Nel precedente articolo abbiamo visto le basi della tecnica di pipelining. Adesso è ora di fare sul serio, e dare uno sguardo alle tecniche architetturali e circuitali usate per costruire una “vera” pipeline.
Dipendenze, pipeline hazards, interlock e stalli
Nella maggior parte dei casi, una istruzione “dipende” da una o più istruzioni precedenti, nel senso che queste istruzioni precedenti devono aver completato (cioè eseguito e aggiornato i registri e/o la memoria) prima che la nuova istruzione possa eseguire. Di quali dipendenze bisogna preoccuparsi, allora, quando si costruisce una pipeline? Ce ne sono di tre tipi: dipendenze dati (tra registri o tra locazioni di memoria), dipendenze di controllo e dipendenze strutturali.
Le dipendenze dati si dividono a loro volta in 3 categorie:
- RAW (Read After Write, anche detta True Dependence): un’istruzione deve attendere fino a che tutti i suoi operandi non sono stati prodotti; cioè, è possibile “leggere (gli operandi) solo dopo che essi sono stati scritti (prodotti)”
- WAR (Write After Read, anche detta Anti-Dependence): un’istruzione che scrive su un registro deve essere certa che nessun’altra istruzione debba ancora leggere il vecchio valore di quel registro; cioè, è possibile “scrivere (il nuovo valore) solo dopo che tutti hanno letto (il vecchio valore)”
- WAW (Write After Write, anche detta Output Dependence): un’istruzione che scrive su un registro non deve cancellare il valore già scritto da un’istruzione successiva; cioè, puoi “scrivere (il nuovo valore) solo dopo che è stato scritto (il precedente valore)”.
Le dipendenze di controllo sono concettualmente più semplici: i salti condizionati (“branch”) modificano il flusso di istruzioni, e quindi le istruzioni che seguono un salto dipendono dall’esito della condizione di salto. (I più smaliziati potrebbero considerare le dipendenze di controllo come dipendenze dati sul valore del Program Counter).
Le dipendenze strutturali, invece, si verificano quando diverse istruzioni vogliono usare lo stesso hardware per le loro operazioni: c’è una contesa sulle risorse della macchina, e una delle istruzioni dovrà “cedere il passo” all’altra.
Come risolvere, allora, queste dipendenze e assicurare la corretta esecuzione del programma? In teoria ci sono due metodi, uno software e uno hardware:
- metodo statico (software): il compilatore, quando produce il programma, si assicura che non esistano dipendenze. Questo può essere fatto se il compilatore conosce la struttura della pipeline, e può quindi calcolare il numero corretto di NOP da inserire per eliminare tutte le dipendenze di dati e di controlli. Il vantaggio è che l’hardware è semplificato al massimo; lo svantaggio è che un programma compilato per una pipeline non girerà su un’altra, perchè basta uno stadio di differenza a cambiare il computo delle NOP e rendere il programma incompatibile
- metodo dinamico (hardware): tutte le dipendenze sono controllate e rispettate a runtime dal processore stesso, che si occupa di inserire “bolle” nella pipeline (del tutto equivalenti alle NOP del compilatore). Il vantaggio è che viene garantita la compatibilità del codice compilato in precedenza (diversi processori avranno diversi meccanismi di controllo, ma tutto questo avviene “sotto l’ISA” e quindi è completamente trasparente al programma). Lo svantaggio è che serve hardware (che occupa area e consuma energia) per far rispettare le dipendenze
Dato che la retrocompatibilità del codice è molto importante, il controllo delle dipendenze in hardware è la tecnica più diffusa. Questa tecnica è chiamata pipeline interlock: ovvero la pipeline stessa “blocca” alcuni suoi stadi, quando necessario, per far rispettare le dipendenze.
