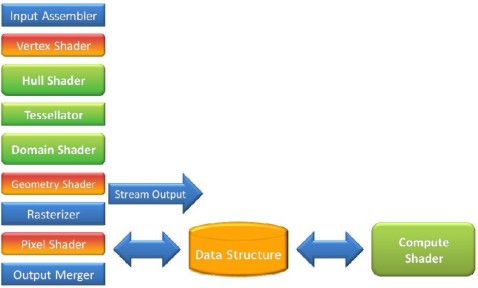
e per il cui funzionamento, in linea di principio, rimando all’articolo della settimana scorsa.
Quelle viste finora, sono implementazioni delle operazioni di tessellation che è possibile trovare solo su chip marchiati ATi, oppure, come ha fatto giustamente notare l’utente streamX la scorsa settimana, sulla PSP, il cui tessellator è di tipo fixed function e ricorda quello visto per Xenos. Con le DX11, però, la tessellation è diventata una feature necessaria per potersi dichiarare D3D compliant. Diamo un’occhiata, dunque, la modo in cui ATi e nVidia hanno implementato questo tipo di operazione all’interno delle loro GPU di ultima generazione.
Da un lato abbiamo ATi che ha seguito pedissequamente le indicazioni date da Microsoft; per cui il blocco dedicato dedicato alle operazioni di tessellation è composto dalle due unità programmabili, hull e domain shader, e dal vero e proprio tessellator. Dallo schema di RV870 emerge un altro elemento importante
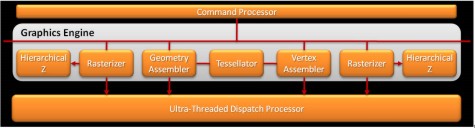
ovvero la presenza del doppio rasterizer. La sua importanza è presto spiegata: il numero di rasterizer presenti determina il numero di dati relativi alla geometria che è possibile avere in input. Quindi, in RV870, di fatto, viene raddoppiato quel numero di 32 vertici (di tipo vect4, equivalenti, quindi, a 128 scalari) che era il limite per RV770 (mentre GT200 e G80 erano fermi a 16). Quando nVidia, parlando di Fermi, proclama che da NV30 a GT200, in versione 285 GTX, la potenza dei calcoli dei pixel shader è aumentata di 150 volte mentre, invece, quella geometrica si è soltanto triplicata, non ha torto: sia NV30 che GT200 sono limitati dall’avere un solo triangle set up engine e dal fatto che il numero di dati in input previsto è, sia per le DX9 che per le DX10, pari a quello di 16 vertici.
E visto che abbiamo introdotto il discorso su Fermi, vediamo anche l’implementazione che nVidia ha fatto delle operazioni di tessellation sul suo chip di ultima generazione. Per farlo, ci aiuteremo con le solite figure
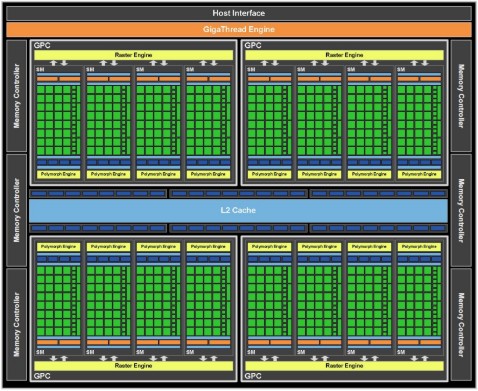
Innanzitutto, dalla figura si vede che GF100, nella sua versione top, ovvero con 512 ALU attive, ha 16 Polymorph Engine (PE) e 4 Raster Engine (RE). Questi utlimi permettono di superare il limite imposto dalla presenza di un unico motore di triangle set up che affligge i chip della precedente generazione della società di Santa Clara. In questo modo, il limite del numero di vertici che è possibile inviare in input al motore geometrico sale a 64 (16 per RE), pareggiando il risultato raggiunto da ATi con RV870. I PE sono invece l’interpretazione data da nVidia dell’hardware tessellator. Ma vediamo un po’ più da vicino come è composto un singolo PE
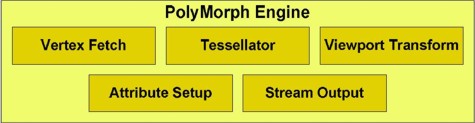
Mettendo a confronto questa immagine con quella precedente e comparandole entrambe con quella della pipeline DX11, si nota come la prima cosa che salti all’occhio sia il fatto che GF100 non ha una ma 16 unità di tessellation e, inoltre, in queste unità mancano del tutto Hull e Domain Shader.
L’idea di nVidia è, infatti, quella di fare uso di un tessellator di tipo “distribuito”. Questo tipo di implementazione non presenta, a livello di funzionamento, differenze con quella classica proposta dalle DX11 se non per il fatto che le funzioni che dovrebbero svolgere Hulle Domain Shader sono svolte da Vertex e Geometry Shader. Il tessellator resta sempre di tipo Fixed Function. Il flusso di dati prevede, dunque, l’invio dei vertici ai VS e, da questi, direttamente al tessellator e, quindi, di nuovo allo shader core, questa volta per le operazioni di domain shading “emulate” dai geometry shader.
Due implementazioni differenti tra loro alla cui radice c’è anche una diversa scelta a livello architetturale fatta sull’intero chip. Da un lato ATi con la sua idea di chip piccolo che, grazie alla scelta delle alu di tipo VLIW, può permettersi di stivare un gran numero di unità di unità di shading in pochissimo spazio, riducendo al minimo indispensabile la logica di gestione e controllo del chip ma puntando, per il resto, ad unità altamente specializzate, dall’altro nVIDIA che insegue il sogno di realizzare una GPU CPU-like e nel fare ciò, al contrario, moltiplica la complessità dei thread processor degli scheduler ma si trova costretta a dover sfruttare la massimo ogni unità di calcolo all’interno del chip.
D’altra parte, come i lettori di questa rubrica sicuramente sanno, nVIDIA si trova di fronte ad una scelta obbligata: non potendo pordurre CPU, al contrario di Intel ed AMD, deve spostare l’interesse sui calcoli di tipo GP su GPU. AMD, dal canto suo, ha il vantaggio di poter mettere in cantiere, a partire già dalla prossima generazione di architetture, dei SoC integranti core di tipo CPU e GPU sullo stesso die.
Ma, poichè è prematuro parlar di cosa ci riserverà il futuro, limitiamoci, per ora ad osservare ciò che accade nel presente e, nello specifico, cerchiamo di approfondire il discorso sulla tessellation. Proprio a tale scopo, nella prossima puntata, partendo dal questa breve disamina sulle architetture proposte da ATi e nVIDIA, faremo qualche breve considerazione sulle presunte prestazioni e sugli eventuali colli di bottiglia che le due implementazioni possono daterminare.








