Dopo una lunghissima pausa (causa tapeout) eccoci di nuovo qui con una nuova puntata sull’architettura dei processori superscalari. Nell’ultimo articolo abbiamo dato uno sguardo a cosa significa fare il fetch delle istruzioni in un processore superscalare e a quali sono i principali limiti. Abbiamo visto come il disallineamento del gruppo di fetch rispetto alla cache line riduca la banda effettiva verso la memoria, e alcune strategie per combattere questo problema.
Rimane ora investigare l’altro grande problema, uno dei singoli problemi peggiori dal punto di vista delle prestazioni: le modifiche al flusso del programma causate dai branch (salti condizionati). In questo articolo vedremo perchè la branch prediction è una parte fondamentale di un processore superscalare, quali sono i componenti chiave e come questi si innestano nell’architettura del processore. Nei prossimi articoli descriverò alcune delle tecniche usate per costruire i predittori.
Per capire meglio perchè i branch sono così deleteri per le macchine superscalari, consideriamo questo “problema giocattolo” (cioè estremamente semplificato per mettere in evidenza questo specifico problema e permettere di ottenere informazioni utili con pochi calcoli a mente):
- consideriamo un programma con un branch ogni 5 istruzioni (20% branch)
- non consideriamo data hazards nè structural hazards
- non consideriamo i cache miss
- confrontiamo una pipeline a 5 stadi base (rigida, scalare, senza forwarding paths) con quello di un ipotetico processore superscalare con 5 pipeline parallele (supponiamo che tutti gli stadi abbiano larghezza 5) e con 20 stadi
- supponiamo che i branch vengano risolti nello stadio di esecuzione, il terzo su 5 nella pipeline semplice e il dodicesimo su 20 nella pipeline superscalare (per simmetria: 3:5 = 12:20)
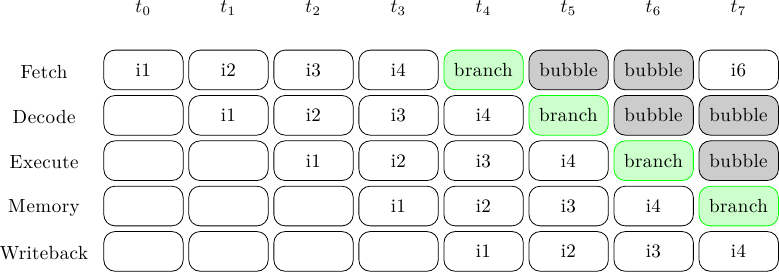
La pipeline semplice si comporterà così:
dove il tempo scorre in orizzontale, e per ogni colpo di clock viene mostrato lo stato della pipeline. Le prime 5 istruzioni riempiono l’intera pipeline in 5 colpi di clock, poi due bolle devono essere inserite mentre si aspetta che il branch arrivi all’unità di esecuzione; a questo punto il Program Counter viene settato al valore corretto, e il programma può riprendere. In totale servono 7 cicli di clock (5 utili più 2 bolle) per eseguire il blocco di 5 istruzioni, cioè un IPC (Instruction Per Clock) di 5 / 7 = .71
La pipeline superscalare invece si comporterà così:
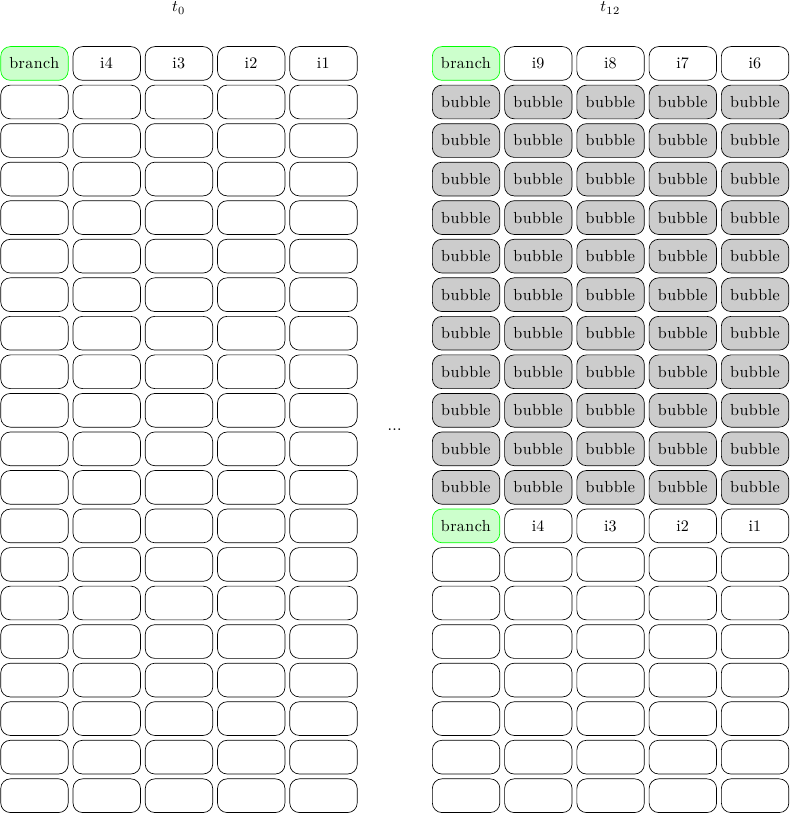
