
Considerato che di recente ho scritto parecchi articoli che trattano di architetture dei processori, sebbene principalmente a livello teorico, ho pensato che sarebbe stato il caso di continuare la scia cominciando a trattare un caso più pratico.
In particolare dopo l’ultimo articolo sul perché sia meglio puntare nuovamente sui CISC, ci si potrebbe chiedere quale potrebbe esserne una concreta applicazione. A tal proposito credo che una prima risposta sull’argomento potrebbe essere data da NEx64T, una nuova architettura che ho progettato negli ultimi anni.
Prima l’erede del 68000…
Come capita per tante cose, quest’architettura nasce per gioco. Sono da sempre appassionato di architetture degli elaboratori e penso sia del tutto naturale fantasticarne su qualcuna nuova che possa far meglio di quelle esistenti o anche soltanto coprire specifici settori in maniera più originale, più creativa.
Per questi motivi colsi subito la palla al balzo quando, nel forum del più grande portale tecnologico italiano, nel 2010 fu aperto un thread che proponeva la progettazione di una nuova architettura, al quale risposi con un progetto (ovviamente CISC) ispirato alla meravigliosa famiglia 68000 di Motorola.
L’idea alla base di quest’architettura era di dare un successore spirituale a questa gloriosa famiglia, con l’estensione a 64 bit che le è sempre mancata. L’altra era quella di superare i problemi tipici di tanti vecchi CISC, relativamente alla decodifica delle istruzioni a lunghezza variabile.
Infatti il 68000, ma ancora peggio il 68020 (e successori, basati su quest’ISA), soffre della difficoltà di riuscire a calcolare la lunghezza dell’istruzione da eseguire, in quanto risulta necessario non soltanto andare a controllare se questa referenzi la memoria, ma anche eventuali byte aggiuntivi che specifichino il tipo di indirizzamento e gli eventuali suoi parametri.
A complicare ulteriormente le cose c’è anche il fatto che l’istruzione MOVE (la più comune / utilizzata) consente di referenziare ben due locazioni di memoria (come sorgente e destinazione), raddoppiando, quindi, gli sforzi per il calcolo della lunghezza.
Con la mia architettura gli opcode a 16 e 32 bit non soffrivano di questi problemi e consentivano, infatti, di decodificare in maniera semplice le istruzioni, pur dando la possibilità a molte di esse di referenziare due locazioni di memoria (è stato possibile trarne un generale vantaggio, una volta risolto il problema originale).
Il lavoro fatto con quest’architettura ha rafforzato in me la convinzione che quella dei CISC fosse effettivamente la strada giusta da seguire, perché presentavano diversi vantaggi rispetto ai RISC (di cui ho già ampiamente discusso nei precedenti articoli), nonostante alcune problematiche come quelle qui sopra discusse.
… coi problemi che si portano dietro i vecchi CISC…
Infatti il problema più grosso che hanno avuto i CISC è stato quello di… essere stati i primi: i primi processori, in un’epoca in cui si badava più alla sostanza e gli ingegneri progettavano sistemi con poche risorse (transistor) che potessero soddisfare le esigenze computazionali di allora.
Non si teneva conto del fatto che calcolare la lunghezza delle istruzioni da eseguire potesse essere una brutta gatta da pelare, poiché i processori ne eseguivano una soltanto, leggendo i suoi byte via via dalla memoria e decodificavano al volo ciò che serviva fino al completamento dei calcoli.
Ma, soprattutto, si viaggiava a frequenze molto basse (sull’ordine di pochi Mhz) e le istruzioni potevano richiedere anche parecchie decine di clock per la loro esecuzione. L’ultimo dei pensieri, quindi, era quello del calcolo della lunghezza delle istruzioni e, in generale, se gli opcode fossero strutturati in maniera da facilitarne la decodifica e l’esecuzione.
Tutte cose che si sono poi rivelate delle grosse rogne quando la tecnologia ha spinto sull’acceleratore delle prestazioni e i chip hanno scalato velocemente non soltanto sulle frequenze d’esercizio, ma anche sul numero di cicli per l’esecuzione delle istruzioni e, infine, sul numero di istruzioni da eseguire per ciclo di clock.
E’ in queste, mutate, condizioni che sono emersi tutti i limiti di una progettazione che, a mio modesto avviso, è semplicemente e soltanto frutto dei tempi in cui le architetture dei primi CISC sono state realizzate, e non di un qualunque processore CISC in quanto tale.
