Ogni programmatore che si rispetti conosce l’importanza del riutilizzo del codice, e di quanto sia consigliabile strutturare e modularizzare il codice in modo da facilitarne il riuso in diverse applicazioni.
Esistono diversi modi per raggiungere lo scopo, più o meno efficaci (compreso l’uso del solo incapsulamento sfruttando i costrutti sintattici dei linguaggi che supportano il paradigma di programmazione orientata agli oggetti), ma non mi soffermerò sull’argomento, che non rappresenta il tema dell’articolo.
Su AmigaOS la strada maestra è rappresentata dalle cosiddette librerie, concetto cardine che permea l’intero sistema operativo, il quale espone API e funzionalità proprio sotto forma di singole librerie dedicate a precisi scopi.
Fra le più comuni e conosciute sono exec.library (che rappresenta praticamente il kernel), graphics.library (per gestire la grafica, compresi sprite, Blitter e Copper), intuition.library (si occupa dell’interfaccia grafica: quindi finestre, caselle di testo, ecc., e ovviamente gli eventi), dos.library (filesystem, processi, & co.), e tante altre che si trovavano già nella ROM oppure nei dischetti (quelle meno importanti / usate).
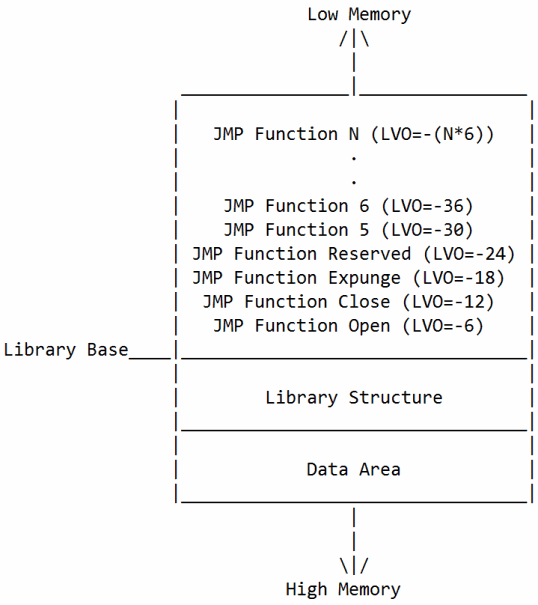
L’idea è quella di organizzare il codice suddividendolo in funzioni (che possono accettare anche dei parametri, e restituire eventualmente un valore; in tutti i casi sfruttando i registri della CPU), che vengono esposte all’esterno tramite un meccanismo di vettori indirizzati da ben precisi offset relativi a una certa struttura:
Un’applicazione che vuol richiamare un’API di una libreria deve prima “aprire la libreria” (tramite l’API OpenLibrary fornita dall’unica libreria di sistema che risulta sempre aperta, exec.library) ottenendo quello che si chiama in gergo (puntatore alla) “base della libreria” (Library Base in figura), che verrà sempre passato in un preciso registro del processore (A6 nel caso dei 68000).
Ottenuto il riferimento a quest’oggetto, tutte le API possono essere invocate eseguendo un salto all’indirizzo che si ottiene dalla base sottraendo un ben preciso offset, a multipli di 6 byte.
Le prime 4 API (offset -6, -12, -18, e -24) sono riservate per la gestione della libreria da parte del s.o.; vengono invocate rispettivamente quando ne viene richiesta l’apertura, la chiusura, e l’eliminazione dalla memoria (se nessuna applicazione ne fa uso e il sistema ha bisogno di recuperare memoria); l’ultima è riservata.
La prima API “utile” a un programma è, quindi, quella che si trova all’offset -30, la seconda a -36, e così via. Il motivo per cui è stato scelto di procedere a passi di 6 byte è molto semplice: a tale indirizzo è generalmente (perché non è sempre vero!) presente un’istruzione JMP (del Motorola 68000) all’indirizzo vero e proprio della funzione, che occupa esattamente 2 (per l’opcode principale) + 4 (per l’indirizzo a 32 bit) byte.
Per una normalissima applicazione l’uso di una libreria finisce qui (a parte il fatto che va obbligatoriamente chiusa prima di terminare l’esecuzione!), in quanto l’unico scopo è quello di invocarne le API, appunto, ma a volte può essere utile accedere ai dati presenti a partire dalla “base”.
Questo perché librerie come Exec (ma anche altre) espongono delle strutture dati che, sebbene ne sia deprecato l’accesso (in quanto fonte primaria di problemi e incompatibilità varie, poiché in teoria potrebbero cambiare in base alle versioni), consentono di ottenere l’elenco dei task, giusto per fare un esempio.
Tali informazioni si trovano in quella che in figura viene denominata Data Area, cioè un’area di dati privati della libreria. Il formato è definito strettamente per quella particolare libreria e, come già detto, sulla carta è possibile che cambi in base alla versione (anche se non è mai stato fatto per non rompere la compatibilità con le applicazioni scritte male che ne fanno uso).
Infine la parte chiamata Library Structure è costituita da struttura fissa e standard (per chi mastica un po’ di C):

Viene utilizzata esclusivamente dal sistema per la gestione della stessa (apertura, chiusura, eliminazione, ma anche rintracciabilità nel caso in cui si faccia una ricerca delle librerie aperte).
A parte la Library Structure, la struttura della tabella dei vettori e della Data Area richiama alla mente l’implementazione comune della Virtual Method Table dei linguaggi OOP, con la tabella dei metodi virtuali che precede l’area dati privata della classe (che racchiude, ad esempio, la dimensione di un’istanza) e le variabili “statiche” (o di classe).
