
Basta soltanto il nome: 8086. Simbolo, nel bene e nel male, di una famiglia di microprocessori che ha fatto LA storia, essendo diventata l’ISA più diffusa e dominando da anni incontrastata il mercato dei computer.
Come sappiamo un po’ tutti, la sua fortuna è legata a doppio filo ai PC, e in particolare al Personal Computer col quale IBM decise di entrare in un mercato diverso da quello che era stato fino ad allora oggetto delle sue attenzioni (cioé i mainframe), facendo diventare la CPU di Intel il cuore del sistema.
Come capita tante volte, nel mercato non s’impone il prodotto migliore, ma quello che si riesce a vendere meglio. Non fa eccezione il PC e il processore che si porta dietro, che presenta delle soluzioni architetturali che fanno un po’ storcere il naso agli appassionati.
Alcuni ricorderanno il motto tristemente noto e attribuito erroneamente a Bill Gates (ma pronunciato da un ingegnere IBM): “640K should be enough for everyone“. Tradotto: “640KB dovrebbero bastare per chiunque”. Si riferiva al massimo quantitativo di memoria libera a disposizione delle applicazioni (sistema operativo incluso) che offriva il PC.
Il limite teorico era rappresentato dai 20 bit d’indirizzamento dell’8086, che permettevano di accedere a 1MB (1024KB, cioé 2^20 byte) di memoria in totale. Purtroppo a causa di scelte poco felici da parte degli ingegneri di IBM, buona parte di questo spazio d’indirizzamento fu riservato alle periferiche e al BIOS, riducendone la quantità utilizzabile ai famigerati 640KB (in realtà si trovò poi il modo di sfruttare parte dei 384KB riservati, ma rimaneva una magra consolazione).
Il limite dei 1024KB restava però a carico del microprocessore, e veniva fuori anch’esso da una scelta che, anziché poco felice, personalmente definirei perversa, per il meccanismo che vi sta dietro. Probabilmente il limite dei 20 bit d’indirizzamento nasceva dall’esigenza di ridurre i costi di packaging del chip; all’epoca erano di moda package con 40 pin, per cui usarne 20 soltanto per generare l’indirizzo ne lasciava pochi per i segnali di controllo.
Risultava impossibile, infatti, pensare di allocarne altri 16 per i dati: avrebbe richiesto un package con molti più pin e, quindi, più costoso. Ciò comportò la necessità dell’uso del multiplexing per poter trasferire dati diversi sugli stessi pin, cambiandone di volta in volta utilizzo in base ai segnali di controllo. Infatti i primi 16 dei pin riservati alla generazione dell’indirizzo finirono per essere impiegati anche per trasferire i dati.
Giudicare simile scelte come “perversione” sarebbe, però, eccessivo. Il multiplexing era una comoda ed economica pratica abbastanza diffusa, e quando lo spazio è tiranno la differenza fra la soluzione elegante e quella di compromesso può essere la stessa che c’è fra una soluzione che arriva oppure no sul mercato.
Dunque rimane il limite dei 20 pin che portano al già citato MB di memoria indirizzabile. 20 bit, però, è un numero “strano” per un processore a 16 bit, che è dotato, appunto, di registri a 16 bit. In che modo, quindi, viene calcolato l’indirizzo a 20 bit? Lo schema seguente mostra l’operazione eseguita dall’8086:
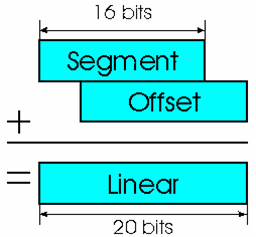 La soluzione fu rappresentata dall’utilizzo di speciali registri chiamati segmenti che portano in sé quei 4 bit necessari per arrivare ai fatidici 20 a disposizione.
La soluzione fu rappresentata dall’utilizzo di speciali registri chiamati segmenti che portano in sé quei 4 bit necessari per arrivare ai fatidici 20 a disposizione.
I registri di segmento erano ovviamente a 16 bit, e in numero di quattro per la precisione: CS per indirizzare il codice (assieme al registro IP “puntava” all’istruzione correntemente eseguita), SS per lo stack (col registro SP “puntava” alla locazione di memoria a 16 bit libera per memorizzare un valore, mentre col registro BP era possibile accedere ai dati memorizzati nello stack), DS per i dati (accessibili in vari modi; in particolare coi registri indice BX, SI e DI) e infine ES quale segmento “extra” per accedere ad altri dati (alcune istruzioni, inoltre, utilizzavano implicitamente ES e DI).
