A causa di alcuni importanti eventi accaduti nel corso della settimana, ho deciso di rinviare la conclusione della serie dedicata alle operazioni di texturing ad un prossimo articolo, per occuparmi, oggi, di un paio di eventi piuttosto rilevanti nel panorama informatico in generale e che riguardano, da vicino, il mondo delle gpu.
I due argomenti trattati sono arguibili dal titolo che contiene i nomi dei due chip protagonisti del post odierno. L’intenzione non è quella di scrivere un articolo di stampo tecnico, con un confronto tra le specifiche di una gpu ancora lontana dal debutto e una il cui debutto pare essere stato rinviato a data da destinarsi (Blizzard direbbe:”uscirà quando sarà pronto”). Si tratta, piuttosto, di un post in cui alternerò dati oggettivi a riflessioni personali, scrivendo le seconde in corsivo per distinguerle dai primi.
In questi mesi, sia su Larrabee che su Fermi, sono circolate tantissime voci, a volte contrastanti, sulle presunte specifiche e sulle date di presentazione e di lancio. Oggi abbiamo la certezza che Intel ha annullato l’uscita della prima serie di GPU basate su architettura di tipo terascale computing denominata Larrabee mentre nVidia ha rinviato definitivamente la presentazione dei chip basati su G100 all’anno venturo.
L’annuncio di Intel di voler rientrare nel mercato delle GPU discrete, dopo la non brillante esperienza nota col nome di i740, successiva all’acquisizione di Real3D, diede origine a molte aspettative dettate dalla curiosità di vedere come gli ingegneri dell colosso di Santa Clara avrebbero affrontato le difficoltà legate alla progettazione di un chip con architetture tanto diverse rispetto a quelle ben note, per loro, caratteristiche di una cpu.
La curiosità, fu soddisfatta, in parte, nel momento in cui Intel annunciò di voler progettare una GPU prendendo come base la ben nota architettura x86. Soddisfatta in parte, perchè quell’annuncio destò più di qualche perplessità legata soprattutto ai dubbi sul come Intel avrebbe adattato un modello che non brilla per efficienza, come quello x86 (pur con i successivi aggiustamenti), ad un paradigma architetturale come quello di una GPU. I dubbi crebbero all’annuncio che Larrabee non avrebbe implementato pipeline di tipo fixed function (ff) ma solo unità di tipo programmabile.
Questo perchè, come noto, le unità programmabili hanno il loro punto di forza nella flessibilità di adattamento, nella possibilità di svolgere tanti tipi di operazioni differenti, permettendo di concentrare la maggior potenza di calcolo, istante per istante, dove la stessa è necessaria. Ma certamente non sono veloci nell’eseguire uno specifico task rispetto ad unità di tipo ff dedicate a quel compito specifico.
Apro una brevissima parentesi per chiarire alcuni concetti: una cpu è strutturate per eseguire tante istruzioni con output di dati piuttosto basso mentre, al contrario, di una gpu si diceva che è un dispositivo capace di eseguire poche istruzioni ma di avere un data output molto elevato. Il modello SIMD è stato scelto proprio perché ad una gpu si chiede, essenzialmente, di fare tanti calcoli dello stesso tipo.
Con gli shader unificati qualcosa è, in parte, cambiata, ma solo in virtù del fatto che l’architettura interna è stata riordinata perchè si adattasse a questo nuovo modello. In questo modo, quelle che una volta erano note come unità di pixel e vertex shading sono state sostituite da un’unica unità programmabile in grado di eseguire sia operazioni geometriche che di pixel shading e queste unità sono state raggruppate in cluster e il numero di questi cluster, in breve tempo, è cresciuto notevolmente.
Ciò permette, oggi, di avere GPU in grado di esegiure molte più istruzioni di tipo differente all’interno dello stesso ciclo, che girano su differenti gruppi di alu. Inoltre è aumentato anche il numero di thread che ogni alu può gestire. Insomma, le gpu stanno evolvendo verso un modello che tende ad inglobare molte delle funzionalità tipiche delle cpu, pur continuando ad esistere, al momento, una linea di demarcazione piuttosto netta tra le due tipologie di architettura.
