
Questa settimana metterò, temporaneamente, da parte la trattazione sulle texture, per parlare, di un’altra delle unità funzionali di un chip in generale e di una gpu in particolare. Dopo aver fatto cenno al memory controller, voglio infatti introdurre quelle che sono le unità deputate ad eseguire le istruzioni id tipi matematico. Beh, detta così è un po’ troppo generica; si potrebbe obiettare che tutte le operazioni interne ad un chip hanno a che fare con la matematica. Ok, andiamo un po’ più nello specifico: mi riferisco a quelle unità che sono definite, di volta, in volta, alu (arithmetic logic unit), fpu (floating point unit) o, persino, vertex e pixel shader avendo impropriamente mutuato il nome dalle istruzioni che sono preposte ad elaborare. Ormai, con i chip a shader unificati, non ha più senso fare la distinzione tra le differenti tipologie ma questo, da un punto di vista concettuale, non inficia l’attendibilità del post odierno.
Certo non mi dilungherò a parlare di quante e quali operazioni siano possibili su un’unità di tipo logico-matematica ma mi soffermerò su quella che, nelle elaborazioni grafica, è la più comune: ovvero la cosiddetta MADD o MAD che dir si voglia, che è la contrazione di multiply-add, ossia un’istruzione che prevede l’esecuzione di una moltiplicazione seguita da un’addizione.
Ovviamente non l’unica tipologia di istruzioni che un’unità matematica può eseguire e, neppure, si tratta dell’unico tipo di unità presente all’interno di un chip. Si tratta, però, dell’unità più comune in quanto più usata, tanto che, ad esempio, la potenza teorica di un chip ancora più che in flops al secondo si misura in madd al secondo.
Prima, erò di iniziare a trattare le unità matematiche, facciamo un breve riassunto su come funzioni un computer in generale e un’alu in particolare (non me ne vogliate se nel prosiequo la definorò spesso, magari in maniera riduttiva, così).
Immagino che quelli che, consapevolmente, scelgono un blog come Appunti Digitali e, in particolare, questa rubrica (pur sapendo cosa li aspetta) siano perfettamente a conoscenza del funzionamento di un pc o di un processore grafico o meno o, nella peggiore delle ipotesi, siamo perfettamente a conoscenza della loro esistenza (qua ci vorrebbe una faccina che non ho a disposizione). Per i pochi che capitano per caso da queste parti, magari seguendo qualche tag di un qualche post di Alessio, nella speranza di trovare foto della Marcuzzi o della Canalis senza veli, cerco di fare un sunto dei concetti di base aiutandomi con delle immagini.
Iniziamo col dire che un processore in genere e una alu in particolare, sono dispositivi in cui, ad un flusso di dati e uno di istruzioni in ingresso, corrisponde un flusso di dati in uscita, secondo lo schema riportato in basso
Lo schema è abbastanza semplice (pure troppo): da una parte entrano le istruzioni e dall’altra i relativi dati e, in uscita, abbiamo il prodotto “finito”. Questo schema è molto generico e vale per qualunque sistema d’elaborazione dati. Quindi se, per esempio, entra un’istruzione di tipo ADD (un’addizione) riferita ai numeri 3 e 5, allora il risultato finale sarà 8. Adesso proviamo ad aggiungere qualche particolare. Potremmo iniziare ipotizzando che istruzioni e dati siano inizialmente posti all’interno di un contenitore, di cui occuapno spazi separati; questo contenitore è costituito da una qualunque periferica di memorizzazione; tra tutte è preferibile usare, per quastione di velocità di accesso, la ram (video o di sistema). In questo modo, il nostro schema si trasforma nel modo seguente
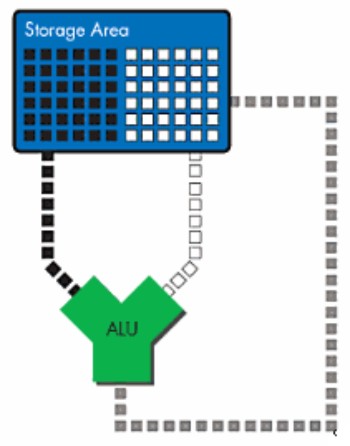
Come si vede, le istruzioni arrivano dall’area occupata da quadratini neri, mentre i dati da quella bianca; i risultati tornano indietro all’interno della ram in forma di dati e possono essere messi a disposizione per una nuova elaborazione oppure finire in una nuova area che li immagazzina per inviarli ad un altro utilizzatore; poichè questa rubrica si occupa prevalentemnete di chip grafici, questo utilizzatore è il monitor e la nuova area di “stoccaggio” è il cosiddetto frame buffer.
