Forte del successo e consenso ricevuto dal primo rappresentante, il 68000, negli anni a seguire Motorola si dedicò a ritoccare il progetto col 68010 (sistemando alcuni errori e aggiungendo qualche funzionalità utile per la scrittura di s.o.) e fornendo anche una soluzione a basso costo col 68008 (che, col bus indirizzi a 20 bit anziché 24 e col bus dati a 8 bit anziché 16, permetteva di utilizzare un package da 48 pin invece dei canonici 64).
Si trattò, in ogni caso, di leggere modifiche al core (che cambiò poco), portandosi dietro alcune limitazioni non indifferenti, come ad esempio l’ALU interna che per i calcoli rimaneva a 16 bit, costringendo quindi a utilizzarla due volte per le istruzioni che manipolavano dati a 32 bit (il calcolo degli indirizzi, invece, poteva contare su alcuni sommatori dedicati a 32 bit), e richiedendo pertanto più cicli di clock per l’espletamento della funzione.
Purtroppo all’epoca era veramente difficile fare di più, in quanto l’architettura del 68000 era già abbastanza complicata e richiedeva non pochi transistor (circa 68000, appunto; si trattava di una CPU molto costosa per l’epoca), per cui la sua architettura a 32 bit dovette attendere ben 5 anni, con l’arrivo del 68020 nel 1984, per esprimere tutto il suo potenziale.
Grazie ai suoi 190mila transistor, infatti, metteva finalmente a disposizione un’ALU che permetteva di operare con dati a 8, 16 e 32 bit alla stessa velocità, oltre a un’efficiente unità di calcolo degli indirizzi (le cui modalità con questo microprocessore arrivano a essere particolarmente complicate).
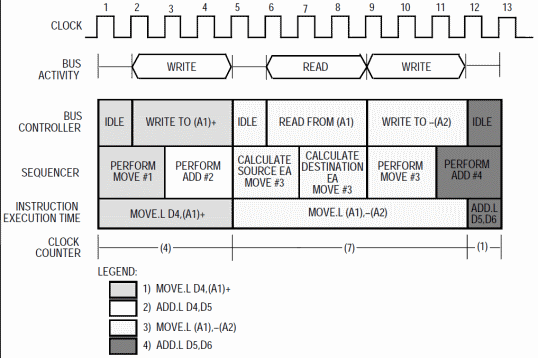
L’efficiente pipeline a 3 stadi permetteva un certo livello di sovrapposizione nell’esecuzione delle istruzioni la quale, con un’accorta schedulazione nella sequenza delle istruzioni, comportava un certo risparmio di cicli di clock per alcune di esse, fino ad arrivare addirittura a non impiegarne nessuno (l’esecuzione viene completamente “assorbita” da quella per la precedente istruzione):
Come si può notare dall’esempio, la seconda istruzione non richiede alcun ciclo di clock in quanto risulta del tutto “assorbita” dall’esecuzione della precedente, mentre la quarta, approfittando di una parziale sovrapposizione con la terza, riesce a essere completata richiedendo soltanto un ciclo di clock.
Tutto avviene anche grazie ad altre migliorie introdotte con questo processore, prima fra tutte l’introduzione di una cache di 256 byte per il codice, che consente di memorizzare fino a 64 longword (allineate ovviamente a indirizzi di 32 bit), sfruttando un meccanismo di tipo direct mapped (si sfruttano i bit da 7 a 2 per selezionare la longword nell’instruction cache, per poi controllare, se è presente un dato caricato, se i rimanenti bit da 31 a 8 coincidono con quello “in lavorazione”).
Un meccanismo molto semplice, ma abbastanza efficiente, che permette di risparmiare gli accessi in memoria per il fetch delle istruzioni, in particolare quando si eseguono cicli. Per la gestione di questa cache Motorola ha introdotto soltanto due registri disponibili esclusivamente nella modalità supervisore, CACR (Cache Control Register; contiene alcun flag, fra cui quello di abilitazione della stessa) e CAAR (Cache Address Register; usato soltanto per azzerare una specifica linea di cache).
Altro elemento che ha contribuito notevolmente al miglioramento delle prestazioni è stato il bus dati a 32 bit, che ha permesso finalmente di manipolare informazioni di questa dimensione in un colpo solo. In realtà tutta la logica legata all’interfaccia esterna è cambiata, e permette adesso di leggere e scrivere da 1 a 4 byte (quindi anche 3: numero abbastanza strano per chi è a abituato a lavorare con potenze di due) da qualunque periferica, togliendo di mezzo il precedente collo di bottiglia che imponeva indirizzi pari per l’accesso a dati di 16 o 32 bit (pena il sollevamento di un’eccezione).
A conti fatti, è il controller del bus che, in maniera del tutto trasparente all’applicazione, si occupa di verificare l’allineamento dei dati, e di provvedere poi a effettuare uno o più accessi al bus, e infine ricombinare opportunamente i dati selezionando le parti interessate (esempio: leggo un solo byte dall’indirizzo $3, e i primi 3 byte a partire dall’indirizzo $4, che combinati assieme forniscono la longword che m’interessava leggere dall’indirizzo $3).