Le difficoltà del già citato 68000 (e successori) sono, quindi, relative al fatto che questa favolosa ISA risalga a ben 44 anni fa, portandosi dietro conoscenze e ingegnerizzazioni tipiche di quel periodo. Cose che, col senno di poi, si sarebbero potete evitare, come dimostrato dalla mia architettura che era stata ispirata (e per buona parte compatibile a livello di sorgenti).
… in particolare l’8086…
Tutto ciò mi ha portato a meditare sulla questione e a chiedermi se qualcosa di simile si sarebbe potuto realizzare anche con l’architettura vituperata per eccellenza: x86. Mi sono anche chiesto se almeno per il suo successore, x64, presentato nel 2000 (e, quindi, con la consapevolezza ormai maturata dagli ingegneri e la notevole mole di studi accumulatasi sull’argomento), si sarebbe potuto far meglio.
C’è da dire che l’impresa, rispetto al 68000, risultava decisamente più ardua. Infatti oltre alla lunghezza variabile delle istruzioni qui ci sono altri elementi particolarmente complicati da implementare e, in particolare, i famigerati prefissi (di un byte) che sono usati per cambiare il “comportamento” delle istruzioni. In particolare, sono utilizzati (anche in combinazione tra loro) per:
- specificare una dimensione diversa per i dati da elaborare, rispetto a quella di default (es.: da default a 32 bit si passa a 16 bit col prefisso di dimensione. Oppure da 64 a 32 bit);
- utilizzare un segmento diverso quando si accede alla memoria;
- troncare da 32 a 16 bit o da 64 a 32 bit l’indirizzo in memoria referenziato;
- eseguire operazioni atomiche di read-modify-write;
- eseguire operazioni “con ripetizione” su blocchi di memoria (copia, ricerca di byte, ecc.);
- estendere l’insieme di opcode disponibili per aggiungere nuove istruzioni (in particolare per l’estensione SIMD SSE e successori. Gli ultimi due prefissi non occupano un byte, ma ben due);
- estendere gli opcode esistenti per poter accedere a più registri (in questo modo i soli 8 disponibili con x86 diventano 16 con x64);
- estendere gli opcode SIMD (tramite le estensioni AVX e AVX2) facendoli diventare binari (due argomenti sorgente e uno destinazione. Mentre con SSE la destinazione viene presa anche come sorgente) e con la possibilità di utilizzare registri a 256 bit (anziché a 128, come per le SSE). Oppure aggiungere anche nuove istruzioni (intere / scalari) binarie;
- estendere ulteriormente gli opcode SIMD (tramite l’ultima estensione SIMD, AVX-512) in modo da accedere a più registri (dai 16 di x64 si passa a 32), utilizzare registri a 512 bit (anziché i 256 di AVX), specificare una delle nuove 8 maschere di predicazione, decidere se eseguire il merge o azzerare gli elementi del vettore non coinvolti nell’operazione, copiare (broadcast) l’elemento referenziato in memoria in tutti gli elementi del vettore, poter specificare l’arrotondamento da utilizzare per le istruzioni in virgola mobile, oppure come gestire le eventuali eccezioni che si dovessero verificare durante i calcoli;
- estendere in vari modi (incluso un raddoppio dei registri, che passano da 16 a 32) le istruzioni intere / scalari tramite l’ultima estensione APX, di cui abbiamo ampiamente parlato in una recente serie di articoli.
Esistono altri prefissi per funzionalità di minore o meno diffusa importanza che non riporto qui per non allungare il brodo (che è già tanto, come si può vedere), preferendo concentrarmi su questi che sono i più noti nonché utilizzati.
Oltre a ciò x86 soffre di altre problematiche. Una che crea abbastanza grattacapi è quella relativa alle modalità d’indirizzamento della memoria, che sono state estese dall’80386 cambiando alcune particolari configurazioni nel byte (chiamato ModR/M) che usualmente viene impiegato per specificare i dettagli più importanti relativi alla specifica modalità (a cui si aggiungono eventualmente dei byte per specificare l’offset da utilizzare / aggiungere all’indirizzo in memoria).
Nello specifico, queste configurazioni sono utilizzate per specificare un byte addizionale (che segue quello di ModR/M), chiamato SIB, il quale consente di definire ulteriori informazioni riguardo alla nuova modalità con base e indice scalato.