A questo punto sorge un prolema; dallo schema appare evidente che per eseguire, ad esmepio, l’addizione di cui sopra, si devono prelevare dalla memoriua centrale prima il 3 e poi il 5. Due accessi alla memoria centrale, però, hanno dei tempi di attesa piuttosto lunghi. La soluzione è quella di creare una memoria all’interno del chip, che sia direttamente connessa alle sue unità funzionali. In questo modo, il 3 e il 5 sono già contenuti all’interno di questa memoria il cui accesso è molto più veloce. Ma la stessa cosa si può fare per le istruzioni, in modo tale da creare una coda di istruzioni da eseguire che l’alu può prelevare seguendo un determinato ordine. Lo schema diventa quello seguente
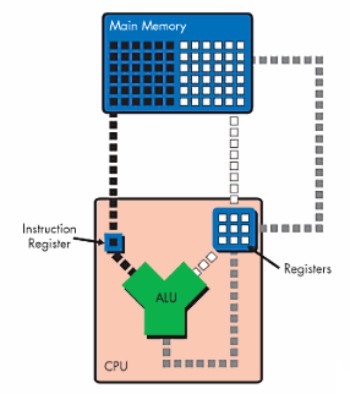
Come si vede, all’interno del chip c’è un’instruction register che carica parte delle istruzioni ocntenute nella ram e un omologo registro che fa la stessa operazione con i dati. In questo modo, la alu ha a disposizione una serie di istruzioni, ocn i relativi dati, da elaborare prima di dover di nuovo accedere alla ram di sistema. Per rendere il tutto più efficiente, si può far gestire questo insieme di dispositivi da un thread processor che, ricevendo dei feedback dalla alu sulle elaborazioni eseguite, decide quali altre istruzioni (e dati) caricare all’interno dei registri della alu, facendo in modo che gli stessi non arrivino a svuotarsi praticamente mai. Dallo schema si vede anche che i dati risultanti dall’elaborazione dell’alu sono inviati nuovamente al set di registri della stessa alu in modo da poter essere disponibili ad una nuova elaborazione senza che si faccia nuovamente accesso alla ram. Nello specifico, occorre distinguere due set distinti di registri: quelli temporanei (che si indicano, solitamente con R, e quello di output). Quando un dato deve essere rimesso a disposizione della stessa o di un’altra unità di calcolo, viene caricato in un registro temporaneo; quando invece è destinato ad essere inviato al frame buffer in un registro di output. Invece, i dati che sono caricati all’inizio dell’elaborazione direttamente dalla ram, finiscono nei cosiddetti registri costanti, indicati con C.
Così, ad esempio, l’istruzione di sommare i numeri 3 e 5 caricati nei registri C0 e C1 e di inserire il risultato nel registro temporaneo R0, si può riassumere con
ADD R0; C0, C1
Lo schema tipico fetch, decode, execute, wrute back è rinvenibile nella precedente immagine dove l’operazione di instruction fetch è quella che fa caricare l’istruzione dalla vram all’interno dell’instruction register, quella di decode avviene all’interno dello stesso registro, quindi si avvia l’esecuzione e, infine, la scrittura dei dati all’interno di un nuovo registro (di output o temporaneo).
Una schematizzazione un po’ più complessa dell’alu in oggetto può essere la seguente
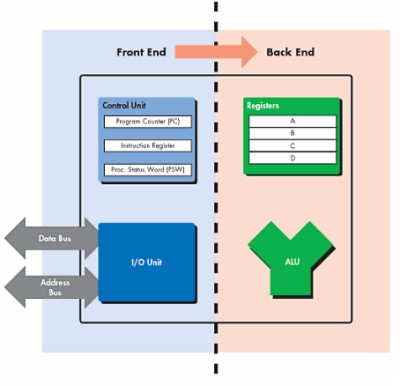
Nella figura sono divise le due sezioni che si occupano di elaborare le istruzioni e di eseguire le stesse; la prima delle due ha un’unità centrale che si occupa di tenere sotto controllo ciò avviene a livello di instruction register, ossia di registri contenenti le istruzioni, contandone il numero, inviando all’unità centrale della cpu le informazioni su ciò che è stato elaborato e su ciò che si sta elaborando; si occupa di inoltrare le richieste di accesso alle risorse condivise del sistema dopo aver ricevuto dall’unità centrale gli indirizzi di memoria in cui andare a reperire istruzioni e dati per le successive elaborazioni, ecc. In parole povere, il front end si occupa del fetch and decode. Dall’altra parte, si ha la sezione che si occupa della semplice esecuzione delle istruzioni, ossia la vera e propria alu con i suoi buffer di registri che si occupa dell’execute e del write. All’interno di una alu, i buffer sono di tipo FIFO, ossia viene eseguita la prima delle istruzioni in coda e si segue l’ordine fino all’ultima della fila. Al contrario, il thread processor, che funge da unità centrale della gpu, gestisce le istruzioni in modalità Out of Order; questo significa che, a seconda delle informazioni ricevute dalle varie alu, decide in che modo riordinare le istruzioni contenute nei suoi buffer e in che ordine inviarle alle sigole alu. Anche il memory controller che si occupa di smistare le richieste di accesso alle risorse condivise, gestisce i suoi buffer in modalità Out of Order, privilegiando alcune operazioni rispetto ad altre.
