
Le scorse settimane avevamo visto che cos’è una texture, come la si può generare e in che modo utilizzarla.
Abbiamo anche visto che anche per le operazioni che coinvolgono le texture si può avere generazione di artefatti; in particolare ciò può avvenire, ad esempio, quando un texel non coincide perfettamente con il pixel che deve andare a ricoprire, oppure quando si hanno delle transizioni tra mappe aventi diversi valori di LoD.
Nel processo di genesi di una texture, si è visto come ad ogni texel viene assegnato un valore che dipende dal colore del pixel che deve andare a coprire e dal tipo di materiale che la texture deve “simulare”.
Questo significa che, in teoria, ogni texel dovrebbe andare a coprire esattamente il pixel ad esso assegnato. Se ciò non avviene perchè il texel è troppo grande o troppo piccolo, si generano artefatti dovuti alla sovrapposizione di un texel con più di un pixel nel primo caso e alla necessità di “stirare” il texel nel secondo caso.
Nel caso di texture map con troppi texel rispetto ai pixel, accade, in pratica ogni pixel finisce col mappare più texel. Questo dà origine a quella tipologia di artefatti noti come texture swimming e pixel popping, termini che indicano quell’artefatto grafico che si nota quando, ad esempio, durante un gioco, si cambia la visuale avvicinandosi ad una parete (ad esempio effettuando una veloce rotazione o un rapido avanzamento) e che si traduce in un “movimento” di parte della superficie della parete stessa.
L’immagine sottostante è di tipo statico e rende solo in parte l’idea di ciò che sto dicendo
Nelle due aree indicate si notano degli artefatti e si intuisce che si è determinata una discontinuità nella texture che riveste le pareti e il pavimento anche se non risulta evidente l’effetto provocato dalle texture “mobili”.
Nel caso di texture map con pochi texel rispetto ai pixel, viceversa, avviene che a più pixel corrisponda lo stesso texel. L’artefatto che si genera è quello che rende l’immagine “blocchettosa”, ovvero introduce delle scalettature come quelle mostrate in basso

Poiché è molto raro che una texture map coincida perfettamente con la relativa mappa di pixel, risulta evidente che questi artefatti sono piuttosto comuni. Questo obbliga a scartare l’adozione di tecniche di texturing che prevedano semplici operazioni di point sampling, ovvero operazioni che si limitano a mettere in corrispondenza pixel e texel senza ulteriori interventi.
Da queste considerazioni, risulta chiara l’esigenza di introdurre, anche per le texture, delle tecniche di filtraggio analoghe a quelle viste nel caso dell’aliasing. In effetti non è sbagliato parlare di aliasing e, di conseguenza, di antialiasing anche nelle operazioni di texturing.
Uno dei metodi di filtraggio più semplici è quello bilineare; si basa sul principio dell’interpolazione lineare tra coppie di texel contigui a quello su cui si applica il filtro, in maniera non dissimile a quanto visto per l’applicazione di un MSAA di tipo box 4x. La figura sottostante rende, visivamente, l’idea di ciò che ho tentato di descrivere a parole

Per ogni pixel si scelgono i 4 texel più vicini e si fa un’interpolazione lineare a 2 a 2, utilizzando delle opportune funzioni peso, per determinarne il colore. Questo metodo permette di attenuare le transizioni di colore tra texel contigui (qualcuno trova qualche analogia con il MSAA?).
Si tratta di una texnica di filtraggio che con le odierne GPU risulta decisamente a buon mercato ma che non risolve del tutto i problemi a cui si è fato cenno in precedenza. In particolare, il bilinear filtering non risulta efficace quando ci si trova di fronte a transizioni tra differenti sample di una mipmap.
Il trilinear filtering si applica facendo un’interpolazione di tipo bilineare tra due sample contigui della stessa texture, ricavati dall’operazione di mipmapping e, in seguito, interpolando linearmente i risultati così ottenuti. Quindi, di fatto, un filtro trilineare fa uso di 8 campioni di texel, 4 per mappa e di una doppia interpolazione bilineare seguita da un’interpolazione lineare.