dove ho mostrato solo il primo e il tredicesimo colpo di clock. Ora tutte e 5 le istruzioni possono viaggiare in parallelo, perchè stiamo trascurando tutti gli hazard che non siano quelli di controllo. Purtroppo, mentre questo “pacchetto” di istruzioni si fa strada nella pipeline, sta lasciando il deserto dietro di sè: la pipeline è completamente vuota perchè il processore non sa qual è la prossima istruzione. Al dodicesimo ciclo di clock, con 11 stadi vuoti dietro di sè, il processore risolve finalmente il branch, reindirizza il Program Counter, e cinque nuove istruzioni vengono caricate. La media è 5 istruzioni in 12 cicli di clock, cioè un IPC di 5 / 12 = .42
In questo schema idealizzato il processore superscalare ha prestazioni molto più basse della pipeline semplice, ma usa molta più area, più potenza, ed è molto più difficile da progettare: un fallimento su tutta la linea! Addirittura, l’IPC è .42 mentre il picco teorico sarebbe 5 (5 istruzioni parallele per ciclo di clock), cioè più del 90% delle prestazioni potenziali viene buttato via. Intuitivamente, il problema è che un processore superscalare ha molti più “slot” (istruzioni eseguibili) che rimangono vuoti per ciclo di clock, oltre ad avere in media più stadi di pipeline.
Il risultato di questo problema è che non possiamo assolutamente pensare di costruire un processore superscalare senza risolvere questo problema all’apparenza insolubile: eseguire istruzioni che seguono un branch prima ancora di averlo valutato (anzi, prima ancora di averlo decodificato!).
Branch prediction
La soluzione a questo problema è, almeno di nome, nota a tutti (almeno su queste pagine :) e si chiama branch prediction. E’ uno degli esempi più importanti dell’uso delle tecniche di speculazione all’interno del processore: speculiamo che il flusso del programma segua un certo percorso, e facciamo il fetch delle istruzioni da quel percorso prima di sapere se è quello giusto. Ovviamente, la speculazione non deve avere alcun impatto sulla correttezza del programma, ma solo sulle prestazioni. I branch vanno comunque eseguiti, e il loro risultato confrontato con la nostra ipotesi: se avevamo speculato correttamente il branch diventa una NOP dal punto di vista del programma (era già stato eseguito correttamente); altrimenti, è necessario tornare sui propri passi, cancellare tutte le istruzioni eseguite speculativamente, ritornare al Program Counter del salto, e riprendere ad eseguire il programma dal percorso giusto (misprediction recovery).
