Osservando la crescita esponenziale delle prestazioni dei nostri computer e i benchmark che anno dopo anno sfondano nuovi traguardi che prima sembravano irraggiungibili, viene naturale pensare che i produttori di CPU e GPU mirino sempre a produrre i chip più veloci che la tecnologia rende possibile. Non è così: come qualsiasi azienda, anche i chip makers hanno innumerevoli compromessi da soddisfare, tra cui prestazioni, consumo energetico, il costo del silicio e dello sviluppo delle tecnologie, lo sforzo ingegneristico richiesto, i limiti di validazione e testing, e altri ancora.
Circa due mesi fa, Glenn Hinton, Lead Architect per lo sviluppo della microarchitettura Nehalem, fece una presentazione in cui discusse la storia e le sfide dietro la realizzazione di questa architettura. Le slide e il video sono disponibili a questo link (è il settimo talk):
http://www.stanford.edu/class/ee380/winter-schedule-20092010.html
In questa serie di due articoli userò lo sviluppo di Nehalem come case study per illustrare i compromessi e le decisioni architetturali che stanno dietro la realizzazione di un processore di ultima generazione. In questo articolo discuterò della timeline, della decisione di Intel di sviluppare una singola architettura per tutti i segmenti di mercato (la strategia “converged core”), e dei requisiti fondamentali di tale architettura. Nel prossimo andremo più in profondità e analizzeremo le scelte ingegneristiche rigurdanti pipeline, core, cache e gestione dell’energia.
Timeline
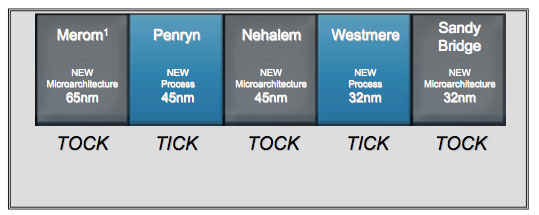
La maggior parte dello sviluppo di Nehalem fu portato avanti nel sito Intel in Oregon (il più grande sito americano della compagnia di Santa Clara), su un arco di tempo di più di 5 anni. La ricerca di base sulla microarchitettura risale a prima del 2003; nel 2003-04 vennero prese la maggior parte delle decisioni architetturali, e il lavoro di ingegnerizzazione (sviluppo, validazione e testing) occupò più di 3 anni, dal 2005 al 2007 e oltre. I primi prodotti basati su Nehalem vennero lanciati nel 2008. Vale la pena ricordare che al culmine del processo di sviluppo di un chip di questa classe vi lavorano alcune migliaia di persone: questo significa che il lavoro è nell’ordine delle decine di milioni di ore-uomo.
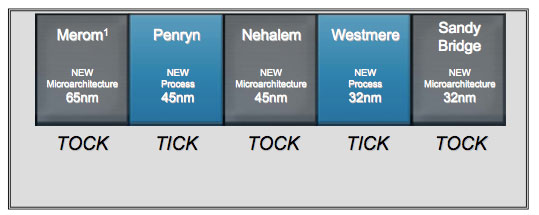
Converged core: compromessi
All’inizio degli anni 2000, Intel sviluppava due diverse microarchitetture: una ad alte prestazioni (Pentium 4) nel sito di Hillsboro, Oregon, per desktop e server, e una a basso consumo (Banias) in quello di Haifa, Israele, per i portatili.
Se da un lato avere architetture dedicate per diversi ambiti permette di ottimizzare i processori per quei requisiti (alte performance VS bassi consumi), dall’altro richiede il doppio dello sforzo ingegneristico. Per questo Intel decise di sviluppare una singola architettura che andasse bene per tutti i segmenti di mercato (tranne per l’ultra-mobile, coperto da Atom): poter dedicare un maggior numero di risorse e personale ad un singolo progetto permette da un lato di ottimizzare e “rifinire” al meglio il chip (recuperando in parte lo svantaggio dato dai molti compromessi sui requisiti contrastanti) e dall’altro di usare meno risorse per lo sviluppo, abbassando i costi.