Pertanto, uno schema tipico di filtraggio potrebbe essere quello rappresentato in figura
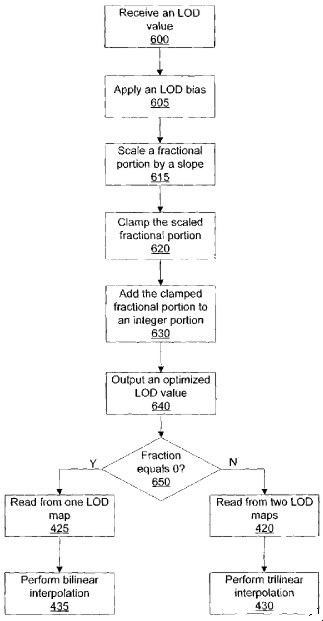
da cui risulta evidente che, se dall’analisi del LoD dovesse risultare che la transizione è tra texel della stessa mappa, è sufficiente applicare il filtraggio bilineare; in caso contrario, ovvero in caso di transizione tra mappe differenti, è opportuno, se non necessario, ricorrere al filtro trilineare.
Un ulteriore e più accurato metodo di filtraggio, che fa sempre uso di interpolazioni di tipo lineare, è quello anisotropico che nella seguente immagine viene messo a confronto con il point sampling e con il bilinear
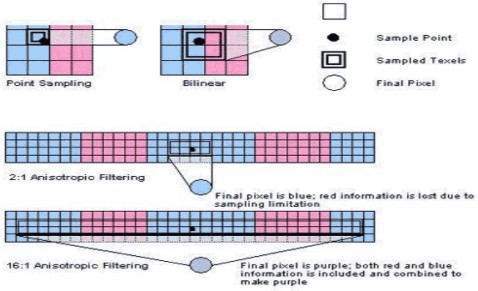
Nella prima e nella seconda immagine, in alto, sono riprodotti, rispettivamente, il point sampling e il bilinear filtering applicati al pixel indicato dal punto nero. Nella terza immagine c’è l’anisotropic con 2 soli sample (2:1). Faccio una breve digressione per spiegare questa notazione; innanzitutto, il filtro snisotropico si chiama così perchè la sua applicazione non è uniforma in tutte le direzini ma varia a seconda della direzione.
In particolare, nelle immagini, si vede il filtro applicato parallelamente all’asse X. Il valore 2x (o 2:1) sta a significare che, partendo dal pixel su cui viene applicato, l’interpolazione si fa tra i 2 texel immediatamente alla sua destra e i 2 alla sua sinistra, mentre nella direzione opposta (asse Y) si estende per un texel (l’immagine è sbagliata ma non ne ho trovato di corrette).
Quindi, in totale, i texel coinvolti sono 4. se si applica la modalità 16x, i texel da selezionare sono i 16 alla destra e i 16 alla sinisra del pixel di partenza, sempre considerando un’estensione di 1 texel nella direzione perpendicolare a quella di applicazione del filtro. In questo caso, si passa a 32 texel complessivi (quelli compresi nel rettangolo nero).
Il filtro anisotropico non viene applicato a tutta l’immagine ma alle sole transizioni tra differenti livelli di mipmap e può essere abbinato al filtro bilineare o trilineare sul resto dell’immagine. Poichè abbiamo parlato anche di texture 3D, vediamo come si applica l’anisotropic in questo caso. Per farlo, mostrerò una comparazione tra anisotropico 2D e anisotropico 3D applicato lungo la bisettirce del II e IV quadrante
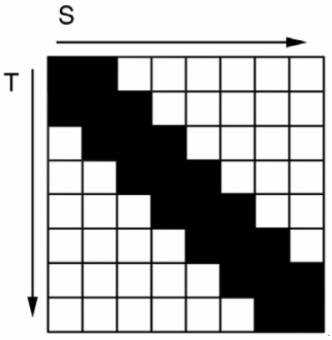
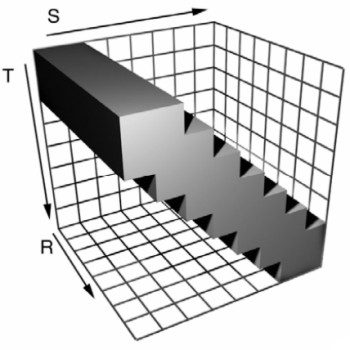
In pratica, considerando un filtro 16x (che si estende, stavolta, in 2 direzioni su 3), i texel coinvolti diventano 512 (16*16*2) per ciascuna direzione. Questo può servire a dare una misura del “peso” delle texture 3D a livello computazionale.