Mentre nel progettare una cpu si ha come obiettivo quello di minimizzare il più possibile le latenze della singola operazione, nel progettare una gpu si ha, di contro, la cerrtezza di avere a che fare con operazioni ad elevata latenza e, di conseguenza, si deve cercare di massimizzare il parallelismo interno. Questo significa che una gpu è concepita per avere una banda passante enorme verso le https://www.appuntidigitali.it/3887/grafica-una-questione-di-memoria/ e verso la vram, al fine di mascherare le latenze, inevitabili, di determinate operazioni (ad esempio quelle di texturing).
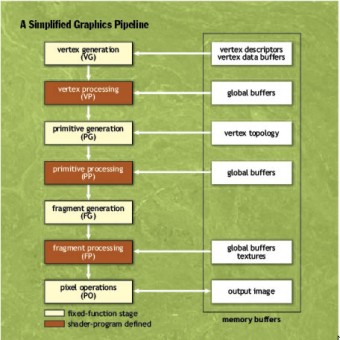
Se queste considerazioni non dovessero essere sufficienti a generare dubbi sulla possibilità di realizzare una gpu partendo dall’architettura di una cpu x86, ne aggiungo altre. Come detto, Intel ha affermato di non voler implementare unità di tipo ff all’interno di Larrabee,
posizione su cui ha, in un secondo momento, fatto parzialmente marcia indietro, dicendo che unità di tipo ff ci sarebbero state all’interno delle TMU, in quanto per le operazioni di texture sampling e texture fetching le unità programmabili impiegavano 16 cicli contro il singolo ciclo di un’unità dedicata. Anche nell’era della programmabilità, una gpu contiene, al suo interno, diversi stadi composti da unità di tipo ff alternati a stadi di unità programmabili, come mostrato in figura
questo perchè per determinate operazioni (oltre a quele relative alle texture, mi viene in mente, ad esempio la tessellation introdotta ufficialmente con le DX11, ma anche l’applicazione del MSAA box) le unità dedicate sono molto più veloci di quelle programmabili. Inoltre, le operazioni di shading presentano accessi alla memoria a granularità molto fino che possono essere gestiti solo in moaniera dinamica. Questo rende impossibile, ad esempio, la presenza di unità di prefetching all’interno degli stadi programmabili e la necessità di implementare le stesse entro le pipeline fixed function.
Una ulteriore fonte di dubbi riguarda l’adozione dell’architettura interna con ring bus; questo tipo di archietttura è di difficile ottimizzazione quando gli “utilizzatori” sono più di 4: il cell in cui bisogna fare molta attenzione alle modalità di trasferimento dati da una SPE all’altra per evitare di veder crollare le prestazioni a causa della cattiva gestione del traffico nel ring bus e l’esperienza di R600, in cui si è commesso l’errore di non dedicare un canale a parte alle operazioni non attinenti alla grafica, sono due esempi dei limiti intrinseci di un’architettura come quella ad anello. Intel ha pensato di risolvere il problema adottando la soluzione prospettata in figura
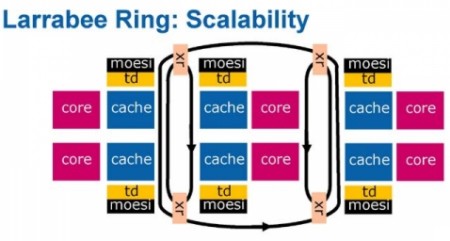
ovvero utilizando più ring bus, ciascuno dei quali serve un numero limitato di unità. Soluzione interessante che permette di superare i limiti del ring bus in “locale” ma che sposta il problema di come gestire le comunicazione attraverso un bus a come gestire le comunicazioni, qualora si rendesse necessario, tra più anelli.
Non mi dilungherò su aspetti inerenti l’architettura di Larrabee, poichè, come detto, questo è un post in cui mi sono ripromesso di partire da alcuni dati per fare delle consoderazioni personali sia sulla decisione di Intel di annullare la prima serie di gpu basate su questa architettura, sia sul ritardo, ormai ufficializzato, delle soluizoni basate su G100 di nVidia. Quindi i riferimenti fatti all’architettura di Larrabee sono funzionali non a farne un’analisi ma a specificare i motivi di perplessità su questo chip.