Prendiamo ad esempio queste que righe di pseudo-assembly:
i1: r = a + b i2: s = 2 * r
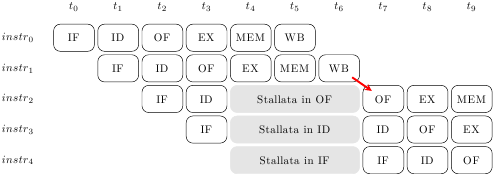
La seconda istruzione non può leggere l’operando r (nello stadio OF) fino a che la prima istruzione non l’ha prodotto e scritto nel register file (nello stadio WB). La situazione è quindi quella mostrata in figura:
L’istruzione 2 vorrebbe caricare il suo operando al tempo 4, ma deve rimanere bloccata nello stadio di Operand Fetch perchè esso non è disponibile. Al tempo 6 l’istruzione 1 scrive il suo risultato nel register file e finalmente, al tempo 7, l’istruzione 2 può caricare l’operando, per poi andare in esecuzione al tempo 8.
Naturalmente, se un’istruzione si blocca anche tutto quello che segue deve bloccarsi: la pipeline è “rigida”, non permette alle istruzioni di scavalcarsi l’un l’altra. E dato che non possono esistere due istruzioni nello stesso stadio, se l’istruzione 2 si blocca in Operand Fetch allora l’istruzione 3 si blocca in Instruction Decode, la 4 si blocca al Fetch, e nessuna altra istruzione può entrare nel processore. Quando, al tempo 7, l’istruzione 2 si sblocca, anche tutte le altre si sbloccano, e il processore riprende a marciare.
Ma come fare a capire se c’è una dipendenza, e per quanti cicli di clock è necessario stallare il processore? Per una pipeline in-order esiste un sistema semplice ed intuitivo: è sufficiente considerare le distanze relative dei “produttori” di dati rispetto ai loro “consumatori”.
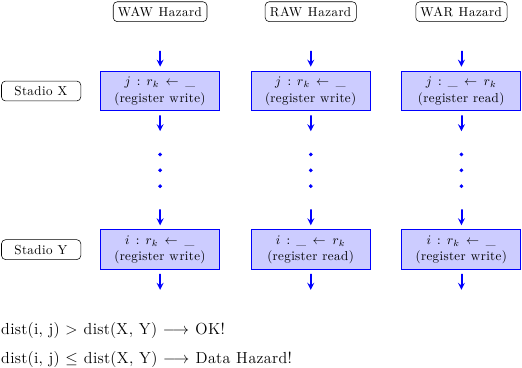
Siano i e j due istruzioni, con j che dipende da i. Allora, è sufficiente confrontare la distanza tra gli stadi di pipeline tra cui si sviluppa la dipendenza con la distanza tra le istruzioni nel codice assembly. Se la distanza tra le istruzioni è maggiore della distanza fra gli stadi, allora non c’è pericolo: le istruzioni sono sufficientemente lontane e non ci sarà nessun hazard. Se invece è minore o uguale, le istruzioni sono troppo vicine, e la pipeline dovrà stallare l’istruzione j fino a che la distanza non è rispettata. Il numero di stalli da inserire è uguale alla differenza tra le distanze (più uno).
Un chiaro esempio viene dalla precedente immagine della pipeline stallata: l’istruzione 2 deve leggere da registro (stadio OF) un dato prodotto dall’istruzione 1 (e scritto nel registro allo stadio WB). La distanza tra le istruzioni è 2 – 1 = 1; la distanza fra gli stadi WB e OF è 3. Dato che 3 > 1, bisogna stallare la pipeline; inoltre, 3 – 1 + 1 = 3, quindi bisogna stallarla per 3 colpi di clock, che è esattamente quanto si vede in figura (e che è intuitivamente corretto).
Lo stesso ragionamento può essere applicato per le dipendenze di controllo: in questo caso, il “produttore” è l’istruzione di branch, e il “consumatore” è il Program Counter, che viene usato dallo stadio di Fetch (IF). Le dipendenze di controllo sono in genere le peggiori, perchè la distanza fra il produttore e il consumatore è massima, e quindi è massimo il numero di stalli che la pipeline è costretta a subire. Questo è un problema che, come vedremo in articoli successivi, è particolarmente grave per i processori superscalari, e richiede tutta una serie di tecniche complesse per essere mitigato.