Nel corso degli anni e con l’aumento della potenza di calcolo dei chip, le tecniche di filtraggio hanno subito delle variazioni e, in particolare, il filtraggio delle texture è passato dal semplice point sampling fino all’AF (anisotropic filtering) visto sulle GPU ATi di ultima generazione, che “non dipende dalla direzione di applicazione”.
Chiariamo quest’ultima frase. Poichè, da studi effettuati, è risultato che il sistema occhio-cervello è più sensibile a griglie di tipo ordinato e a direzioni, sul piano X-Y, parallele agli assi ed alle bisettrici dei quadranti (in pratica ad angoli multipli di 45°), inizialmente si è pensato di applicare il filtro solo lungo quelle direzioni, per risparmiare calcoli alla GPU ed aumentare il frame rate.
Inoltre, anche l’applicazione lungo ben precise direzioni non sempre fornisce i medesimi risultati. Infatti, oltre alla direzione, c’è anche la qualità del filtro applicato che può garantire transizioni più o meno brusche (quelle più soft, per quanto detto in precedenza, sono decisamente da preferire). A titolo di esempio, riporto un link di esempio del funzionamento dell’AF per la serie R4x0, R5x0 di ATi e per la serie 7 di nVidia da cui ho estrapolato alcune immagini a titolo di esempio.




Dall’alto in basso, si vede che applicando un AF 1x (quindi con un solo texel lungo ciascuna delle direzioni scelte), gran parte delle informazioni sui colori dei pixel adiacenti a quello selezionato vanno perse e la risultante è una macchia di colori (RGB) a forma di “pseudo quadrifoglio” che cancella tutta l’informazione relativa ai cerchi concentrici più piccoli di quella sorta di bersaglio o di tunnel che si usa come strumento di test.
Con l’applicazione dell’AF 16x ma solo lungo detrminate direzioni (facilmente individuabili), si vede come ‘informazione è mantenuta in misura maggiore lungo le direzioni degli assi e delle bisettrici dei quadranti, ossia dove le figura centrale è più limitata, mentre continua a perdersi dove la figura centrale si estende maggiormente.
A titolo di confronto, si osservino le modalità 16x proposte da ATi e nVidia. Le due figure sono identiche ma, mentre nella prima le transizioni tra colori differenti sono più morbide, nella seconda sono brusche. Diversa ancora è la modalità 16x HQ proposta da ATi (quella di nVidia è identica alla 16x normale di ATi).
In questo caso, il filtro agisce quasi lungo tutte le direzioni. La risultante è una figura che è una via di mezzo tra un cerchio e un quadrato ma l’informazione sulla figura di sfondo è abbastanza ben conservata quasi ovunque. Questa modalità di AF è della stessa qualità di quelle proposte da ATi con la serie RV4xx0 mentre con RV870 si passa all’ultima immagine
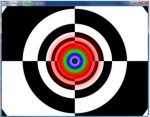
In cui si vede un cerchio pressoché perfetto con transizioni sufficientemente sfumate tra i 3 colori. Quest’ultimo è il tipico esempio di filtro AF applicato in egual misura lungo tutte le direzioni attorno ad una posizione centrale.
Con la generazione DX9 sono state introdotte anche tecniche di filtraggio delle texture trasparenti, su cui non mi dilungherò poiché già trattate nel capitolo dedicato ai sistemi di filtraggio in generale ed all’antialiasing in particolare
Per terminare questa trattazione, spendiamo qualche parola sulle unità che si occupano di elaborare le texture, definite texture unit (TU) o texture management unit (TMU).