Ovviamente si tratta di un meccanismo che ha un suo costo in termini di transistor, e che comporta in ogni caso una penalizzazione in termini prestazionali, a causa del maggior numero di accessi al bus necessari per completare l’operazione, per cui è sempre consigliabile allineare opportunamente i dati in modo da massimizzare l’efficienza del sistema (è un consiglio che vale per qualunque microprocessore).
Oltre ai registri per la gestione della cache, a livello supervisore troviamo pochi cambiamenti. E’ stato aggiunto un nuovo bit nel registro di stato supervisore (SR) che consente di abilitare il tracing delle sole istruzioni che comportano un cambio nel flusso dell’esecuzione (salti, trap, loop, ecc.; prima venivano “tracciate” tutte le istruzioni).
Inoltre è adesso disponibile un nuovo registro per lo stack da utilizzare in occorrenza degli interrupt (chiamato ISP, Interrupt Stack Pointer; mentre MSP, Master Stack Pointer, si riferisce al tradizionale stack supervisore, SSP), che consente di trattare in maniera più efficiente gli interrupt (avendo uno stack dedicato allo scopo).
Sono stati aggiunti anche dei nuovi stack frame, concetto utilizzato da Motorola per la gestione delle eccezioni che fa uso dello stack per memorizzare delle strutture dati particolari a seconda della tipologia di evento verificatosi. Si tratta, in buona sostanza, di informazioni che riflettono lo stato dell’evento e/o quello interno della CPU, in modo da permettere all’handler di avere un quadro completo per poterlo gestire correttamente.

Scusate per l’orientamento dell’immagine, ma verticalmente avrebbe occupato troppo spazio. Quest’esempio serve a rendere l’idea di quali informazioni venivano memorizzate nello stack, e quindi della loro utilità per l’handler deputato alla gestione dell’apposito evento, che poteva anche cambiare alcuni dati poi utilizzati dall’istruzione RTE (utilizzata per il rientro dall’eccezione). Da notare che sono presenti dati che riguardano addirittura gli stadi della pipeline.
Il 68020 non manca, comunque, di portare innovazioni anche a quelle aree che possiamo definire più “care” a un programmatore: i nuovi tipi di dato, le nuove istruzioni e, nel caso di questo microprocessore, le nuove (e complicate) modalità d’indirizzamento introdotte.
Due nuovi tipi di dato fanno capolino: i dati “unpacked” e i campi di bit. I primi sono legati al tipo BCD, che prevedeva già le operazioni di somma, sottrazione, e negazione di byte contenenti due cifre BCD “packed“. Con le istruzioni PACK e UNPK adesso è possibile prelevare due byte “unpacked”, aggiustarli opportunamente (tramite l’uso di un offset, utile, ad esempio, per convertire dati ASCII o EBCDIC), e convertirli in due cifre BCD “packed”; e viceversa, chiaramente.
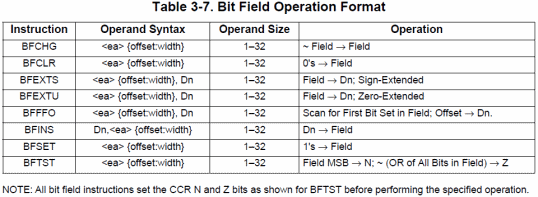
Molto più interessanti sono, invece, i campi di bit che, come si può intuire dal nome, sono dati costituiti da un numero variabile di bit (da 1 a 32). A tal proposito è presente un nutrito numero di istruzioni che, sfruttando il barrel shifter integrato in questa CPU, copre gli utilizzi più noti: test, azzeramento, set di tutti i bit a 1, complemento, estrazione con o senza segno, inserimento, e ricerca del primo bit a 1.
Inoltre tutte le istruzioni eseguono prima un test del campo di bit, copiando il bit più significativo del campo nel flag N (che normalmente contiene il segno di un numero intero), e settando il flag Z (di “zero”) opportunamente (1 se il campo di bit vale zero, 0 altrimenti). In pratica è come se ogni istruzione eseguisse prima una BFTST (Bit Field TeST) prima di procedere all’operazione vera e propria, in pieno “stile Motorola” (coi 68000 anche delle normali MOVE impostano questi flag, come se venisse eseguita una TST sull’operando sorgente).
Sempre per quanto riguarda gli interi, è stata introdotta un’istruzione che permette di estendere con segno un byte a una longword (prima era possibile estenderlo soltanto a una word). Ma la novità più importante è l’introduzione di apposite istruzioni che consentono finalmente di eseguire moltiplicazioni e divisioni che vanno oltre le classiche 16×16 -> 32 bit e 32/16 -> 16,16 bit (quoziente e resto) rispettivamente.
Finalmente è possibile eseguire moltiplicazioni 32×32 -> 32 bit (vengono conservati i soli 32 bit bassi del risultato) e 32×32 -> 64 bit. Più variegate le divisioni, che adesso consentono 32/32 -> 32 bit (solo quoziente), 32/32 -> 32,32 bit (quoziente e resto), 64/32 -> 32,32 (quoziente e resto). Si tratta di una grossa lacuna che la famiglia 68000 si trascinava da tempo, e che viene finalmente colmata.
