
Considering that I have recently written several articles dealing with processor architectures, albeit mainly on a theoretical level, I thought it would be appropriate to continue the trail by starting to deal with a more practical case.
Particularly after the last article on why it is better to focus on CISC again, one might wonder what a practical application of it might be. In this regard, I think a first answer on the subject could be provided by NEx64T, a new architecture that I have been designing over the past few years.
First the heir to the 68000…
As happens with so many things, this architecture was born for fun. I have always been passionate about computer architectures, and I think it is only natural to fantasise about some new one that could do better than the existing ones or even just cover specific areas in a more original, more creative way.
For these reasons I immediately seized the ball when, in the forum of the largest Italian technology portal, a thread was opened in 2010 proposing the design of a new architecture, to which I replied with a project (obviously CISC) inspired by Motorola’s wonderful 68000 family.
The idea behind this architecture was to give a spiritual successor to this glorious family, with the 64-bit extension that it had always lacked. The other was to overcome the problems typical of so many old CISCs, regarding the decoding of variable-length instructions.
In fact, the 68000, but even worse the 68020 (and successors, based on this ISA), suffers from the difficulty of being able to calculate the length of the instruction to be executed, since it is necessary not only to go and check whether it references memory, but also any additional bytes specifying the type of addressing and its parameters, if any.
Further complicating matters is the fact that the MOVE instruction (the most common/used one) allows as many as two memory locations to be referenced (as source and destination), thus doubling the length calculation effort.
With my architecture, the 16- and 32-bit opcodes did not suffer from these problems, and in fact allowed instructions to be easily decoded, while still allowing many of them to reference two memory locations (a general advantage could be gained, once the original problem was solved).
The work done with this architecture reinforced in me the conviction that CISCs was indeed the right way to go, because it had several advantages over RISCs (which I have already discussed at length in previous articles), despite certain problems such as those discussed above.
… with the problems that old CISCs bring with them…
In fact, the biggest problem that CISCs had was that they the first ones: the first processors, at a time when the emphasis was more on substance and engineers designed systems with few resources (transistors) that could meet the computational needs of the time.
No account was taken of the fact that calculating the length of the instructions to be executed could be a tough nut to crack, as the processors only executed one, reading its bytes from memory and decoding what was needed on the fly until the calculations were complete.
But, above all, they travelled at very low frequencies (on the order of a few Mhz) and instructions could take up to several tens of clocks to execute. The last thought, therefore, was that of calculating the length of the instructions and, in general, whether the opcodes were structured in such a way as to facilitate decoding and execution.
All these things turned out to be big headaches when technology pushed the performance accelerator and chips quickly scaled not only on operating frequencies, but also on the number of cycles for instruction execution and, finally, on the number of instructions to be executed per clock cycle.
It is in these, changed, conditions that all the limitations of a design emerged, which, in my humble opinion, is simply and only the result of the times when the architectures of the first CISCs were realised, and not of any CISC processor as such.
The difficulties of the aforementioned 68000 (and successors) are, therefore, related to the fact that this fabulous ISA is a good 44 years old, carrying with it knowledge and engineering typical of that period. Things that, with hindsight, could have been avoided, as demonstrated by my architecture that was inspired by (and for the most part source-compatible with) it.
… particularly the 8086…
All this led me to meditate on the matter and ask myself whether something similar could have been achieved with the vituperative architecture par excellence: x86. I also wondered whether at least for its successor, x64, which was presented in 2000 (and, therefore, with the knowledge by now gained by engineers and the considerable amount of studies accumulated on the subject), it could have been done better.