Il meccanismo può funzionare solo se i branch hanno un comportamento ripetitivo e quindi prevedibile. Fortunatamente è così per la maggior parte dei programmi, il che permette ai migliori predittori disponibili oggi di “indovinare” la direzione di salto con precisione incredibile (anche superiore al 98% in certi casi).
Prima di vedere le tecniche che sono state sviluppate per risolvere il problema è necessario osservare più da vicino da dove vengono i branch e quali strutture hardware sono necessarie alla loro esecuzione.
Grafi di flusso e branch
Un programma può essere decomposto in basic blocks, cioè blocchi di istruzioni che vengono eseguite una dopo l’altra senza interferenze da parte di branch o jump. I programmi possono essere descritti come grafi orientati dove i basic block sono i nodi, e gli archi definiscono le possibili transizioni tra i blocchi. Quando da un blocco si può uscire in due diverse direzioni (cioè da esso partono due archi) siamo in presenza di un branch, altrimenti si tratta di un jump, ad esempio:
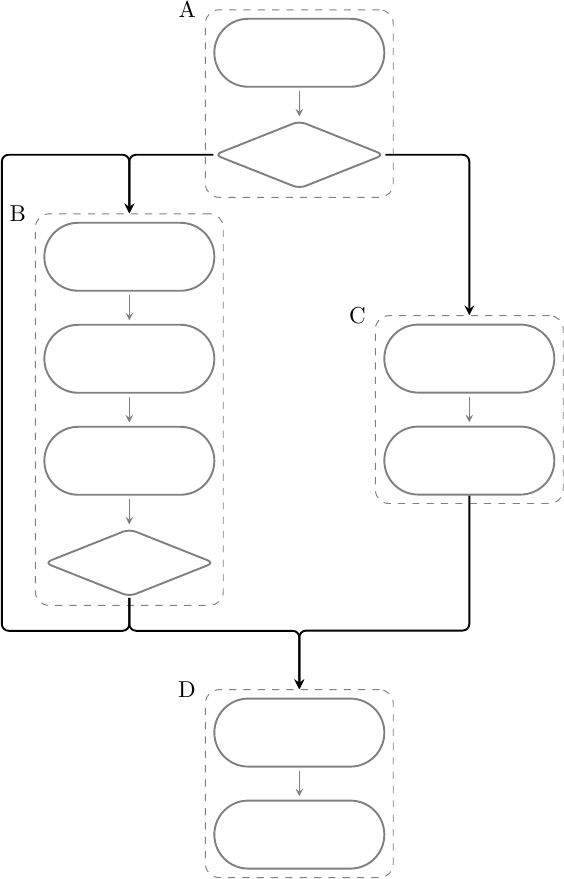