In una pipeline reale, dunque, è necessaria della logica ausiliaria che controlla, ciclo per ciclo, tutte le possibili dipendenze, per prendere provvedimenti. Con centinaia di diverse istruzioni, e parecchi stadi (in genere, tra i 5 e i 20), ci possono essere migliaia di diverse dipendenze da controllare constantemente: la logica può essere complessa. Si prenda questo esempio:
i1: r1 <= __ i2: r2 <= r1 - 1 i3: r3 <= r1 & r2 i4: if(r3) goto end i5: store r1 end:
Questo pseudo-assembly potrebbe essere parte di una funzione che controlla se il valore in r1 e’ una potenza di due. L’istruzione i2 dipende da i1, i3 dipende da i1 e i2, i4 è un branch che dipende da i3, i5 dipende da i4 per il controllo e da i3 per i dati… perfino per poche istruzioni bloccare gli stadi giusti al momento giusto può essere alquanto laborioso!
Forwarding
Quanto detto finora assicura la correttezza dell’esecuzione dei programmi, ma è eccessivamente conservativo. Consideriamo l’esempio precedente, con i2 che ha una dipendenza RAW da i1. Sicuramente, se aspettiamo che i1 aggiorni il register file prima di permettere a i2 di leggerlo, il processore si comporterà correttamente. Ma l’intuizione ci dice che, in realtà, i1 produce il suo risultato nello stadio di esecuzione EX, e che i2 consuma quel valore nello stesso stadio EX. Secondo la formula precedente, dato che la distanza fra gli stadi coinvolti è zero, non dovrebbe esserci alcuno stallo!
Questa intuizione ci permette di sviluppare il concetto di forwarding path: invece di aspettare che i valori prodotti vengano scritti nel register file, essi vengono immediatamente inoltrati agli stadi di pipeline che ne hanno bisogno. Questo è possibile perchè questi valori, benchè non ancora disponibili nel register file, sono già presenti da qualche parte, in uno dei registri interni della macchina. Non sono ancora visibili al programmatore (non sono, cioè, nei registri architetturali), ma sono visibili al processore stesso.
I forwarding paths, quindi, sono dei bus che collegano ogni stadio produttore con ogni stadio consumatore, pilotati da della logica di controllo che decide quali valori debbano essere inoltrati a quali stadi. La figura mostra alcuni dei possibili forwarding paths, insieme alle combinazioni che li fanno attivare:
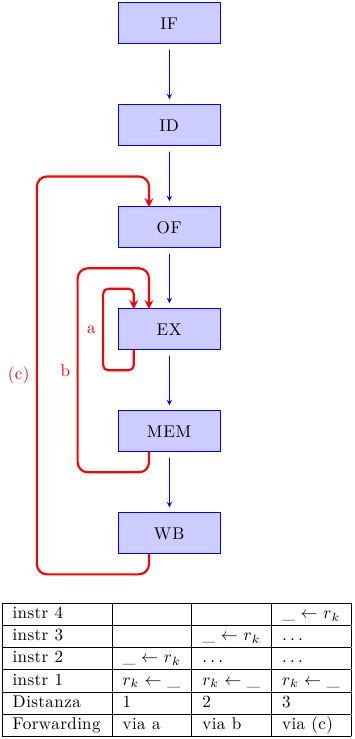
Nella prima colonna, l’istruzione i2 dipende dall’istruzione i1, sono subito una dietro l’altra, e vengono entrambe eseguite nello stadio EX. Senza forwarding, i2 dovrebbe aspettare in OF per 3 cicli (come visto prima); ora, invece, può attraversare tranquillamente OF (ed uscirne con l’operando sbagliato!) e arrivare in EX al ciclo successivo. Tuttavia, dato che si è attivato il forwarding path A, l’operando sbagliato viene scartato e viene ricaricato quello proveniente da A (che è giusto). L’istruzione i2 verrà eseguita quindi correttamente, senza alcuno stallo.