A tutto ciò, si aggiunge che, secondo le intenzioni di Intel, ogni core di Larrabee dovrebbe essere in grado, per ogni ciclo di clock, di eseguire due istruzioni e gestire fino a 4 thread in modalità in order. Ora, sappiamo che le attuali gpu sono in grado di gestire centinaia di thread per core, al fine di mascherare le latenze. Per quanto Larrabee possa essere ottimizzato per ridurre al minimo le latenze, nell’ambito delle elaborazioni tipiche di una gpu ci sono operazioni che, per forza di cose, presentano latenze elevate. Insomma, Larrabee non appare molto in grado di mascherare le latenze facendo ricorso al multithreading. Quindi deve essere strutturato in maniera tale da non avere operazioni che comportino latenze elevate (impresa difficile per una GPU).
Ultima fonte di dubbi era quella relativa al processo produttivo adottao; si è parlato di 45 nm mentre sappiamo che ATi è già passata ai 40 e nVidia lo ha fatto almeno con le gpu di fascia bassa. Questo, sommato alla voce che avrebbe voluto all’interno di Larrabee, almeno 16 o 32 core, avrebbero determinato un die di dimensioni enormi sia rispetto alla concorrenza che in assoluto.
Ciò nonostante, eravamo (e siamo ancora) in molti a pensare che Intel possa riuscire nell’impresa di realizzare una GPU competitiva nelle fasce media e alta del mercato, prima o poi. Certo, l’annuncio del mancato lancio di questa prima serie fa slittare l’ingresso questo ingresso, annunciato forse con un po’ troppo clamore, e rischia di dirottare, momentaneamente, questa archietttura, verso altri tipi di impiego in cui potrebbe, grazie alle 16 unità vettoriali per core, eccellere e mi riferisco, in particolare, al GPGPU. In questo campo, potrebbe entrare in diretta competizione con Fermi.
Già, Fermi………………….. Della nuova architettura di nVidia si sà, praticamente, quasi tutto; peccato che tra le poche cose ancora non rivelate ci siano quelle che sono di maggior interesse per le applicazioni 3D come, ad esmepio, la presenza di unità dedicate all’e operazioni di tessellation o le frequenze di funzionamento delle Geforce basate su G100.
La motivazione ufficiale è stata che, finora, è stata presentata solo la versione Tesla, dedicata al GPU compunting. C’è altresì da aggiungere che, per quanto visto finora, l’archietttura denominata Fermi pare molto orientata al GPU computing. L’adozione di pipeline di tipo FMA (le alu di G80 e quelle di tipo single precision di GT200 sono delle MADD), l’implementazione, per la prima volta su chip grafici nVidia, di cache vere e proprie (quelle presenti nei chip, fino a GT200 erano delle texture cache, mentre AMD è da RV770 che fa uso di cache di secondo livello di tipo cpu-like)
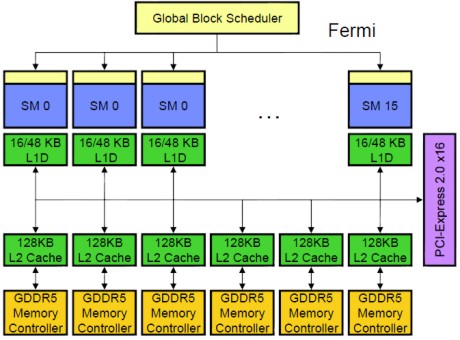
La cache L2 serve, tra le altre cose, per accelerare le atomic operation permettendo lo scambio di dati tra cluster on chip, mentre in precedenza, l’unico spazio di memoria visibile ed accessibile a tutti, era la global memory all’interno della vram. Un altro aspetto che fa somigliare Fermi molto più ad una cpu rispetto alle rpecedenti architetture nVidia è l’esecuzione condizionale delle istruzioni, gestita con un approccio che ricorda quello adottato sulle CPU ARM (per l’approfondimento delle quali rimando agli ottimi articoli di Cesare Di Mauro), per ridurre il rischio di stallo dovuto a predicazione sbagliata. Questo senza tener conto della miglior attitudine al thread switching ottenuta grazie all’adozione del DUAL WARP SCHEDULER
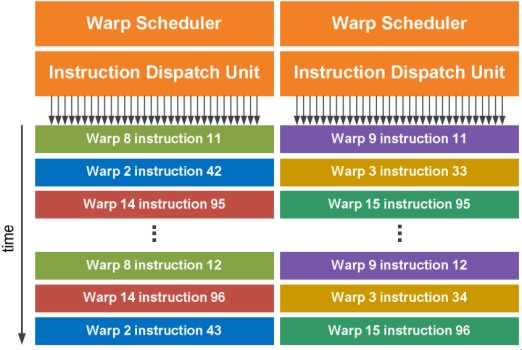
e delle due instruction dispatch unit che, raddoppiando di fatto, le medesime unità per cluster presenti su GT200, permette di operare su due thread in parallelo, uno per ogni gruppo di 16 alu, riducendo di un fattore di 10x la velocità di commutazione tra thread e la granularità degli stessi rispetto a GT200.