In questo caso verrà eseguito il blocco A, quindi B o C, e infine D; B è un loop e può essere eseguito una o più volte. Per disporre il programma in memoria è necessario “linearizzare” le istruzioni, cioè disporre i blocchi uno dopo l’altro sequenzialmente in un qualche ordine, ad esempio:
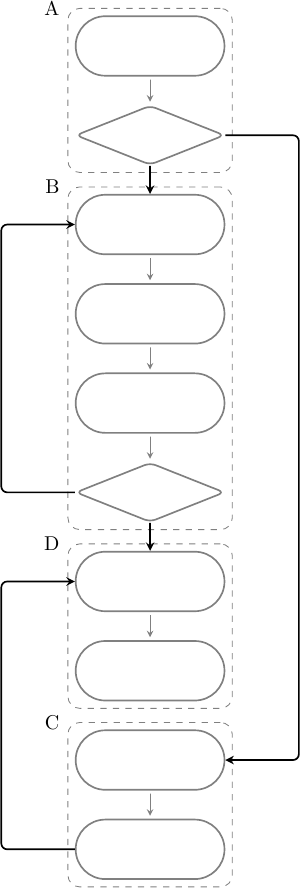
I branch diventeranno quindi un’alternativa tra eseguire l’istruzione immediatamente seguente, oppure saltare ad un diverso indirizzo di memoria e riprendere da lì. L’esecuzione di un salto è quindi composta da due fasi: la risoluzione della condizione (cioè se effettuare il salto o meno) e la generazione del bersaglio di salto. La risoluzione della condizione può avvenire in diversi punti della pipeline, ad esempio:
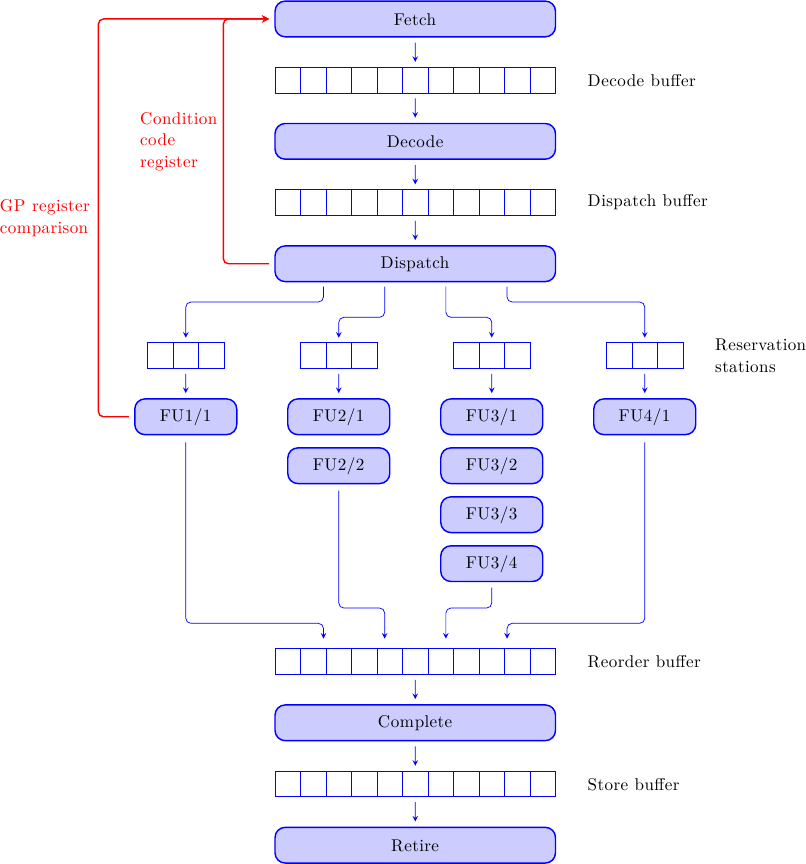
Nel caso il salto dipenda da dei registri Condition Code (come ad esempio i flag bits) allora la condizione potrebbe essere risolta indicativamente intorno allo stadio di Dispatch. Se invece è richiesto un calcolo sui registri, allora sarà necessario eseguire questo calcolo nello stadio di esecuzione.