Un esempio chiarirà in che modo saltano fuori i 4 bit per comporre l’indirizzo a 20 bit. Supponiamo di voler accedere alla locazione di memoria che ha indirizzo (a 20 bit ovviamente) 0xB8000 in formato esadecimale (qualcuno magari ricorderà che rappresenta l’inizio della memoria della gloriosa scheda video CGA). Possiamo caricare in DS il valore 0xB800 e in BX il valore 0x0000.
Per arrivare all’indirizzo voluto l’8086 procede in questo: moltiplica DS per 16 (che, in gergo informatico, equivale a shiftare DS a sinistra di 4 posti; ed equivale anche ad aggiungere uno 0 a destra a un numero esadecimale) e gli somma il valore del registro BX.
Nello specifico, quindi, avremo: 0xB800 * 16 + 0x0000 = 0xB8000 + 0x0000 = 0xB8000, che è l’indirizzo desiderato. Il valore a 16 bit prelevato dal registro BX per formare l’indirizzo viene chiamato offset, per cui un indirizzo viene definito sempre dall’accoppiata segmento + offset, e in genere rappresentato in questo modo: B800:0000 (coi due punti a separare i due valori).
Ma quella di porre DS = 0xB800 e BX = 0x0000 è soltanto una scelta e non un obbligo. E’ possibile, infatti, trovare altre coppie di valori che generano lo stesso indirizzo. Ad esempio B000:8000 rappresenta esattamente la stessa cosa: 0xB000 * 16 + 0x8000 = 0xB0000 + 0x8000 = 0xB8000 (il tutto sempre in esadecimale). E così via, le combinazioni possibili non si ottengono soltanto giocando con le cifre B e 8.
Quindi possiamo dire che una coppia segmento:offset non rappresenta in maniera univoca un indirizzo. Ciò porta a risultati alquanto bizzarri. Dalla formuletta di cui sopra si potrebbe, infatti, pensare che almeno l’indirizzo 0x00000 sia, matematica alla mano, univoco in quanto l’unica coppia che può generarlo è 0000:0000.
In realtà anche FFFF:0010 genera 0x00000, e il perché è presto detto: 0xFFFF * 16 + 0x0010 = 0xFFFF0 + 0x0010 = 0x100000 che… è un indirizzo a 21 bit! Poiché l’8086 è in grado di riportare soltanto i primi 20 bit, il 21esimo viene eliminato dal calcolo, e il risultato finale diventa, quindi, 0x00000.
Quello che sembra un comportamento poco sensato e ancor meno utile, in realtà venne sfruttato dal BIOS per poter accedere alle prime locazioni di memoria del PC (dov’erano memorizzate importante informazioni sul sistema). Il BIOS dei primi PC risiedeva negli ultimi 8KB di memoria, all’indirizzo 0xFE000. Quindi il registro CS poteva esser caricato col valore 0xFE00, e per accedere all’indirizzo 0x00000 (e superiori) sarebbe stato sufficiente usare come offset 0x2000 (e superiori).
E’ abbastanza perverso? Per chi ha usato microprocessori come il Motorola 68000, col suo indirizzamento perfettamente lineare, lo era sicuramente; nonché fonte di disperazione.
Personalmente continuo a non capire perché Intel non abbia preferito una soluzione molto più semplice, cioé quella di utilizzare i segmenti per memorizzare i 16 bit più significativi dell’indirizzo finale che sarebbe stato a 32 bit (con tutti i vantaggi che si possono immaginare: ben 4GB di memoria indirizzabili sulla carta).
Vista la limitazione dei 20 pin per l’indirizzo, sarebbe bastato “tagliare via” i 12 bit più alti, senza precludere un aumento dello spazio indirizzabile con future versioni con più pin del chip. Ma non solo: non sarebbe stato neppure necessario far uso di un circuito sommatore per effettuare il calcolo dell’indirizzo precedentemente illustrato… risparmiando dei (preziosi, all’epoca) transistor!
Chissà cosa sarà passato nella mente degli ingegneri di Intel che si sono inventati questo meccanismo così contorto. Rimarrà sicuramente un’altra delle misteriose “stravaganze” dell’informatica…