Fermi, contrariamente a GT200, ha anche una elevata capacità di calcolo in doppia precisione, ottenuta accoppiando due alu a 32 bit. Nettamente differente, rispetto al passato, anche l’organizzazione delle alu di Fermi
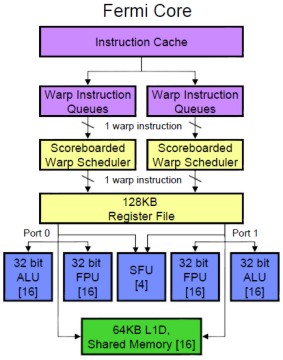
messe a confronto con quelle di GT200
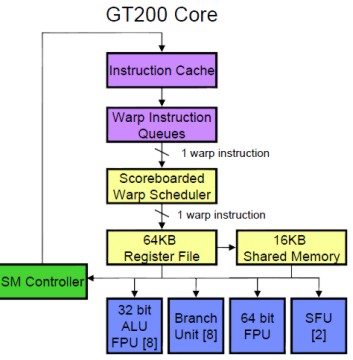
Come si vede, la zeconda appare “incompleta”, mancando, come si è detto, di una cache interna in cui immazzinare i dati comuni; in Fermi, al contrario, c’è una cache di 1° lvello dedicata ad ogni cluster ed una di 2° livello comune a tuti i cluster. Inoltre, in GT200 si vede l’alu dedicata ai calcoli di tipo fp64 che in Fermi non c’è (si accoppiano due alu fp32). Infine, come detto, in Fermi sono stati raddoppiati sia la warp instruction queue che il warp scheduler.
Fin qui tutto molto interessante, ma anche tutto molto votato al GPGPU; ad esempio, come detto, non si hanno informazioni sull’implementazione del tessellator, sull’architettura e l’efficienza delle ROP’s o delle TMU (di cui si sa solo che le operazioni di texture blending saranno affidate allo shader core, come del resto fa anche RV870); né si conoscono le frequenze di funzionamento dei chip della famiglia Geforce. Inoltre, l’architettura delle alu vista sopra ha qualche limite, dovuto al fatto che ci sono delle risorse (registri in particolare) condivise tra le unità funzionali del chip. Per cui, ad esempio, un cluster esegue 32 operazioni fp32, o altrettante INT, oppure 4 SF ops o 16 fp64.
Se, quindi, G80 non era, di fatto, un chip votato al gpgpu e GT200 lo era solo parzialmente e con un supporto “posticcio”, G100 nasce come chip con un a spiccata vocazione al GPU computing e quanto rivelato finora lascia intendere che questo sia stato uno degli obiettiivi primari dei tecnici nVidia, se non addirittura il principale.
Non approfondisco ulteriormente il discorso di G100 per lo stesso motivo per cui non ho approfondito quello su Larrabee. Avremo modo di tornare sull’analisi delle architetture dei due chip per parlarne in maniera più diffusa. Queste motizie in “pillole” costituiscono solo lo spunto per alcune riflesisoni personali.