Finora abbiamo supposto che la nostra alu sia in grado di eseguire un’addizione; cosa molto semplice (apparentemente), la cui esecuzione, si potrebbe pensare, richieda pochi cicli di clock. Ops, ho detto pochi? Ma come fa un semplice ADDER a impiegare pochi cicli di clock quando sappiamo, per definizione, che un’alu di tipo MADD è in grado di eseguire una moltiplicazione ed una somma in un solo ciclo? Sfatiamo il primo mito: una MADD non è eseguita in un singolo ciclo (non lo è neppure una ADD e tanto meno una MUL). Per darvi una vaga idea della complessità di un ADDER fp32 vi posto un’immagine che mi dispenso dal commentare, aggiungendo solo che si tratta di un adder con un cosiddetto residual register che serve a contenere il residuo del troncamento successivo all’operazione di addizione che viene adoperato al fine di minimizzare gli errori.
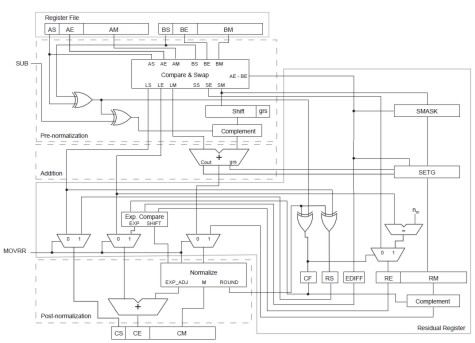
Vi basti sapere che, ad ognuno degli stadi indicati in figura corrisponde almeno un ciclo di clock. Il vantaggio è che si possono eseguire più elaborazioni in serie; quindi se abbimao, ad esempi, più addizioni da eseguire, a condizione che siano indipendenti tra di loro, una volta avviata la prima e prima ancora che l’alu abbia terminato il suo lavoro, possiamo pensare di avviare la seconda e così via, riuscendo, in tal modo a mascherare le latenze di un’operazione che, altrimenti, richiederebbe un bel po’ di cicli (da 5 a 7).
Ora abbiamo fatto conoscenza con un ADDER ma a noi questo serve a poco visto che, all’inizio, si è detto che le operazioni più usate sono le MADD. A questo punto, le cose sembrano complicarsi leggermente. Ok, l’instruction buffer ocnterrà una MADD invece di una semplice ADD e i registri coinvolti saranno un po’ di più dei tre indicati sopra: uno per ognuno dei 3 dati coinvolti nell’operazione più almeno un altro per immagazzinare il risultato finale. In realtà vedremo che le cose non stanno esattamente così ma procediamo con ordine.
Siamo, dunque, arrivati alla nostra MADD. Abbiamo la solita istruzione che ci dice che l’alu deve moltiplicare i dati contenuti in due registri costanti; fin qui tutto bene. La nostra alu, però, non è detto che operi con numeri interi. Anzi, ad essere pignoli, le alu dei nostri chip grafici è dalle DX9 che non operano più solo con interi. Cosa succede quando moltiplico due numeri rappresentati in virgola mobile? La prima cosa che viene in mente è che, se eseguo calcoli, ad esempio, a fp64, il risultato non sarà un numero a 64 bit in virgola mobile. In effetti, con dati che hanno una precisione pari a n, una moltiplicazione fornisce un risultato a 2n bit. A questo punto, ho un addendo a 2n ed uno a n bit e due possibili scelte. La prima è che effettuo un’operazione di troncamento del primo addendo eliminando i bit ridondanti a cui fa seguito un’addizione, la seconda è che effettuo un allineamento dei due operandi (servirà un aligner con almeno 2n+n+2 bit), quindi un’addizione senza troncamento e, infine, un’arrotondamento del risultato finale. La prima delle due opzioni, roportata nella segunete immagine, è la classica MADD
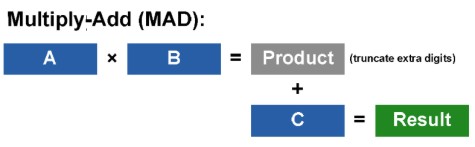
la seconda è detta FMA (fused multiply-add) ed è riportata qui in basso
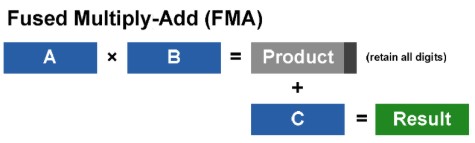
La prima è la classica MADD, l’operazione più usata dai chip grafici, soprattutto nella sua versione a 32 bit in floating point, mentre la seconda è stata sviluppata per i calcoli di tipo generl purpose, soprattutto dove è richiesta una notevole precisione; infatti la sua variante più comune implementata nelle cpu, è quella a fp64. Con l’adozione dello standard IEEE 754-2008, però, le FMA sono entrate a far parte anche del mondo della grafica 3D e, a partire dalla generazione DX11, tuti i chip grafici saranno in grado di effettuare, olttre alle MADD, anche FMA a fp32 ed fp64; per la verità anche GT200 di nVidia che ha dato vita alla famiglia di chip della serie 2×0, dalla 260 GTX in su (gli altri fanno parte della famiglia di derivati da G80), può eseguire FMA a fp64 anche se a velocità ridottissima, grazie all’adozione di alu dedicate ai calcoli a 64 bit in floating point ma in quantità estremamente ridotta.