Anche la generazione del bersaglio può avvenire in punti diversi della pipeline, ad esempio:
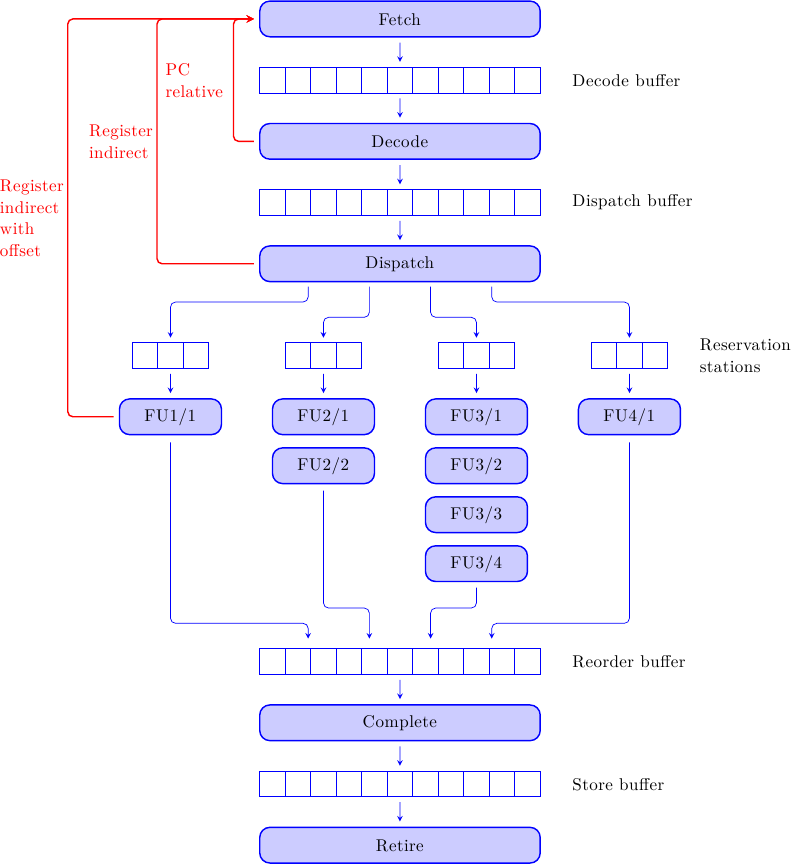
Se il salto è relativo al Program Counter attuale possiamo calcolare il bersaglio subito dopo la decodifica dell’istruzione di branch, sommando il campo Immediate (per usare la terminologia MIPS) al PC corrente. Se il salto è invece al valore contenuto in un registro possiamo avere il besaglio appena il valore è disponibile, di nuovo intorno allo stadio di Dispatch. Se invece il bersaglio va calcolato con un’operazione più complessa, dovremo aspettare di eseguire il branch nella sua pipeline dedicata.
Branch predictor come black-box, predizioni multiple e misprediction recovery
Ciò detto, e considerando che non vogliamo aspettare la risoluzione dei salti per procedere col programma, che faccia dovrebbe avere il nostro predittore? Dovrà essere qualcosa del genere:
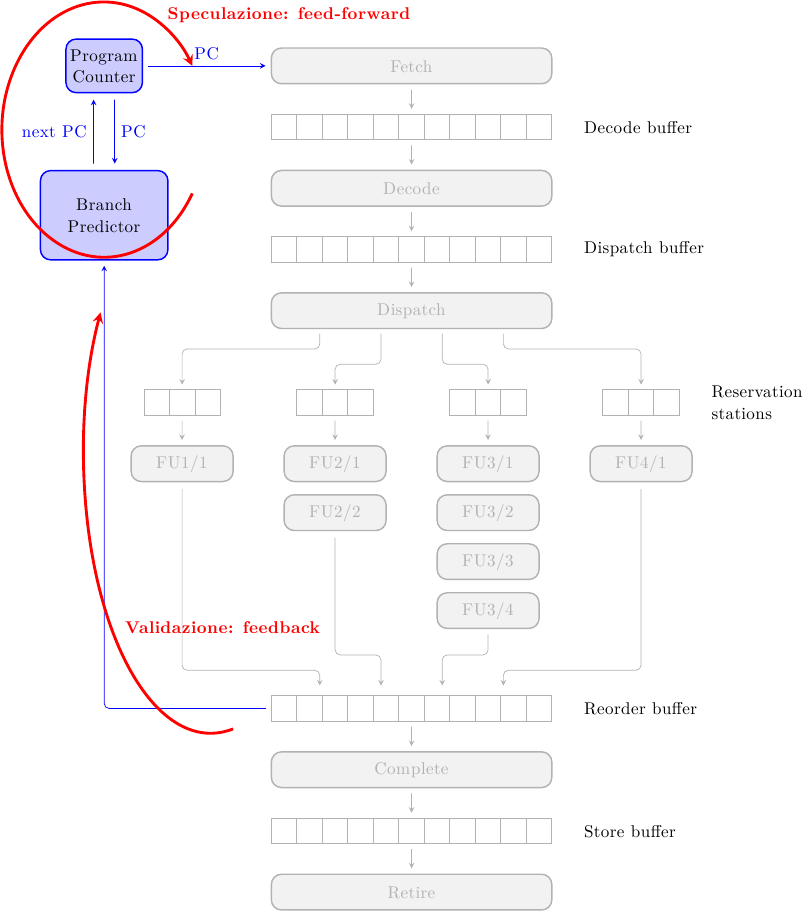
Ad ogni ciclo di clock abbiamo bisogno di sapere dove prelevare le istruzioni; da questo punto di vista il predittore non è altro che una funzione che fornisce il prossimo Program Counter a partire da quello corrente.