Una TU è schematizzabile come un’unità composta da più stadi; in particolare, uno si occupa di fare texture sampling, prendendo il campione e andandone a calcolare parametri come LoD e livello di mipmap della texture da prelevare, uno di calcolare l’indirizzo della locazione di memooria in cui prelevare la texture e un altro di fare le operazioni di texture filtering. Lo schema di massima è quello riportato in figura
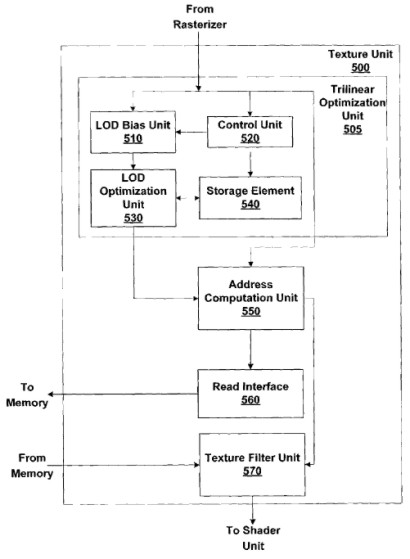
Le operazioni di texture fetching e texture addressing sono svolte da unità di tipo Fixed Function mentre le operazioni di texture filtering, fino alla generazione di chip DX10 era previsto fossero svolte da FF anche se, in realtà, il filtraggio delle texture trasparenti era, già con le DX9, a carico del pixel shader core.
Con la generazione DX11, le operazioni di texture filtering sono interamente svolte dallo shader core per permettere l’implementazione di filtri non lineari, di qualità sicuramente superiore (il point sampling è considerato filtro di ordine 0, mentre tutti gli altri tipi di filtri visti in questo articolo si basano su una o più interpolazioni di tipo lineare).
A valle delle TMU vere e proprie, ci sono delle unità che si occupano delle operazioni di texture blending. Sono disposte in serie, come indicato in figura
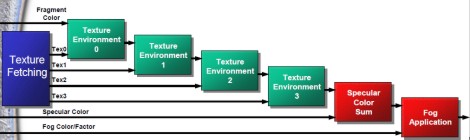
Il primo stadio (indicato con 0) riceve in input la prima del texel da applicare e le informazioni sul colore del pixel e li mescola tra di loro; il secondo (stadio 1) fa, analogamente, un’operazione di blending tra il risultato dello stadio 0 e il secondo texel da applicare e così via. In questo modo è possibile applicare più texel per pixel in un solo ciclo.
Non mi dilungherò sulle architetture di queste unità e sulle loro funzionalità; mi limito a precisare che esistono due tipi di combiner: quelli definiti GENERAL COMBINER che possono svolgere operazioni come MUL, ADD, DOT e MUX sui canali RGB e ALPHA, il cui output è inviato ad un set di registri che costituiscono la base di input per il successivo combiner e da un FINAL COMBINER le cui caratteristiche sono abbastanza simili a quelle dei general combiner (con qualche estensione in più a livello di dati immagazzinabili nei registri interni, il cui elaborato finisce all’interno di registri di output che “scaricano” i dati nel frame buffer.
Chiudo con un’immagine che riporta la parte di pipeline che coinvolge le operazioni di texturing
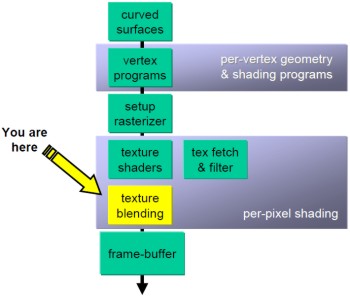
dove, in giallo, è indicato lo stadio relativo ai texture combiner, mentre le TMU sono indicate, immediatamente sopra di esso, come “texture shader” e “texture fetch and filter”.
Con questo, salutiamo le texture ricordando che le operazioni ad esse relative sono tra le più esose in termini di risorse (soprattutto di bandwidth e spazio di occupazione in memoria) e tra quelle con latenze maggiori tra tutte quelle svolte da un chip grafico.
Con le ultime API Microsoft si può arrivare ad applicare fino a 128 texel su ciscun pixel in single pass ed è prevista la possibilità di migliorare la qualità dei filtri e delle stesse texture, introducendo algoritmi non lineari per le funzioni di filtraggio e maggior precisione nel calcolo del LoD.
Insomma, la rincorsa al foto realismo non può prescindere da questi indispensabili strumenti di lavoro che costituiscono un forte stimolo alla creatività dei coder e permettono di vivere esperienze sempre più immersive e coinvolgenti ai giocatori di tutto il mondo.







