1 luglio 2009: chi di voi non ha mai sentito parlare di memoria virtuale, paginazione, file di swap, virtualizzazione delle risorse, ecc… scagli la prima pietra!
Sono tutte cose con cui abbiamo a che fare, utilizzamo e diamo anche per assodate da parecchio tempo. Difficile immaginare oggi un mondo senza questi utilissimi strumenti. Eppure parecchi anni fa chi smanettava coi primi computer “domestici” non conosceva nemmeno la loro esistenza, essendo relegati a sistemi parecchio costosi (mainframe, minicomputer, workstation).
Ovviamente, col passare degli anni e la continua diffusione dell’informatica, approdarono nel mercato consumer anche CPU che erano dotate di simili caratteristiche.
A metà degli anni ’80 il boom di Commodore Amiga, Atari ST e Apple Macintosh portarono alla ribalta il glorioso 68000 della Motorola (che non offriva nulla del genere), e iniziarono a proliferare anche le cosidette “schede acceleratrici”, le più economiche delle quali permettevano di montare il meno famoso fratello maggiore, il 68010…

Nato nello stesso anno dell’80286 di Intel (il 1982), ma costituito dalla metà dei transistor (e, quindi, molto più economico), questo microprocessore portava innanzitutto una dovuta correzione a un grossolano errore di progettazione commesso da Motorola col primo esemplare di questa fortunata famiglia: l’introduzione dell’istruzione MOVE CCR, facendo al contempo diventare privilegiata la già esistente MOVE SR.
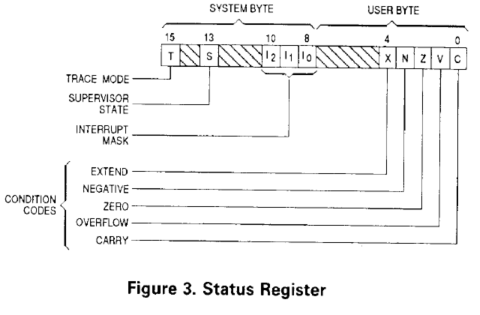
Perché tutto questo? E perché è così grave questa mancanza? SR è il registro di stato della CPU, e contiene sia i codici di condizione (riporto, segno, ecc.) sia vari altri flag che rappresentano informazioni sullo stato privilegiato del processore (modalità utente/supervisore, maschera degli interrupt e abilitazione del tracing delle istruzioni).
Col 68000 era possibile modificare come si vuole questo registro e, quindi, un’applicazione aveva piena facoltà di fare il bello e il cattivo tempo sull’intero sistema (sarebbe stato sufficiente abilitare la modalità supervisore per ottenere il controllo su tutto). Questo impediva, di fatto, la realizzazione di sistemi operativi “protetti”, dove soltanto il kernel (che gira in modalità supervisore) poteva disporre l’ambiente per l’esecuzione delle applicazioni utente.
D’altra parte quella di poter accedere ai flag dei codici di condizioni era ed è un’esigenza abbastanza comune, per cui mettendo nell’ISA l’istruzione MOVE CCR, che agisce soltanto sul byte che li contiene (tralasciando il byte con le informazioni privilegiate), si salvavano, sì, capra e cavoli, ma a un prezzo piuttosto salato: l’incompatibilità con le applicazioni scritte per il 68000, che giustamente facevano uso della MOVE SR (unica istruzione disponibile per loro).
Commodore risolse il problema con l’AmigaOS mettendo a disposizione nella ROM la routine GetCC che eseguiva una MOVE SR o una MOVE CCR a seconda che fosse stato rilevato un 68000 o un processore superiore (68010 incluso). Ciò nonostante tante applicazioni e (soprattutto) giochi per Amiga non funzionarono con processori diversi dal primo, perché i programmatori erano troppo poco inclini a seguire le rigorose direttive della casa madre sullo sviluppo di software per questa piattaforma (problema comune anche oggi, purtroppo).
Per realizzare la completa virtualizzazione delle risorse del microprocessore, furono aggiunte altre istruzioni. MOVE VBR che consentiva di spostare ovunque nella memoria la tabella dei vettori delle interruzioni ed eccezioni (costituita da 256 elementi, anche se in realtà ne veniva usati di meno), MOVEC per leggere e scrivere i registri di controllo dei codici funzione, e infine MOVES per spostare dati fra spazi d’indirizzamento diversi.
I codici funzione sono utilizzati dalla CPU per segnalare in maniera precisa il motivo per cui sta accedendo alla memoria (sia in lettura che in scrittura). Sono previsti, infatti, appositi valori per indicare l’accesso al codice (fetch dell’istruzione) o ai dati, e se la modalità è quella utente o supervisore.