Le nuove istruzioni di check/confronto completano il quadro per quanto riguarda le estensioni sugli interi. Il 68000 metteva già a disposizione l’istruzione CHK per verificare se un intero era compreso in un intervallo (altrimenti veniva sollevata un’eccezione), ma aveva tre limitazioni: l’intero doveva risiedere su un registro dati (niente registri indirizzi), doveva essere una word o una longword (niente byte), e il limite inferiore era fissato a 0. CHK2 li rimuove tutti e tre, fornendo pertanto maggior flessibilità.
Un grosso tallone d’Achille di questa famiglia è stato rappresentato dalla penuria di istruzioni per la sincronizzazione in ambienti multiprocessor. L’unica istruzione in merito era la TAS (Test And Set), che agiva su un solo byte, leggendolo dalla memoria e settando il bit più significativo in un ciclo di read-modify-write col bus lockato (da evitare come la peste sugli Amiga).
Ben poca cosa, insomma, ed è per questo che Motorola ha messo a disposizione CAS e CAS2, istruzioni che consentono di eseguire un confronto (di byte, word e longword per la prima; coppie di word e longword la seconda) di un registro (due per la CAS2) con un operando in memoria (ancora due per la CAS2) e, nel caso in cui i valori coincidano, scrivere in memoria il valore di un altro registro (sempre due per la CAS2), il tutto col bus lockato.
A livello di istruzioni utili al s.o. c’è da segnalare la presenza di un’istruzione di TRAP condizionata (viene sollevata in presenza di una condizione), e del supporto al concetto di chiamata a “modulo” (tramite le istruzioni CALLM e RTM). Quest’ultimo riguarda la possibilità di richiamare delle funzioni effettuando dei precisi controllo sulle modalità di esecuzione, provvedendo eventualmente a copiare dati dal chiamante all’area dimemoria del modulo chiamato. Si tratta di un meccanismo complicato e, com’è possibile immaginare, particolarmente lento (nel peggiore dei casi si arriva a superare i 450 cicli di clock).
Il pezzo forte di questa CPU è, a mio avviso, rappresentato dalle nuove modalità d’indirizzamento che mette a disposizione:
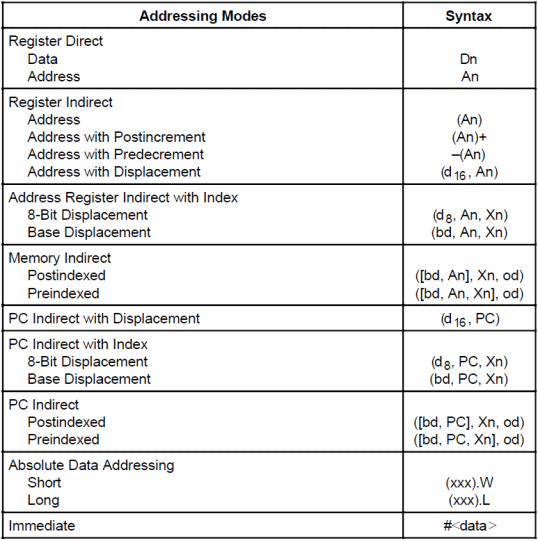
Siamo passati dalle 14 del 68000, alle 18 attuali. Le quattro nuove modalità sono denominate Memory Indirect (Postindexed e Preindexed) e PC Indirect (Postindexed e Preindexed). Possono sembrare poche, ma risultano estremamente flessibili in quanto permettono di indirizzare la memoria indirettamente, come specifica il nome.
Il meccanismo funziona in questo modo: viene calcolato prima l’indirizzo del puntatore da leggere valutando tutti gli operandi presenti fra parentesi quadre; viene quindi prelevato il puntatore, e a questo vengono sommati gli operandi presenti fuori dalla parentesi quadre; a questo punto l’indirizzo risultante viene finalmente utilizzato per leggere o scrivere il dato dalla memoria.
I benefici sono indubbi, considerato che queste modalità sono applicabili ove nel codice siano presenti strutture dati che fanno uso di puntatori, oppure per accedere alla tabella dei metodi virtuali delle classi per i linguaggi orientati gli oggetti. Inoltre anche le “vecchie” modalità d’indirizzamento presentano dei miglioramenti, perché a ogni registro Xn è possibile applicare un fattore di scala da 1 a 8.
Infine, e non meno importante, il 68020 porta in dote una completa e avanzata interfaccia verso i coprocessori, per i quali è possibile salvare e ripristinare lo stato interno, eseguire salti condizionati sulla base del loro registro di stato, eseguire cicli nelle stesse modalità, TRAP condizionate, settare un byte sulla base di una condizione, e ovviamente eseguire delle operazioni.
Tanta, veramente tantissima carne sul fuoco che Motorola mette con questo microprocessore, che possiamo considerare come ideale completamento di un’architettura che già col capostipite 68000 aveva strappato consensi e fatto felici schiere di programmatori che ancora oggi serbano un ottimo ricordo di questa gloriosa famiglia.