Nehalem è il primo vero rappresentante di questa strategia “converged core”: per questo l’analisi dei compromessi architetturali è particolarmente interessante.
Mobile, desktop, server
I tre segmenti di mercato che Nehalem deve coprire sono mobile, desktop e server. I requisiti principali per ognuno sono:
- Mobile:
- bassa potenza: fondamentale per aumentare la durata delle batterie e per non fondere il computer; questo significa avere a disposizione degli “sleep state” a bassissimo consumo e un power management molto aggressivo e dinamico
- 1/2/4 core, con cache scalabile
- moderata banda verso la RAM, a basso consumo
- basso costo (grandi volumi)
- ottime prestazioni single-threaded, dal momento che la maggior parte delle applicazioni per laptop non sfruttavano il multi-threading
- Desktop:
- 1/2/4 core, con cache scalabile
- buona banda verso la RAM
- ottime prestazioni per applicazioni multimediali e high-end gaming
- basso costo (grandi volumi)
- ottime prestazioni single-threaded
- Server:
- 4+ core, a basso consumo per poterne mettere di più nello stesso package
- largo uso di ECC su cache, TLBs, eccetera
- ampia banda verso la RAM, supporto di enormi quantità di RAM (che impone un maggior numero di bit di indirizzamento, con tutto l’overhead che ciò comporta)
- cache, TLBs, BTBs più grandi
- supporto per sistemi multisocket
- supporto a lock veloci e altre ottimizzazioni per codice multi-threaded
- power management aggressivo
- SMT (simultaneous multi-threading)
A questo punto i capi del progetto hanno dovuto togliersi il cappello da ingegnere e mettere su il cappello della compagnia. In quegli anni, Intel era indietro nei server (dove risentiva della concorrenza degli Opteron) e prevedeva (correttamente) che ci sarebbero stati sempre più laptop ad erodere le quote dei desktop. Quindi, scelsero di realizzare il meglio che potevano per applicazioni server e mobile, e lasciare che il segmento desktop si arrangiasse con quello che rimaneva.
Convergenze, divergenze, must-have
Laptop e server sono due segmenti molto diversi; tuttavia, esistono alcuni importanti punti di convergenza. Dall’inizio degli anni 2000, il fattore principale che ha limitato la crescita in frequenza delle CPU, e che ha di necessità spinto la corsa al multi-core, è stata la dissipazione di calore (e, diverso ma collegato, la fine dello scaling della tensione di alimentazione). Sia per i laptop che per i server avere basso consumo per core è fondamentale: per i laptop, per problemi di batteria e calore; per i server, per permettere di inserire molti core nello stesso package e rimanere nel power envelope dei blade.
I punti di divergenza sono, purtroppo, molti: i server hanno bisogno di grosse quantità di RAM, che si portano dietro la necessità di larghi spazi d’indirizzamento (inutili ai laptop) che richiedono area e potenza. Hanno anche necessità di avere molti più controlli ECC, largamente inutili in ambito laptop e desktop, e supporto per velocizzare programmi multi-threaded (poco comuni in ambito consumer, specie a quell’epoca). Tuttavia, questi erano tutti dei must-have per il segmento server, ed è stato necessario inserirli.
Laptop e desktop, dal canto loro, avevano bisogno di alte prestazioni in programmi single-threaded: si è dovuti prestare particolare attenzione alla progettazione di un’architettura capace di scalare su molti core senza penalizzare troppo le prestazioni del singolo core.
Conclusioni
Lo sviluppo dell’architettura di una moderna CPU richiede un enorme lavoro per conciliare i requisiti dei diversi segmenti di mercato. In questo articoli si è preso come riferimento il Nehalem, ma lo stesso discorso si potrebbe fare con processori AMD (basti pensare alla prossima architettura, Bulldozer, che ha come obiettivo quello di equipaggiare processori da 10W a 100W di TDP).
Il prossimo articolo sarà un po’ più tecnico, e vedremo come i requisiti discussi oggi influenzino la scelta della pipeline, la struttura dei core, la gerarchia di memoria (cache in primis) e le tecnologie per la gestione dell’energia.