It has to be said that the undertaking, compared to the 68000, was decidedly more arduous. In fact, in addition to the variable length of the instructions here there are other elements that are particularly complicated to implement and, in particular, the notorious prefixes (of one byte) that are used to change the “behaviour” of the instructions. In particular, they are used (also in combination) for:
- specify a different size for the data to be processed, compared to the default (e.g. from default 32 bit to 16 bit with the size prefix. Or from 64 to 32 bits);
- use a different segment when accessing memory;
- truncate the referenced memory address from 32 to 16 bits or from 64 to 32 bits;
- perform atomic read-modify-write operations;
- perform “repeat” operations on memory blocks (copy, byte search, etc.);
- extend the set of opcodes available to add new instructions (in particular for the SIMD SSE extension and successors. The last two prefixes occupy not one byte, but two);
- extend existing opcodes to access more registers (so that the only 8 available with x86 become 16 with x64);
- extending SIMD opcodes (via the AVX and AVX2 extensions) by making them binary (two source and one destination arguments. Whereas with SSE the destination is also taken as the source) and with the possibility of using 256-bit registers (instead of 128, as with SSE). Or even add new (integer/scalar) binary instructions;
- further extend the SIMD opcodes (via the latest SIMD extension, AVX-512) so as to access more registers (from the 16 of x64 to 32), use 512-bit registers (instead of the 256 of AVX), specify one of the new 8 predication masks, decide whether to merge or zero the vector elements not involved in the operation, copy (broadcast) the element referenced in memory to all elements of the vector, be able to specify the rounding to be used for floating-point instructions, or how to handle any exceptions that might occur during calculations;
- extend in various ways (including a doubling of the registers from 16 to 32) the integer/scalar instructions via the latest APX extension, which we have discussed extensively in a recent series of articles.
There are other prefixes for functionality of lesser or less widespread importance which I will not mention here in order not to lengthen the broth (which is already a lot, as you can see), preferring to concentrate on these which are the best known as well as the most widely used.
In addition to this, x86 suffers from other problems. One that creates quite a headache is that relating to memory addressing modes, which have been extended from the 80386 by changing some particular configurations in the byte (called ModR/M) that is usually used to specify the most important details relating to the specific mode (to which bytes are eventually added to specify the offset to be used/added to the address in memory).
Specifically, these configurations are used to specify an additional byte (following that of ModR/M), called the SIB, which allows further information to be defined regarding the new mode with scaled base and index.
Compared to the 68000 there is a further complication in that some instructions can reference an operand in memory and at the same time also specify an immediate value (the size of which may depend on the size of the data to be manipulated, but… this is not always true: in some cases “short” immediate values of only one byte are used, later extended to the size of the operation).
The Intel manual provides a handy summary showing the format (and thus, the considerable complexity) of any x86/x64 instruction:
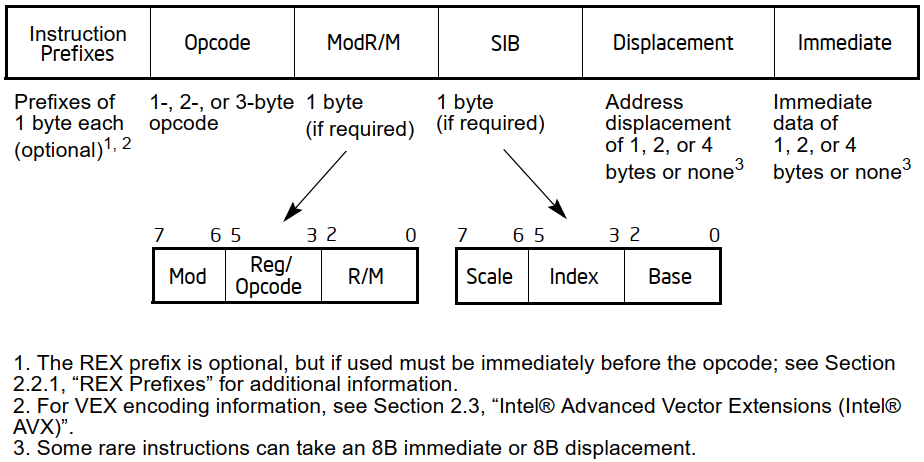
In addition to the prefixes, there are several rarely used instructions, with some of them even particularly complicated, which are part of the so-called “legacy” that this architecture has been carrying around for a long time. Some, fortunately, have been removed from x64 (and opcodes reused, in some cases), but others still remain.
Finally, it must be added that the x86 opcode map is, in turn, complicated to decode. The basic opcode was only one byte up to 80186, because there was enough space to add instructions (from 80286 onwards, this was no longer enough and prefixes were used, as already reported, to open up other spaces for new instruction opcodes).