In termini di teoria del controllo, questa funzione è in sostanza un sistema feed-forward: il predittore fornisce il prossimo PC senza sapere come il PC corrente eseguirà, ma solo in funzione di come ha eseguito nel passato, cioè dello stato corrente del predittore. Questo permette al predittore di essere molto veloce, ma non completamente accurato. Il predittore stesso, invece, è inserito in un anello di feedback: una volta che il risultato del salto è noto, il predittore viene aggiornato con le ultime informazioni, in modo da essere più accurato la prossima volta. Naturalmente il risultato del salto viene anche usato per la misprediction recovery, se la predizione si rivelasse errata.
Questo è sempre il caso nelle tecniche che usano speculazione: richiedono un meccanismo di validazione della speculazione, per garantire il corretto funzionamento del sistema. Le due componenti descritte prima possono quindi anche essere viste come due meccanismi interagenti: il primo meccanismo, nel front-end della pipeline, fornisce la speculazione, mentre il secondo, nel back-end, effettua la validazione e la correzione degli errori.
A questo punto una domanda potrebbe sorgere spontanea: cosa succede se, mentre stiamo eseguendo delle istruzioni in modo speculativo a seguito di un salto, incontriamo un altro salto? La risposta è ovvia: effettuiamo un’altra speculazione. È possibile avere più salti in attesa di risoluzione e istruzioni in esecuzione speculativa che dipendono da uno o più di questi salti. Per fare ordine, e recuperare dai possibili errori, serve mantenere:
- una tag diversa per ogni blocco base: ogni istruzione in esecuzione speculativa sarà accompagnata dalla tag del blocco base a cui appartiene
- un buffer con gli indirizzi dei salti che stiamo eseguendo speculativamente: è necessario nel caso una predizione di salto si rivelasse errata e si fosse costretti a tornare indietro e ripetere il salto nella direzione giusta
Per fare un esempio, supponiamo di aver incontrato 3 salti e di star eseguendo speculativamente le istruzioni che li seguono; supponiamo anche che il predittore abbia generato le predizioni {preso, non-preso, preso} per i 3 salti. Lo stato delle istruzioni nella pipeline può essere schematizzato così:
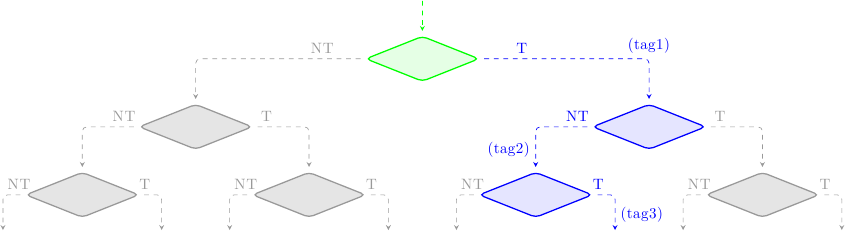
dove ho indicato in verde i blocchi validati (cioè corretti), in blu i blocchi in esecuzione speculativa, in rosso i blocchi speculati erroneamente, e in grigio i blocchi scartati dal predittore. Ad ogni rombo corrisponde un salto. Le istruzioni prima del primo salto non stanno eseguendo speculativamente, e quindi non hanno alcuna tag. Le istruzioni che seguono il primo salto (o meglio, che seguono l’indirizzo bersaglio del primo salto, visto che la predizione è “salto preso”) hanno la tag 1, e così via.