Partendo da Larrabee, tutte le perplessità espresse nella prima parte inducono a riflettere sull’approccio scelto da Intel, diamentralmente opposto a quello di nVidia: si è partiti da una CPU per arrivare a progettare una GPU. Quanto sia funzionale ed efficace questo tipo di approccio, al momento non ci è dato di sapere; di certo Intel ha incontrato grandi ostacoli che l’hanno convinta o costretta, per il momento, a defilarsi. Questo non vuol dire che in futuro non avremo una GPU basat sul progetto Larrabbe ma, semplicemente, che non l’avremo nel futuro prossimo. IMHO, Intel dovrà rivedere in parte i suoi piani relativi ad una GPU interamente programmabile. Al momento non c’è alcun vantaggio di tipo prestazionale a non implementare unità di tipo ff in alcuni blocchi funzionali di un processore grafico. Certo, un chip siffatto costituirebbe una piattaforma facilemnte aggiornabile al variare delle API di riferimento, ma questo vantaggio sarebbe bilanciato, in negativo, da un hit prestazionale molto elevato in determinati ambiti e con alcuni tipi di calcolo in particolare. Quando sentii parlare per la prima volta di Larrabee e ne lessi le specifiche, ebbi l’impressione di un chip molto votato al GPGPU ma che avrebbe avuto seri problemi ad imporsi come GPU di fascia alta. Oggi resto della setssa idea e vedo Larrabee più come un concorrente di Fermi in ambito GPGPU che come un terzo incomodo nel mercato delle GPU high end.
Dal canto sua, nVidia sta spingendo da tempo sul GPGPU. Dal momento in cui si è capito che si andava verso una convergenza CPU-GPU e verso la possibile integrazione di funzionalità tipiche delle cpu all’interno delle gpu, nVidia ha compreso l’importanza di avere un chip che fosse punto di riferimento in quest’ambito. Sicuramente si tratta di una nicchia, ma di una nicchia di importanza strategica vitale per chi non ha la possibilità di realizzare una piattaforma integrata cpu-gpu, contrariamente ai suoi due maggiori competitor (uno atuale l’altro in prospettiva futura). Lo strumento glilo hanno fornito le architetture a shader unificati, molto più programmabili e flessibili delle precedenti. Certo, le prime generazioni, quelle basate su G80, sono servite solo da apripista per la generazione di chip successiva che dovrebbe avere Fermi come punto di partenza.
E’ certo che, però, anche nVidia sta incontrando non poche difficoltà nella realizzazione del suo chip. Con G80 ha scelto la strada dell’architetura superscalare, il che comporta “chipponi” grandi, compkessi, con molto spazio occupato dai circuiti di controllo e poca possibilità di introdurre unità ridondanti per aumentare le rese (un cluster di 32 alu di G100 occupa, con “annessi e connessi”, almeno il doppio dello spazio di uno da 80 alu di RV870). Questo, con un chip di 3 miliardi di transistor, crea non pochi problemi a livello di progettazione e di ottimizzazione e, sull’onda dei problemi incontrati da TSMC con il porcesso a 40 nm, di cui si era a conoscenza da un pezzo, sta rendendo la realizzazione del chip e la sua commercializzazione ancora più complicata.
Con questo non intendo dire che il ritardo di Fermi sia colpa di TSMC. I problemi della fonderia taiwanese erano noti e derivano dal fatto che il processo a 40 nm non può considerarsi un mero shrink ottico di quello a 45 adottato da TSMC per dispositivi a basse prestazioni. Si tratta di un vero e proprio full node rispetto ai 55 nm adottati in precedenza per le gpu di ATi e nVidia. Questo lo si sapeva già diversi mesi prima che si iniziasse la sperimentazione sui 40 nm e qualche alto papavero di TSMC aveva minimizzato il problema.
In realtà, però, le difficoltà per TSMC, che stanno facendo andare a rilento anche le vendite delle GPU a 40 nm di ATi, rappresentano, a mio giudizio, solo una parte dei problemi incontrati da nVidia. Quella che lascia pensar male è la continua serie di maldestri tentativi di ricordare che deve uscire un chip DX11 compliant targato Santa Clara. “Maldestri” è l’unico termine che mi viene per definire una presentazione con una scheda video fake, fatta in un periodo in cui era lecito nutrire ragionevoli dubbi sull’esistenza di una piattaforma con Fermi funzionante, come pure un po’ di foto, lasciate “negligentemente sul comodino”, ovvero buttate qua e là in rete (fecebook, qualche forum, ma nulla di ufficiale) in cui si ritrare Fermi in azione.
