Nel precedente articolo abbiamo visto quali sono i requisiti dei diversi segmenti di mercato di una CPU (mobile, desktop, server), quali devono a tutti i costi essere soddisfatti e su quali si può scendere a compromessi. Inoltre, abbiamo visto come questi si intreccino con le necessità dei chip maker di bilanciare costi, prestazioni e complessità di ingegnerizzazione.
Facendo sempre riferimento allo sviluppo di Nehalem, oggi vedremo come tutti questi fattori hanno influenzato le principali scelte microarchitetturali.
Scelta della pipeline
Una delle prime scelte fu la pipeline da usare. Tre le opzioni disponibili:
- la pipeline del Pentium 4 Northwood, riveduta e corretta
- la pipeline del P6, largamente rimaneggiata e migliorata
- una pipeline nuova di zecca su cui uno dei centri di ricerca intel stava lavorando
Il design team in Oregon aveva buona esperienza delle prime due pipeline. Inoltre, la prima e la terza avevano prestazioni più alte della vecchia pipeline del P6. Tuttavia, altre considerazioni ebbero la meglio e spinsero a scegliere proprio quest’ultima (migliorata, stile Core 2 duo):
- consumi più bassi delle altre (fondamentale se si vogliono mettere tanti core in un solo package)
- area più piccola (idem come sopra)
- minor sforzo ingegneristico (che permise di ridurre i costi, centrare la finestra temporale di consegna del prodotto, e ottimizzare al massimo il chip)
- maggiore continuità software (le ottimizzazioni del compilatore rimangono simili a quelle per i processori precedenti: questo significa meno lavoro da fare sul compilatore, e i clienti non devono ricompilare tutto il codice per ottimizzarlo per la nuova architettura)
La stima degli ingegneri Intel è che con questa pipeline si sia pagato un 10-20% di penalità in termini di prestazioni. Come si può vedere, le prestazioni assolute NON sono state il motore primo delle scelte architetturali.
Cores vs vectors vs SMT
Dopo la pipeline, la decisione più importante da prendere riguardò il numero e la struttura dei core. Le principali aggiunte al core base che Intel valutò furono i vettori (stile AVX) e l’aggiunta dello SMT (simultaneous multi-threading, come nel Pentium 4, migliorato e ottimizzato). Entrambe le tecnologie impongono compromessi sia sul lato hardware che sul lato software:
- i vettori sono estremamente efficienti sia dal punto di vista dell’area che dell’energia… a patto di usarli! altrimenti sono solo uno spreco di entrambe le risorse. Sono semplici da realizzare in hardware, ma usarli significa riscrivere e ricompilare il codice, per far esplicito uso di queste istruzioni (o quanto meno ricompilare, a patto di avere compilatori capaci di autovettorizzare il codice là dove possibile)
- anche il simultaneous multi-threading è una tecnica efficiente: con un ~5% di incremento in area e potenza, si può ottenere anche un 20% di prestazioni in più, in alcune applicazioni. Dal punto di vista software, SMT è trasparente: il processore mostra il doppio di core “logici”, e un’applicazione già multi-threaded può avvantaggiarsene senza dover essere riscritta. Dal punto di vista hardware, però, lo SMT aggiunge un’enorme complessità alla validazione e al testing (in poche parole: l’idea è semplice, ma è difficilissimo farla funzionare in pratica)
Ciò detto, le alternative valutate furono tre: nella stessa area si potevano avere 2 core “grossi” (core base con migliorie + SMT + vettori), 3 “medi” (core base con migliorie + SMT) o 4 “piccoli” (core base).
Dati i requisiti illustrati in precedenza, Intel decise di implementare l’ultima soluzione: core piccoli consumano meno (importante per laptop) e ce ne si può mettere di più nello stesso package (importante per i server). Vettori ed SMT sono tecnologie allettanti, ma all’epoca Intel le riteneva premature per buona parte degli utenti (si ricordi che queste decisioni venivano prese nel 2003-04, quando i primi processori dual core non erano ancora arrivati sul mercato). Intel ritenne opportuno svilupparle in un secondo tempo: infatti, oggi assistiamo al ritorno di SMT e l’anno prossimo dovremmo avere i vettori AVX.
Avere core piccoli ha altri vantaggi importanti: in primis, il lavoro di ingegnerizzazione è più basso; permette una granularità più fine (si possono produrre chip con 1, 2, 4, 6 e 8 core nello stesso package); e infine, è possibile controllare meglio la potenza, spegnendo un numero maggiore di risorse non utilizzate.