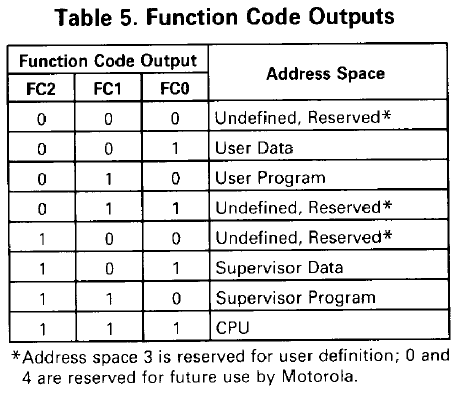
In questo modo le periferiche possono regolarsi servendo in maniera opportuna la richiesta. A prima vista sembrerebbe una caratteristica inutile, ma sfruttandola opportunamente è possibile isolare del tutto i dati utente da quelli supervisore. Inoltre si potrebbe anche dividere la memoria allocata per il codice da quella per i dati. Combinando entrambe le cose si arriverebbe anche a poter indirizzare fino a 64MB di memoria (16 + 16 MB per codice e dati utente, e altrettanti per quelli supervisore).
Col 68000 però c’era poca flessibilità per quanto riguarda i codici funzione, perché erano fissi e predeterminati nella CPU, e pertanto non era possibile effettuare, ad esempio, copie di dati fra aree di memoria utente e supervisore (tranne se coincidevano, come veniva fatto), caratteristica questa necessaria per un kernel.
Il 68010 introduce 2 nuovi registri (SFC e DFC, che definisco i codici funzione sorgente e destinazione) e le suddette istruzioni MOVEC e MOVES, risolvendo in maniera elegante il problema. Con la prima istruzione è possibile memorizzare appositi valori in SFC e DFC, mentre la seconda li utilizza spedendoli alle periferiche esterne rispettivamente quando legge il dato, e quando lo scrive.
Da tutto ciò rimane, però, fuori la cosa più importante: la virtualizzazione della memoria. Infatti col 68000 non era possibile implementare questa funzionalità, poiché il microprocessore, in caso di errore di bus (indirizzo non presente) o d’indirizzo (non valido), scatena un’eccezione, memorizzando però nello stack poche informazioni per il suo recupero.

Il 68010, invece, memorizza molte più informazioni (fra cui il suo intero stato interno), permettendo quindi di poter decidere in maniera precisa cosa fare a seguito dell’eccezione, e in che modo riprendere l’esecuzione dell’istruzione, arrivando quindi a emulare praticamente qualunque caratteristica “fisica” di un sistema agli “occhi” dell’applicazione che sta girando.
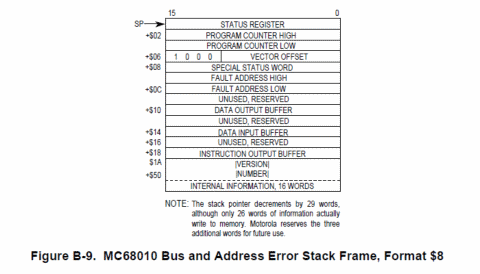
Inutile dire che, utilizzando uno stack frame diverso (viene chiamato così l’insieme delle informazioni di stato memorizzate nello stack a seguito di interruzioni o eccezioni), il 68010 presentava un ulteriore elemento di incompatibilità col 68000, creando ancora una volta problemi alle applicazioni “poco ortodosse”…
Di questa CPU ne venne realizzata anche una versione con bus indirizzi esterno a 30 bit (68000 e 68010 hanno, invece, un bus indirizzi esterno a 24 bit e, quindi, sono limitati come indirizzamento della memoria a 16MB), il 68012, capace pertanto di arrivare fino a 1GB di spazio d’indirizzamento, ma che non ebbe successo.
I vantaggi, però, non finivano qui: lato applicativo fu introdotta una particolare modalità “loop”, in grado di accelerare notevolmente l’esecuzione di precisi pattern di istruzioni facenti uso dell’istruzione di loop DBcc (utilissima e usatissima, che prevede il decremento di un registro e il salto se questo non è zero, oppure se la condizione non è soddisfatta).
Questo microprocessore, infatti, era dotato di una memoria interna di 3 word (6 byte), utilizzata per il prefetch delle istruzioni. Nel caso in cui la logica di prefetch incontrava un’istruzione che occupava una sola word, e la successiva era una DBcc il cui indirizzo puntava alla prima, veniva attivata questa modalità che non richiedeva il continuo caricamento degli opcode delle due istruzioni, ma la memoria era impegnata esclusivamente a trasferire i dati veri e propri.
Le stime parlavano di un buon 10% circa di guadagno fra 68010 e 68000 a parità di clock e ciò, assieme alle migliorie apportate nell’ambito della virtualizzazione, fece avere a questo microprocessore una discreta accoglienza nelle workstation economiche, ma scarsa nei computer “domestici” (principalmente a causa delle citate incompatibilità).
P.S. Ringrazio Fabio Mecchia per aver gentilmente messo a disposizione una foto della CPU.