Ad un certo punto i branch eseguono e il meccanismo di validazione entra in scena. Supponiamo che il primo salto fosse stato predetto correttamente, mentre il secondo no; la situazione ora sarà:
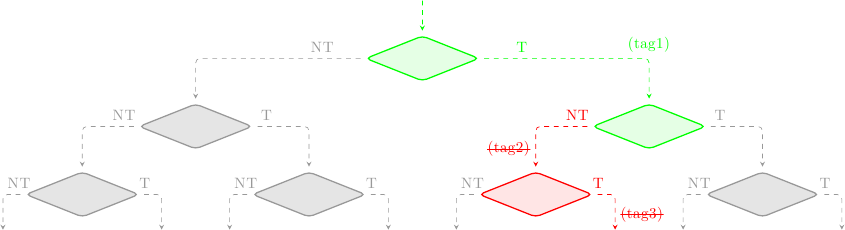
Tutte le istruzioni con la tag 1 sono state validate, e la loro tag rimossa: non stanno più eseguendo speculativamente, e potranno aggionare i registri architetturali quando saranno ritirate. Tutte le istruzioni con la tag 2 devono essere cancellate, e così quelle con tag 3, visto che dipendono dal secondo salto (errato).
Un modo per farlo sarebbe quello di andare a controllare tutti gli stadi di tutte le pipeline, il reorder buffer, le reservation station, eccetera, cercare le tag incriminate, e cancellare le istruzioni errate. Questo può essere costoso in termini di logica necessaria.
Un altro modo può essere quello di sfruttare un meccanismo già esistente per la gestione precisa delle eccezioni (rapidamente accennata qui). In pratica, è sufficiente fare così:
- andare nel reorder buffer, che contiene una entry per ogni istruzione in-flight nel processore
- cercare le tag incriminate e marcare quelle istruzioni come “invalide”
Le istruzioni errate continueranno ad eseguire, attraversando le pipeline e arrivando al reorder buffer. Al momento del ritiro, serve un pezzo di logica che controlli il bit di validità: le istruzioni invalide verranno semplicemente scartate senza avere alcun impatto sui registri architetturali. Dal punto di vista del software quelle istruzioni non sono mai state eseguite. Questo permette di semplificare molto la logica di recovery, al prezzo di eseguire istruzioni che sappiamo essere errate (spreco di energia).
Conclusioni e… quiz!
In questa prima parte abbiamo visto perchè la predizione dei salti è assolutamente necessaria per garantire buone prestazioni ai processori superscalari, e abbiamo anche visto come i pezzi chiave del meccanismo di predizione si innestano nell’architettura del processore. Nei prossimi articoli descriverò alcune delle tecniche usate per generare le predizioni, con esempi tratti da processori commerciali.
E ora, per i pochi coraggiosi che sono riusciti ad arrivare fino alla fine… quiz! Consideriamo un pezzetto di codice molto semplice e comune, come un if che protegge la dereferenziazione di un puntatore:
int a; int* p = NULL; ... if(p != NULL) a = *p
Quiz: in quale problema potrebbe incorrere questo innocentissimo codice, una volta che al nostro processore aggiungiamo la branch prediction?







