Questa settimana interromperemo temporaneamente la serie di articoli sui sensori digitali per affrontare un argomento piuttosto attuale. Sui forum di tutto il mondo si è parlato e si parla ancora di Fermi, Larrabee, delle nuove GPU DX11 di ATi/AMD; uno degli argomenti più dibattuti è quello relativo al tipo di implementazione di alcune funzionalità.
Da un lato ci sono i fautori dell’implementazione di tipo hardware, con unità dedicate a svolgere uno specifico task, dall’altro quelli i sostenitori dell’emulazione via software di determinate funzionalità, con i calcoli affidati ad unità di tipo generico.
Sollecitato, ancora una volta, dal mio amico pleg, ho deciso di inaugurare una serie di articoli su questo argomento, che serviranno da spunto anche per approfondimenti sulle architetture dei vari chip menzionati in precedenza. Il tutto, ovviamente, procederà di pari passo con la mini rubrica sui sensori digitali, alternandosi in una sorta di multitasking.
Stabilire a priori se una strada sia migliore dell’altra è molto difficile. Nel corso degli anni, chi ha seguito l’evoluzione delle architetture delle GPU, ha assistito al passaggio da chip con alu dedicate ad uno specifico compito a chip con alu “generiche”, i cosiddetti shader unificati.
In quel caso specifico si è assistito ad un notevole boost prestazionale, dovuto alla maggior efficienza di un’architettura di questo ultimo tipo. La cosa, però non deve trarre in inganno e portare a concludere che l’utilizzo di unità dedicate sia sempre controproducente.
La prima distinzione va fatta proprio a livello di dimensioni del blocco funzionale che si va a sostituire. Se rimpiazzo sia il pixel che il vertex shader engine con un core a shader unificati, il vantaggio non deriva dalla velocità di esecuzione della singola operazione su una specifica unità che, anzi, in un’architettura unificata risulta più lenta, quanto dal fatto che riesco a sfruttare meglio l’intera architettura del chip.
Fatta questa premessa, partiremo proprio da considerazioni derivanti dal passaggio imposto dalle DX10 per poi andare a vedere, in alcuni casi specifici, come i vari progettisti hanno deciso di risolvere, di volta in volta, il, dilemma se rimpiazzare o tenere unità dedicate o di tipo fixed function.
Fino alla generazione DX9 la situazione era schematizzabile nel modo seguente:
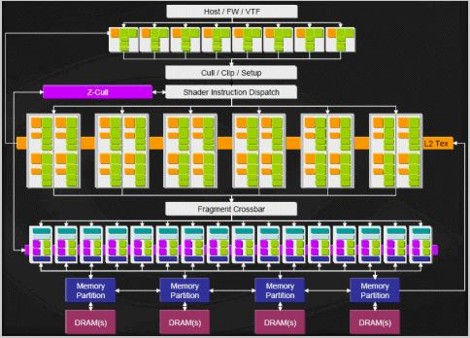
nell’immagine è riportato lo schema del G70 (7800, 7900, 7950) di nVIDIA. in cui si distinguono chiaramente i 3 principali blocchi di unità funzionali. Il primo che comprende le 8 unità di vertex shading e l’engine che si occupa di effettuare le operazioni di triangle setup, clipping, z-culling ecc.;il secondo blocco è quello che si occupa delle operazioni di pixel shading e texturing; infine c’è il terzo gruppo di unità, dette ROP’s ( o raster operation pipeline) che si incaricano delle operazioni di z-buffering, di “colorare” materialmente i pixel in base ai risultati delle operazioni matematiche, facendo color a alpha blending, di applicare il MSAA.
L’elaborazione di un’immagine 3D era quindi schematizzabile come un flusso di dati e istruzioni che viaggiano da un blocco funzionale all’altro nel modo seguente.
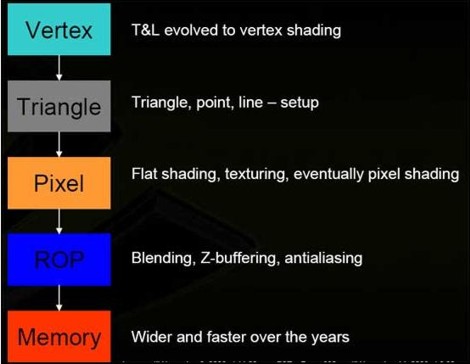
In un siffatto schema, ogni unità di calcolo ha un compito ben specifico da eseguire. Le cose non erano così lineari neppure ai tempi delle DX9, in realtà, perchè, ad esmepio, rispetto allo schema mostrato qui sopra, le operazioni di texture fetch, su texture non filtrate, erano possibili anche per le unità di vertex shading (le DX9c hanno introdotto il vertex texturing).