In modo del tutto analogo, un’istruzione che usa in stadio EX il risultato prodotto da un load in stadio MEM può utilizzare il percorso B e stallare per solo un ciclo invece che per tre. Questo caso è mostrato nella seconda colonna.
Dal punto di vista circuitale, tutto questo significa che in testa ad ogni ingresso della ALU (e non solo lì) c’è un MUX che decide se gli operandi provengono dall’istruzione stessa, dal register file, o da uno dei forwarding paths. La logica di controllo deve tenere conto di tutte le possibili combinazioni di tutte le istruzioni e di tutti gli stadi, deve generare gli stalli e commutare i MUX, e deve anche essere in grado di trovare gli operandi più recenti che si riferiscono allo stesso registro. Si consideri questo esempio:
i1: r2 <= __ i2: __ <= r2 i3: r2 <= __ i4: __ <= r2
L’istruzione i2 deve ottenere il suo operando da i1, ma i4 deve ottenerlo da i3, non da i1! Se sia i1 che i3 sono ancora presenti nella pipeline al momento che i4 deve ottenere i suoi operandi, la logica di controllo deve capire che la versione più recente di r2 è quella prodotta da i3, e manovrare i MUX di conseguenza.
Il caso del forwarding path C merita un’attenzione particolare. Gli stadi di Operand Fetch e Writeback sono logicamente distinti, ma in effetti si riferiscono alla stessa risorsa architetturale: il register file. OF legge dal register file, e WB scrive in esso. Quello che si può fare è fondere le due operazioni in un unico ciclo di clock: nella prima metà del clock il register file viene scritto da WB, e nella seconda metà viene letto da OF. In questo modo non c’è bisogno di alcun forwarding path C, perchè OF si ritrova i dati più aggiornati direttamente nel register file. Si parla in questo caso di internal forwarding (i dati sono inoltrati “implicitamente” all’interno del register file).
Conclusioni: limitazioni della in-order pipeline
Il pipelining è una tecnica relativamente semplice ed estremamente efficace per aumentare le prestazioni dei processori. È la tecnica che ha permesso alle CPU di aumentare la frequenza operativa in modo esponenziale, da metà degli anni ’80 fino ai primi anni 2000. Tuttavia, la semplice pipeline in-order soffre di alcune grosse limitazioni:
- ha un limite fisiologico di IPC (istruzioni per clock) pari a 1: come ovvio, al più una istruzione può entrare, e una uscire, dalla pipeline ad ogni colpo di clock
- pipeline molto lunghe sono inefficienti: all’aumentare del numero di stadi il guadagno di frequenza diminuisce sempre di più, l’overhead di area aumenta, la dissipazione termica diventa ingestibile, e le dipendenze introducono sempre più stalli nella pipeline; per questi motivi, dopo il fallito tentativo di NetBurst di superare i 30 stadi (fallito nel senso che le prestazioni non giustificavano i consumi), la maggior parte dei processori si è assestata su pipeline tra 10 e 20 stadi
- rigidità: se un’istruzione stalla, tutte quelle che seguono devono per forza stallare, e l’intera pipeline si ferma; questo non è strettamente necessario: alcune istruzioni potrebbero continuare a procedere, se non hanno dipendenze con quelle che vengono prima di loro, ma la pipeline in-order non lo permette
- inefficienza di unificazione: creare una singola pipeline capace di eseguire ogni tipo di istruzione significa necessariamente introdurre stadi dedicati ad alcune operazioni (e quindi inutili per tutte le altre); questo incrementa la latenza di esecuzione delle singole istruzioni, e aumenta il numero di dipendenze e il numero di stalli che devono essere introdotti
Per tutti questi motivi, i computer architect cominciarono a studiare nuovi sistemi per superare le limitazioni della pipeline in-order, estrarre maggior parallelismo tra le istruzioni e aumentare le prestazioni. La ricerca sulla data flow computation degli anni ’70 e ’80 permise la costruzione di processori superscalari out-of-order, che divennero mainstream a metà degli anni ’90 con il Pentium. Di questi mi occuperò nei prossimi articoli.