Rispetto al 68000 c’è un’ulteriore complicazione rappresentata dal fatto che alcune istruzioni possono referenziare un operando in memoria e al contempo specificare anche un valore immediato (la cui dimensione può dipendere da quella dei dati da manipolare, ma… non è sempre vero: in alcuni casi vengono impiegati valori immediati “corti”, di un solo byte, estesi poi alla dimensione dell’operazione).
Il manuale di Intel fornisce un comodo riassunto che mostra il formato (e, quindi, la notevole complessità) di una qualunque istruzione x86/x64:
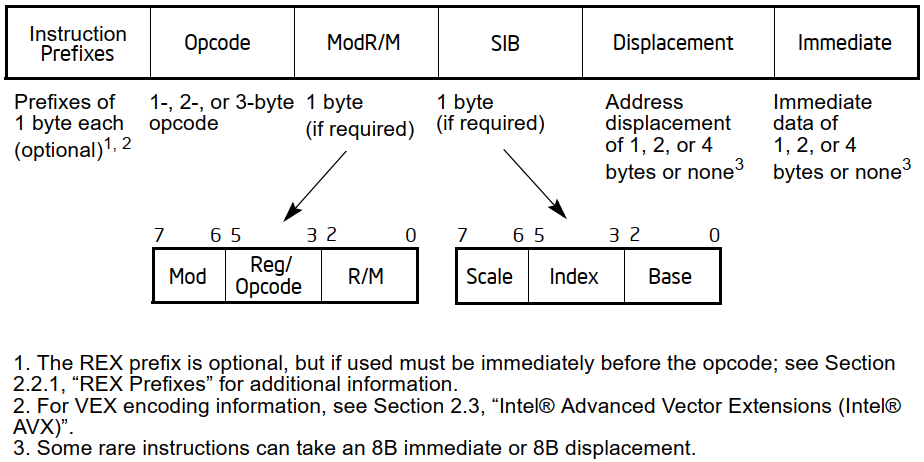
Ai prefissi si aggiungono, poi, diverse istruzioni raramente utilizzate, con alcune di esse anche particolarmente complicate, le quali fanno parte del cosiddetto “legacy” che quest’architettura si porta dietro da parecchio tempo. Alcune, per fortuna, sono state rimosse da x64 (e gli opcode riutilizzati, in alcuni casi), ma altre rimangono ancora.
Infine, bisogna aggiungere che la mappa degli opcode x86 è, a sua volta, complicata da decodificare. L’opcode base era di un solo byte fino all’80186, perché c’era abbastanza spazio per aggiungere istruzioni (a partire dall’80286 non è più bastato e sono stati utilizzati dei prefissi, come già riportato, per aprire altri spazi per gli opcode di nuove istruzioni).
Una cosa poco nota è che il formato di questi opcode sia un misto fra ordinato e casuale: alcune istruzioni sono mappate secondo un certo ordine, mentre altre sono state piazzate in maniera del tutto casuale. In particolare, le istruzioni aggiunte coi nuovi prefissi sono state mappate quasi esclusivamente in ordine casuale (dove c’era spazio). Ovviamente ciò ne complica ulteriormente la decodifica…
… e poi l’erede dell’8086!
Come si può vedere, non è cosa facile poter decodificare le istruzioni x86 / x64, ma ciò non mi ha impedito di fornire in ogni caso una risposta a entrambe le questioni poste in precedenza: sì, era possibile fare qualcosa del genere anche per x86. E ancora sì: sarebbe stato possibile fare di meglio con l’introduzione di x64.
Infatti la soluzione l’ho fornita l’anno successivo (il 2011) al progetto del mio erede dei 68000, con la prima versione della mia nuova architettura, che ho battezzato NEx64T. La quale deriva da un gioco di parole coi termini next, x64, ed EM64T (il primo nome che Intel aveva utilizzato per la sua versione di x64).
L’obiettivo che si prefiggeva inizialmente NEx64T era quello di fornire una “riscrittura” sia di x86 sia di x64, con una struttura completamente diversa degli opcode che consentisse di semplificarne notevolmente non solo la decodifica, ma anche l’implementazione (perché si può riciclare buona parte della logica del frontend per la decodifica delle istruzioni, e quasi tutto il backend per la loro esecuzione).