Occorre fare una considerazione: il carico tra le operazioni geometriche e le altre, ancora oggi è distribuito in maniera tale che le rpime pesino per circa il 30% e le altre per il restante 70% circa.
Questo per vari motivi non ultimo il fatto che, ad esempio, le operazioni di pixel shading sono quelle a latenze più elevate per mascherare le quali si ha bisogno di un gran numero di thread in circolo. Con lo schema precedente, ogni blocco funzionale riceve i dati da quello precedente e prima che ciò avvenga non può iniziare la sua elaborazione. Così, ad esmepio, i pixel shader possono operare solo dopo che il triangle setup engine ha “sfornato” le primitive su cui lavorare.
Allo stesso modo, una volta che i vertex shader, una volta inviati i dati elaborati passano alle successive istruzioni e vanno avanti fino a che non hanno riempito un buffer, presente tra la pipeline geometrica ed il pixel shader core, che contiene i dati destinati alla successiva elaborazione da parte dei pixel shader. Riempito questo buffer, restano in idle fino a che i pixel shader non hanno terminato il loro lavoro. Chiaro, quindi che è praticamente impossibile avere la piena occupazione di tutte le unità funzionali con una siffatta architettura. La situazione che ho tentato di descrivere a parole, è schematizzata da questa immagine

Immagino che qualcuno di coi abbia visto più volte questa slide (una di quelle mostrate alla presentazione di G80). La figura mostra che nel caso in cui l’elaborazione geometrica sia molto pesante, si ha una situazione in cui i VS (vertex shader) risultano occupati al 100% mentre i pixel shader sono in “vacanza”. Al contrario, quando il carico di lavoro grava tutto o quasi sui PS (pixel shader) questi sono iper impegnati e i VS sono alle Maldive.
L’idea di poter utilizzare meglio il silicio, ha spinto i progettisti ad abbracciare la filosofia degli shader unificati
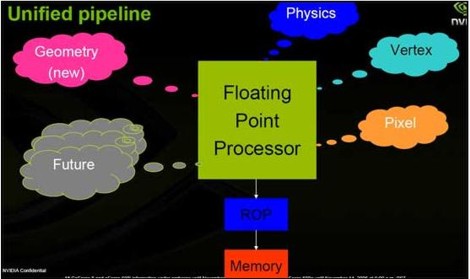
Come si vede dallo schema, in questo caso, le stesse unità si occupano delle operazioni di pixel e vertex shading, della gestione della fisica, dei geometry shader (introdotti con le DX10), ecc.
Questo dovrebbe far cambiare lo stato di occupazione delle unità nel modo seguente

Insomma, a giudicare da quest’ultima immagine, pare si sia trovato il classico uovo di Colombo (rigorosamente maiuscolo). La situazione, in effetti, è migliorata notevolmente: magari non nel modo illustrato anche perchè non tutte le architetture a shader unificati hanno lo stesso rendimento (ma questo è un altro discorso).
Dalle slide e dalle considerazioni precedenti, risulta chiaro che il vantaggio degli shader unificati risiede nell’ottimizzazione del lavoro dell’intero chip e non nella maggior efficienza della singola operazione.
Anzi, quest’ultima diminuisce in quanto mentre prima ogni unità aveva il suo compito specifico e “sapeva cosa fare” con alu di tipo generico ogni unità ha in coda istruzioni relative a diversi tipi di dati; quindi, di volta in volta, qualcuno deve dirle cosa fare e in che modo. Per questo motivo, in un chip a shader unificati aumenta notevolmente la complessità dei circuiti preposti a controllare ed organizzare il lavoro del chip; questa complessità è tanto maggiore quanto più ci si sposta da architetture in cui gran parte del lavoro di scheduling è affidato al compilatore, ad architetture dove la totalità della distribuzione del workload è gestito in hardware.
Abbiamo visto come a livello macroscopico, l’abbandono di unità dedicate a svolgere un particolare task abbia portato notevoli benefici ma questo è stato essenzialmente dovuto alla possibilità di organizzare e gestire in maniera diversa il lavoro dell’intero chip. C’è anche da specificare che, dal punto di vista funzionale, l’aver sostituito due unità una dedicata ai VS ed una ai PS con una unica esegua entrambi i tipi di istruzioni (più altri) non ha comportato grandi problemi, in quanto le operazioni svolte sono sempre le medesime.
Diverso il discorso ed anche i risultati ottenuti, quando si è tentato di seguire altre strade. Ad esempio, si può ricordare il caso dell’R600 di ATi, in cui le operazioni di resolve del MSAA erano eseguite dallo shader core e non dalle ROP’s. In tal caso, il risultato è stato che le prestazioni, con MSAA attivo, calavano vistosamente.