Altra cosa che lascia perplessi è che sulla versione Tesla si sa pressochè tutto, comprese le frequenze e le prestazioni in rapporto a GT200 (ma il confronto, soprattutto in fp64, è impietoso) mentre della versione Geforce non si sa nulla neppure in rapporto allo stesso GT200. Come pure è sospetto che abbiano rilasciato le specifiche architetturali con dovizia di particolari, ma senza entrare nel merito di quelle feature che riguardano il gaming. Eppure non c’è rimasto nulla da tenere nascosto: ATi ha svelato le sue carte da un pezzo, rispettando, almeno stavolta, la roadmap; Intel sarà per un pezzo fuori dai giochi e sicuramente salterà questa e almeno un altro paio di generazioni. La domanda che mi pongo è: cosa c’è da tenere nascosto e a chi?
Le probabili risposte sono tante; una potrebbe essere che Fermi non è, nei giochi, così veloce come ci si aspetti che sia (questo non vuol dire meno veloce di RV870 ma potrebbe anche voler dire troppo poco più veloce). In tal caso ha senso non svelare le frequenze di funzionamento perchè, magari, si possono ancora incrementare le prestazioni lavorando su di esse. Una cosa analoga successe ai tempi di NV30 ma allora furono diffuse le specifiche, frequenze comprese, che risultarono modificate al momento del lancio del chip.
Un’altra spiegazione potrebbe essere che nVidia non voglia fare un paper launch con pochi esemplari funzionanti, facendo poi attendere mesi e la maturazione del pp a 40 nm per effettuare il vero lancio. Ma allora perchè continuare a bombardare il web con notizie e foto relative a Fermi? Ormai, immagino, tutti sapranno che deve uscire un chip grafico con quel nome in codice e con quelle caratteristiche architetturali.
Altra spiegazione è che, ad oggi, non esistono ancora prototipi funzionanti di Fermi e, in tal caso, la cola non è affatto imputabile ai problemi di TSMC ma a qualche bug non ancora individuato a causa dell’elevata complessità del chip.
Tra queste, al motivazione più debole mi sembra quella del paper launch; in fondo se si vuole limitare le vendite dei competitor (e qui parlo in linea generale e non con stretto riferimento ai chip grafici) non ci si limita a dire “stiamo arrivando” ma, se si ha la possibilità, si mostra anche ciò che si è in grado di fare, se questo può dissuadere gli acquireti a rivolgersi altrove; nVidia una cosa del genere la fece con la 7800 GTX 512 MB, prodotta in pochissimi esemplari, da chip selezionatissimi, con voltaggi e frequenze fuori specifica, per togliere lo scettro prestazionale a R520. Subito dopo le feste natalizie, nVidia lancio la 7900 GTX con pp inferiore e stesse frequenze della 7800 phantom edition. In quel caso, però, il mostrare le prestazioni unito alla promessa “stiamo arrivando” ebbe una certa efficacia a livello di immagine. In questo caso, IMHO, nVidia più che non volere, al momento, non può mostrare le potenzialità di Fermi.
I portagonisti di questo articolo sono dunque due chip che stanno vivendo storie piuttosto travagliate; ma se da un lato abbiamo un chip molto interessante e, sulla carta, estremamente innovativo (forse troppo) che, per ora, non vedrà la luce (ne si sa come e quando sarà commercializzato), dall’altra abbiamo un altro chip altrettanto interessante, magari meno innovativo per il settore, se visto in ottica GPU (Fermi ha, comunque, l’architettura di una GPU), ma che sicuramente uscirà e, stando alle specifiche su carta, dovrebbe rivelarsi un prodotto competitivo. Certo, nVidia dovrà cercare di stringere i tempi, non tanto per un discorso di vendite, quanto per il fatto che dopo aver, a costo di notevoli sacrifici, annullato il gap che la divideva da AMD sui processi produttivi adottati, il ritardo di Fermi rischia di riconsegnare ad AMd un certo margine di vantaggio, dato che ora può, contestualmente all’affinamneto dei 40 nm, iniziare a lavorare, in tutta tranquillità, sui 32 e sui 28 (o direttamente su questi ultimi), potendo contare anche su Global Foundry.