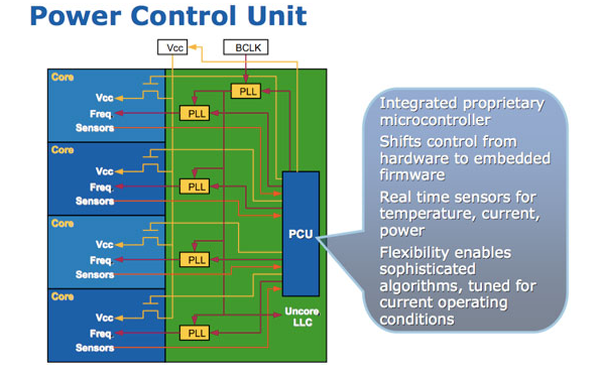
Power control
I primi processori dual-core avevano una frequenza più bassa dei corrispettivi single-core. Il problema principale era di dissipazione termica (come discusso in un precedente articolo): raddoppiare i core significa raddoppiare i consumi, e per tenerli sotto controllo era necessario ridurre la frequenza. Esistono diversi modi per ridurre i consumi di un core inutilizzato, ognuno con un diverso tempo necessario a riportare il core a piena capacità di funzionamento. Alcuni di essi sono:
- fermare la logica ma lasciare il clock acceso: poco risparmio, ma velocissimo da riattivare (può essere anche un ciclo di clock)
- spegnere i clock: buon risparmio, meno veloce da riattivare
- togliere l’alimentazione: risparmio massimo (è l’unico modo per eliminare il leakage), ma il più lento da riattivare (per Nehalem dovrebbe aggirarsi tra 50 e 100 microsecondi)
Poter togliere l’alimentazione ai core inutilizzati permette di ridurre a zero il loro consumo, e dirottare tutta la capacità termica del dissipatore ai soli core attivi (stando attenti agli hot spot! bisogna stare sotto le tolleranze sia in energia che in temperatura): in questo modo è possibile incrementare la frequenza dei core attivi, e incrementare le performance del codice single-threaded (il cosiddetto “Turbo Mode”). Un sofisticato microcontrollore posto nell’ “uncore” (la zona del processore non occupata dai core) tiene sotto controllo temperatura e potenza di tutto il chip, riceve istruzioni dal sistema operativo, e dirige le operazioni di spegnimento dei core e regolazione di tensione e frequenza. Un microcontrollore permette di avere grande flessibilità: gli algoritmi di regolazione non devono essere codificati in hardware al momento della progettazione, ma possono essere modificati e ricaricati dopo che il processore è uscito di fabbrica (e, volendo, anche dopo essere stato immesso sul mercato). Si tratta di un piccolo “processore dentro il processore”.
“Togliere l’alimentazione” sembra una cosa innocua: dopotutto, nella nostra esperienza quotidiana, è sufficiente un interruttore. In un circuito integrato, però, l’interruttore non è che un altro transistor MOS, come per la normale logica. Un MOS, però, che quando è acceso deve far passare i 20+ Ampere necessari al funzionamento del core con una caduta di tensione trascurabile rispetto al ~1 Volt di alimentazione! Per riuscire a ottenere questo risultato, gli ingegneri di processo di Intel hanno dovuto creare un nuovo layer metallico dedicato, incredibilmente spesso per un chip (per avere bassissima resistenza), e i progettisti circuitali hanno dovuto realizzare dei MOS di “power gating” eccezionalmente larghi (per lo stesso motivo). L’intera operazione ha richiesto quindi uno sforzo progettuale significativo, che ha coinvolto diverse divisioni.
Core “lego” e 3 livelli di cache
Fino a questo momento abbiamo sempre dato per scontato che per fare un processore multicore basti progettare un core singolo e poi fare “copy and paste” più volte sul silicio. La cosa non è purtroppo così semplice: i core devono essere progettati fin dall’inizio in modo tale da poter diventare “mattoncini lego”, pena il crollo delle prestazioni per scarsezza di alcune risorse critiche.
Una di queste risorse è la cache: se mantenessimo i due livelli come nei processori single-core, con una L1 per core e la L2 condivisa tra tutti i core, all’aumentare dei core la L2 non riuscirebbe a rispondere a tutte le richieste di accesso in un tempo accettabile. Per risolvere questo problema, la soluzione adottata da Nehalem (e non solo: anche Phenom usa una struttura simile) è di aggiungere un terzo livello: ogni core ha le sue L1 e L2, e la L3 è condivisa tra tutti i core. La L2 per core è sufficientemente grande da “filtrare” molte delle richieste e servirle localmente, in modo da ridurre il traffico verso la L3 e rendere possibile integrare più core nel chip senza esaurire la banda verso la cache.
Conclusioni
In questi articoli abbiamo visto come i produttori di processori (e non solo loro) non puntino a produre i chip più veloci in assoluto, ma debbano tenere conto di una moltitudine di fattori, alcuni tecnologici e altri di mercato.
Uno dei fattori tecnologici più limitanti è la “disponibilità di manodopera”: suona strano, viste le migliaia di persone (per parecchi anni di fila) che queste compagnie possono mettere in campo per progettare un singolo chip, ma la complessità di questi dispositivi è ormai tale che decine di milioni di ore-uomo di lavoro sono viste come “troppo poco tempo” dai capi progetto, che si lamentano di non avere “un migliaio di ingegneri in più” per poter inserire qualche altra feature interessante nei loro chip.