Dopo di allora, nessuno ha più tentato l’esperimento del resolve del MSAA via shader e, persino con le ultime versioni di API che prevedono anche l’adozione di filtri di tipo custom, persino di tipo non lineare e, quindi, non applicabili via ROP’s, il circuito che fa interpolazione lineare dei sample del MSAA box delle ROP’s è rimasto al suo posto.
Evidentemente, in questo caso, il vantaggio di avere unità di tipo generico e quindi riutilizzabili per altri compiti non era compensato dalla perdita di prestazioni di un’implementazione via software dell’operazione di resolve. Si, perché, di fatto, l’avere unità generiche ha come vantaggio quello di poter riutilizzare le stesse per più task; questo significa un notevole risparmio quando i blocchi da rimpiazzare sono di grandi dimensioni (l’intero shader core di un chip unificato rappresenta un bel vantaggio in termini di numero di unità generiche che si riescono a realizzare e, quindi, lo svantaggio di avere la singola unità meno veloce di una dedicata è compensato dall’elevato numero e dalla maggior efficienza del chip).
Lo svantaggio, di contro, è quello della minor velocità d’esecuzione della singola unità; quindi quando le unità da rimpiazzare sono poche o la loro sostituzione obbliga all’esecuzione di operazioni che richiedono molti più cicli di clock per essere portate a compimento, l’adozione di unità generich diventa controproducente.
Dopo quello del MSAA su R600, un altro esempio che mi viene in mente è quello del tessellator. In questo caso la sua funzione è possibile emularla utilizzando i vertex shader ma l’emulazione può avvenire a diversi livelli, perché si tratta di un blocco funzionale composto da più stadi, alcuni programmabili ed altri no. Ad esempio, abbiamo visto le implementazioni che ne ha fatto ATi. Prendiamo come riferimento gli utlimi due chip, RV770 ed RV870 e schematizziamo la pipeline grafica nel modo seguente
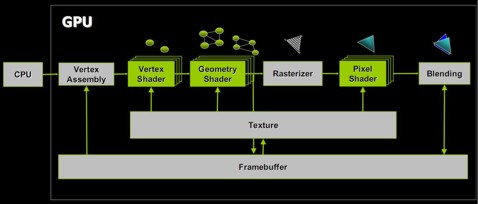
dove in grigio sono segnati gli stadi composti da fixed function; questa è una pipeline DX10; con le DX11 è stato aggiunto il tessellator, a monte delle unità di vertex shading. Anche il tessellator è composto da fixed function e stadi programmabili. In particolare, questi utlimi sono noti come hull shader e domain shader. ‘implementazione che ne ha fatto ATi in RV770, prevede che hull e domain shader siano emulati da vertex e geometry shader rispettivamente mentre rimane la parte del tessellator vera a propria, composta da fixed function. In RV870, invece, seguendo pedissequamente le specifiche DX11, hull e domain shader sono diventati due stadi fisicamente presenti sul chip e non più emulati, secondo lo schema seguente:
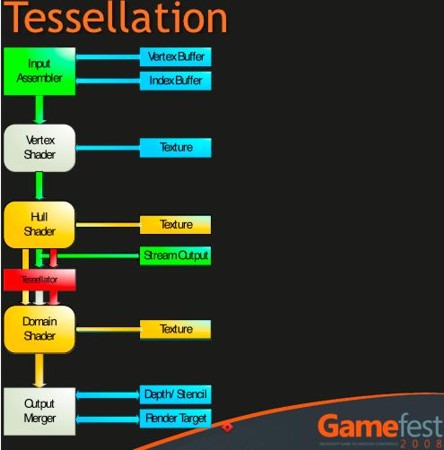
dove l’input assembler è un po’ più complesso di come è schematizzato nella figura.