La prima versione rispondeva già ai suddetti requisiti, in quanto forniva:
- nuovo formato degli opcode nuovo, con decodifica molto più semplice (ma, soprattutto, niente prefissi: dimenticate il diagramma qui sopra!);
- istruzioni quasi tutte ortogonali (in particolare per l’unità SIMD);
- modalità d’indirizzamento semplificate (anche e soprattutto nella decodifica);
- maggior densità di codice (ma solo per le equivalenti istruzioni di x64. Una leggera minor densità si aveva con quelle di x86);
- parecchio spazio per aggiungere nuove istruzioni (in particolare quelle SIMD);
- registri SIMD fino a 1024 bit;
- possibilità di poter specificare direttamente valori immediati a 64 bit per diverse istruzioni (anziché soltanto per l’istruzione
MOV); - istruzioni binarie che possono specificare due argomenti come sorgenti (anziché soltanto uno e riutilizzare la destinazione per l’altro) e unarie che possono specificare un argomento sorgente (anziché riutilizzare la destinazione).
La compatibilità con x86 e x64
A ciò si aggiunge un ulteriore requisito che m’ero prefisso (e che ho mantenuto anche in tutte le altre versioni dell’architettura): la perfetta compatibilità, a livello di sorgenti, con x86 / x64, in modo da consentire un port estremamente facilitato delle applicazioni esistenti (basterebbe quasi sempre una banale ricompilazione).
Questo non è stato possibile con l’erede del 68000 che avevo progettato (perché ho intenzionalmente voluto estendere / migliorare l’architettura), ma con x86 / x64 ho voluto aggiungere appositamente quest’ulteriore vincolo a NEx64T, ispirato fortemente dal lavoro del progettista dell’8086, Stephen Morse, il quale ha realizzato questa nuova architettura in modo che fosse possibile tradurre facilmente il software per i precedenti 8008, 8080, e 8085.
Infatti ha riconosciuto il valore molto importante che era rappresentato dal software esistente, e poter attingere alla libreria dei processori precedenti sarebbe stato (ed è stato) un enorme valore aggiunto rispetto a un’ISA totalmente nuova che avrebbe richiesto la scrittura di codice apposito (che all’epoca si realizzava molto in linguaggio assembly).
Oggi l’esigenza è molto meno sentita, perché raramente si usa l’assembly e, inoltre, parecchio software è portabile o è stato portato su parecchie architetture, oltre al fatto che realizzare backend per i compilatori (per generare binari per un’apposita ISA) è più semplice (e ci sono più strumenti) rispetto al passato.
Comunque iI fatto di essere 100% compatibile al livello di sorgente con x86 / x64 aiuta ancora di più in questo caso e rappresenta, al contempo, una solida risposta sia all’x64 di AMD sia alla nuovissima APX di Intel: da x86 l’architettura avrebbe potuto benissimo evolversi togliendo di mezzo tutte le problematiche esposte in precedenza e, quindi, rendersi molto più competitiva con le più blasonate architetture pseudo-RISC (ossia L/S, come già discusso in diversi altri articoli).
Che poi è molto simile a quanto ARM ha fatto con la sua nuova architettura a 64 bit, AArch64: è partita con un progetto quasi del tutto nuovo, prendendo molti elementi della vecchia ISA a 32 bit, e ridisegnando il tutto in chiave moderna, togliendo di mezzo molti punti deboli e problematiche che si trascinava quella vecchia. Non è 100% compatibile, ma ha un buon grado di compatibilità ed è relativamente semplice portarvi il vecchio codice.
Questo già soltanto considerando la prima versione di NEx64T, ma col tempo ho aggiunto diverse funzionalità (anche raddoppiato i registri rispetto a x64, portandoli a 32: come la recentissima APX), nuove modalità d’indirizzamento, nuove istruzioni, completamente riorganizzato gli opcode in modo da renderne ancora più facile la decodifica. A seguito della presentazione di X86-S da parte di Intel ho, infine, ulteriormente ripulito e risistemato alcuni aspetti, concludendo la sua evoluzione.
C’è, come si può vedere, parecchia carne al fuoco da presentare e discutere. Nei prossimi articoli affronterò dei singoli, precisi temi su specifiche funzionalità o parti di NEx64T, confrontandole con le equivalenti di x86 / x64 quando dovesse essere il caso.
Il tutto per mostrare anche come e perché un processore CISC abbia perfettamente senso anche oggi e che, anzi, sia da preferire rispetto agli pseudo-RISC = processori L/S.