Poiché la Data Area è un’area privata della libreria e, quindi, condivisa da tutte le applicazioni che l’hanno aperta e ne fanno uso, il modello implementato è sostanzialmente “puro” o rientrante. L’accesso alle informazioni della Data Area (se presente, visto che è opzionale: molte librerie non ne fanno uso!) è, infatti, regolato internamente tramite l’uso di appositi meccanismi di sistema (semafori et similia).
Ciò è particolarmente utile in un ambiente multitasking, dove avere a disposizione strutture thread-safe elimina molti problemi. Il tutto con l’ulteriore, pregevole, vantaggio di rendere il codice “ROMable”, quindi facilmente memorizzabile su ROM, EPROM, ecc., come fece Commodore con le librerie più importanti.
Un’altra caratteristica delle librerie è che sono presenti in copia unica nel sistema. Non esistono, infatti, file diversi per versioni diverse di una stessa libreria. Versioni successive possono aggiungere altre API, sfruttando il già visto meccanismo degli offset negativi, senza intaccare le precedenti.
In questo modo applicazioni vecchie possono girare tranquillamente usando le versioni delle librerie di cui fanno uso, senza per questo richiedere quella particolare versione che era presente al momento della loro distribuzione.
E’ una cosa che continuo ancora oggi ad apprezzare particolarmente. Non ho mai digerito, infatti, il caos dovuto alla presenza di librerie con versioni diverse in altri sistemi operativi (Windows e Linux in primis) e, peggio ancora, i problemi dovuti alla compilazione di una libreria con compilatori diversi, o addirittura con versioni diverse dello stesso compilatore.
Vero è che la stessa cosa si sarebbe potuta fare con AmigaOS (ad esempio si sarebbero potute creare gadtools20.library, gadtools21.library, gadtools31.library, ecc. ecc.), ma l’esempio fornito dal s.o. (che non ha mai avuto librerie con versioni diverse), oltre a linee guida chiare e che praticamente imponevano un certo modello (mentale) di sviluppo, ha contribuito ad accettarlo e a cristallizzare la situazione anche in ambito privato / non di sistema.
Lo svantaggio di quest’approccio è che un bug che affiora in una particolare versione di una libreria può compromettere tutte le applicazioni che ne fanno uso. E’ un rischio concreto e con implicazioni decisamente pesanti, ma lo si risolve con workaround, usando una versione precedente, oppure con le classiche patch (divenute di comune uso proprio in ambito Amiga).
D’altra parte bisogna considerare che anche s.o. moderni generalmente mettono a disposizione singole copie delle loro librerie. Giusto per essere chiari, quante copie esistono di kernel32.dll su Windows 7? Soltanto una, e non una per ogni versione precedente di Windows e/o Service Pack, e i problemi vengono risolti tramite successive patch.
Anche il fatto che le librerie siano “pure” presenta degli svantaggi, anche se ciò dipende dalle “pratiche” in voga negli altri s.o.. Per fare un esempio pratico, prendiamo Python, il linguaggio di programmazione che preferisco e utilizzo a lavoro.
Una volta installato, su Windows mi ritrovo con un piccolissimo file python.exe di qualche decina di KB, e una libreria python25.dll (per la versione 2.5 del linguaggio) di circa 2MB (più una serie di librerie accessorie, ma non le consideriamo ai fini del discorso). E’ chiaro che l’eseguibile aprirà la DLL, che contiene tutto il codice che implementa la virtual machine di questo linguaggio.
Per un porting su AmigaOS mi aspetterei qualcosa di simile, quindi un eseguibile chiamato python costituito da una manciata di KB, e una python.library (o, al limite, una python25.library se non si può fare a meno di avere una libreria diversa per ogni versione; sic!) con tutto il codice della VM.
Invece si trova soltanto il primo, che contiene tutto. Quindi possiamo scordarci di condividere lo stesso codice per tutte le applicazioni che potrebbero far uso della VM Python al loro interno. Codice che, di conseguenza, verrà duplicato ogni volta.
Tutto ciò è dovuto al fatto che negli altri s.o. le librerie fanno uso di dati privati per ogni applicazione che le apre. In sostanza il codice è sempre lo stesso, ma per ogni applicazione viene creata una nuova sezione di dati specifica per la libreria caricata, in modo che questa possa ritrovarci le informazioni che le sono necessarie per lavorarci.
Questo non si può realizzare con AmigaOS, in quanto la sezione dati privata della libreria è unica, ed è condivisa da tutte le applicazioni, come abbiamo visto.
In questi anni ho pensato a una soluzione, di cui espongo brevemente il concetto. Si potrebbe estendere l’attuale modello di librerie introducendone un altro tipo che segnali al s.o. la necessità di creare una copia dei dati per ogni chiamata alla OpenLibrary.
Quindi la OpenLibrary restituirà un Library Base diversa per ogni task, che conterrà la medesima tabella dei vettori (che verrà semplicemente ricopiata ogni volta), ma Data Area nuova, inizializzata opportunamente (nel codice dell’API interna con offset -6, che abbiamo visto prima).
Per ottenere ciò sarebbe necessario modificare leggermente la gestione delle librerie da parte di AmigaOS, in modo da caricare e istanziare correttamente quelle di questo tipo. Inoltre il compilatore dovrebbe provvedere a isolare tutti i dati globali, referenziandoli poi nel codice tramite offset alla Data Area; includendo, inoltre, il codice di inizializzazione e finalizzazione in quello richiamato dalle apposite API interne.
In questo modo non si stravolgerebbe del tutto il modello attuale, ma verrebbe esteso per includere una vasta gamma di nuove possibilità, specialmente in ottica di integrazione “più Amigaosa” della massa di codice già scritto per altri sistemi e che, inutile nasconderlo, farebbe molto comodo…