Con Fermi, nVIDIA ha adottato una soluzione simile a quella vista per RV770, con hull e domain shader rimpiazzati da vertex e geometry shader che ne emulano le funzionalità. Lo schema proposto in GF100 è il seguente
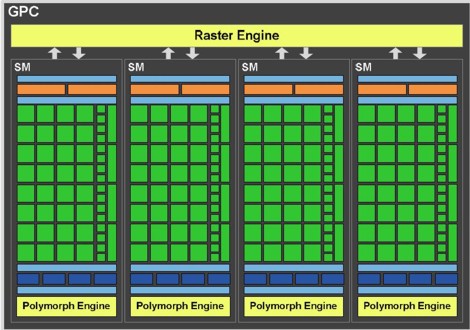
nell’immagine è riportato uno dei 4 GPC (graphic processing cluster) che compongono Fermi. E, in basso, è riportato, in dettaglio, lo schema del polymorph engine
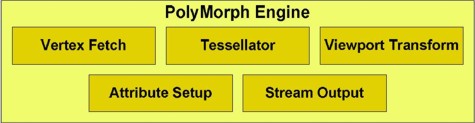
Il polymorph engine racchiude tutti gli stadi di tipo fixed function che compongono la prima parte della pipeline grafica dedicata alle operazioni geometriche mentre il raster engine gli elementi di tipo fixed function che concorrono alle operazioni di rasterizzazione. L’approccio di nVIDIA differisce da quello visto su RV770 per il fatto che, in Fermi, sia la parte relativa alle operazioni di vertex fetch e di tessellation che quella relativa alle operazioni di rasterizzazione risulta distribuita. Ma di questo ci occuperemo quando tratteremo l’architettura di Fermi più in dettaglio. Di certo, la strada intrapresa da nVIDIA si pone a metà strada tra quella di ATi e quella, che vedremo tra poco, scelta da Intel, in quanto fa uso di fixed function per le operazioni che potrebbero portare via più cicli (la tessellation vera e propria) e ricorre all’emulazione per le altre.
Un approccio ancora diverso è proprio quello proposto da Intel con Larrabee, in cui, a questo stadio, scompaiono le fixed function che vengono sostituite da unità programmabili. Anche di Larrabee mi occuperò più in dettaglio, in quanto l’idea di far uso, il più possibile, di unità programmabili su una gpu è piuttosto interessante. Cercheremo di scoprire insieme se e quanto sarà effettivamente applicabile ed efficace.
Altro vlocco funzionale che resta dotato di fixed function è quello denominato RBE (render back end). Se per le operazioni di pixel e vertex shading è più semplice un approccio con unità di tipo programmabili, per le RBE abbiamo visto come, nel caso del MSAA di R600, la cosa può creare non pochi problemi dovuti alla scarsa efficienza dell’emulaizone SW di alcune funzioni.
Ma se nei chip ATi e nVIDIA le RBE sono rimaste di tipo fixed function, il Larrabee sono diventate anch’esse programmabili. Non approfondirò, per ora, l’argomento ma faccio solo cenno al fatto che il maggrio problema a cui sono andati incontro i tecnici INtel è stato quello di poter rendere efficiente la loro alu di tipo vettoriale presente su ogni core di Larrabee.
Se, infatti, vettorializzare pixel e vertex shader è stata un’operazione abbastanza semplice (è bastato prendere come input quad di 4×4 pixel e batch di 16 vertici), lo stesso è risultato molto complesso nel caso di operazioni che sono, per loro natura, di tipo difficilmente parallelizzabile in quanto hanno una natura intrinsecamente scalare.
Dopo vari tentativi, e dopo svariati algoritmi provati e scartati perchè troppo lenti rispetto all’hardware dedicato, alla fine gli sforzi del team messo in gioco da Intel hanno dato i suoi frutti anche se, riporto le testuali parole di uno degli sviluppatori di questo algoritmo, Michael Abrash
software rasterization will never match dedicated hardware peak performance and power efficiency for a given area of silicon, but so far it’s proven to be efficient enough. It also has a significant advantage, which is that because it uses general purpose cores, the same resources that are used for rasterization can be used for other purposes at other times, and vice-versa
Quindi, per stessa ammissione dei tecnici e degli ingeneri di Intel, la loro soluzione software non è veloce come l’hardware dedicato ma ha il vantaggio di impiegare unità riutilizzbili pep altri task. C’è da vedere quanto il compromesso scelto da Intel inciderà negativamente sulle prestazioni e quanto porterà in termini di vantaggio di spazio guadagnato sul die per permettere l’allocazione di altre unità o per contenere i consumi.
Il campo sul quale anche INtel ha dovuto arrendersi è quello delle operazioni di texturing e, in particolare, quello delle operazioni di texture sampling. Nonostante gli sforzi profusi, il miglior risultato ottenuto con l’emulazione è stato quello di essere circa 20 volte più lenti che non con hardware dedicato. Quindi anche Larrabee avrà, al suo interno, delle fixed function. Un approccio analogo hanno seguito anche nVIDIA e ATi con i loro chip di ultima generazione, in cui le operazioni di texture sampling e texture addressing sono svolte da hardware dedicato mentre quelle di blending dallo shader core.
Nelle prossime puntate di questa mini serie, approfondiremo alcuni aspetti delle architetture dei chip menzionati in questo articolo cercando, nei limiti del possibile, di scoprire quali saranno le prospettive future della grafica 3D e del GPU computing.