A little known fact is that the format of these opcodes is a mixture of ordered and random: some instructions are mapped in a certain order, while others are placed completely randomly. In particular, instructions added with new prefixes were mapped almost exclusively in random order (where there was space). Obviously, this further complicates decoding…
… and then the heir to the 8086!
As you can see, it is not an easy thing to be able to decode x86 / x64 instructions, but that did not stop me from providing an answer to both questions posed above anyway: yes, it was possible to do something like that for x86 as well. And again yes: it would have been possible to do better with the introduction of x64.
In fact, I provided the solution the following year (2011) to the design of my 68000 heir, with the first version of my new architecture, which I christened NEx64T. Which comes from a play on words with the terms next, x64, and EM64T (the first name Intel had used for its version of x64).
The initial goal of NEx64T was to provide a “rewrite” of both x86 and x64, with a completely different structure of opcodes that would greatly simplify not only their decoding, but also their implementation (because one can recycle much of the frontend logic for decoding instructions, and almost all of the backend for their execution).
The first version already met these requirements, in that it provided:
- new opcode format, with much simpler decoding (but, most importantly, no prefixes: forget the above diagram!);
- almost orthogonal instructions (particularly for the SIMD unit);
- simplified addressing modes (also and especially in decoding);
- higher code density (but only for the equivalent x64 instructions. Slightly less density was had with those of x86);
- plenty of room to add new instructions (particularly SIMD ones);
- SIMD registers up to 1024 bits;
- possibility of being able to directly specify 64-bit immediate values for several instructions (instead of just the
MOVinstruction); - binary instructions that can specify two arguments as sources (instead of just one and reuse the destination for the other) and unary instructions that can specify one source argument (instead of reusing the destination).
Compatibility with x86 and x64
To this is added a further requirement that I had set myself (and which I also maintained in all other versions of the architecture): perfect compatibility, at source level, with x86 / x64, so as to allow extremely easy porting of existing applications (a trivial recompilation would almost always suffice).
This was not possible with the 68000 heir I had designed (because I intentionally wanted to extend/improve the architecture), but with x86 / x64 I wanted to purposely add this additional constraint to NEx64T, strongly inspired by the work of the 8086 designer, Stephen Morse, who built this new architecture so that software for the earlier 8008, 8080, and 8085 could be easily ported.
In fact, he recognised the very important value that was represented by the existing software, and being able to draw on the library of the earlier processors would have been (and was) a huge added value compared to a totally new ISA that would have required writing special code (which at the time was done very much in assembly language).
Today, the need is much less, because assembly is seldom used and, moreover, a lot of software is portable or has been ported to several architectures, as well as the fact that making backends for compilers (to generate binaries for a special ISA) is easier (and there are more tools) than in the past.
However, the fact that it is 100% source-level compatible with x86 / x64 helps even more in this case and represents, at the same time, a solid response to both AMD’s x64 and Intel’s brand new APX: from x86, the architecture could very well have evolved by getting rid of all the problems exposed above and, thus, make itself much more competitive with the more emblazoned pseudo-RISC architectures (i.e. L/S, as already discussed in several other articles).
Which is very similar to what ARM has done with its new 64-bit architecture, AArch64: it started with an almost entirely new design, taking many elements of the old 32-bit ISA, and redesigning it in a modern key, getting rid of many of the weaknesses and problems that the old one was dragging around. It is not 100% compatible, but it has a good degree of compatibility and it is relatively easy to port old code to it.
This was already the case with the first version of NEx64T, but over time I added several features (even doubled the registers compared to x64, bringing them up to 32: like the very recent APX), new addressing modes, new instructions, completely reorganised the opcodes to make them even easier to decode. Following Intel’s presentation of X86-S (the article is in Italian), I finally further cleaned up and rearranged certain aspects, concluding its evolution.
There is, as can be seen, a lot of meat to present and discuss. In the coming articles I will address individual, precise topics on specific features or parts of the NEx64T, comparing them with the x86 / x64 equivalents when appropriate.
All this is also to show how and why a CISC processor makes perfect sense even today and, indeed, is to be preferred over pseudo-RISC = L/S processors.