Uno dei metodi per implementare le operazioni di MUL, ADD, MADD e FMA è quello di utilizzare una pipeline di tipo FMA classica, come quella indicata in figura.
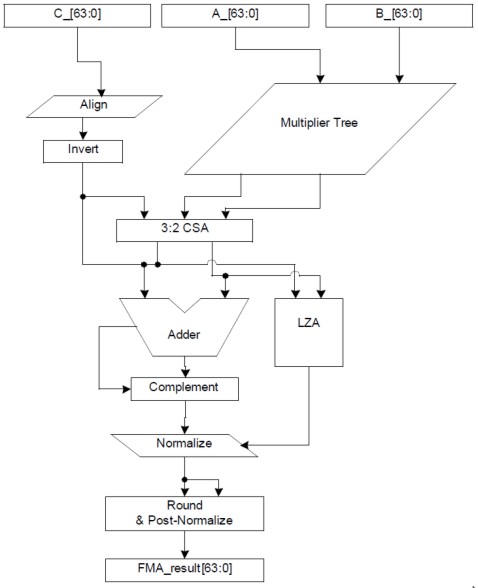
Si noti che ho parlato espressamente di pipeline anche se si tratta di una singola alu, perchè la sua architettura è di tipo pipelined e, proprio grazie a questa, è possibile gestire più operazioni in simultanea e mascherare le latenze della singola operazione. Nello schema si vedono chiaramente l’adder e il multiplier, con in parallelo all’adder un blocco denominato LZA (leading zero anticipation) un circuito, dotato di algoritmo di tipo predittivo, in grado di individuare i bit più significativi dei due addendi per favorire le successive operazioni di normalizzazione; il blocco indicato come CSA 3:2 è un combiner a 2n+m bit con m almeno uguale a 2.
Questo tipo di soluzione permette un certo risparmio in termini di transistor e di spazio sul die, ma presenta un paio di inconvenienti: in caso di esecuzione di una semplice add o mul, i dati devono comunque transitare attraverso tuti gli stadi, anche quelli non funzionali all’esecuzione dell’istruzione. Inoltre, l’assenza del troncamento del risultato della moltiplicazione, fa si che una istruzione di tipo MADD richiede 2 passate per la completa esecuzione poichè si deve eseguire prima una MUl con arrotondamento finale per cui si usa il blocco a valle dell’adder e poi un’ADD con ulteriore arrotondamento (fatto sfruttando una seconda volta lo stesso blocco). Il risultato finale è che la potenza di calcolo teorica nell’esecuzione delle MADD è dimezzata rispetto a quella delle FMA. A questo punto voglio sfatare un altro mito, osisa quello dei 4 registri utilizzati per la MADD; in realtà, oltre ai tre registri costanti in cui sono caricati i due operandi utilizzati nella moltiplicazione ed uno dei due addendi, ed oltre al registro di output (o quello temporaneo) in cui è immagazzinato il risultato finale, si utilizza un altro registro temporaneo a valle della moltiplicazione, per permettere la perfetta sincronizzazione delle due operazioni, Allo stesso modo, si utilizzano registri temporanei anche tra alu in cascata tra di loro per il medesimo motivo.
Questa sembrerebbe essere la soluzione scelta da nVidia per Fermi che sarà dotato di 512 alu di questo tipo.
Un’alternativa prevede uno schema analogo con a monte del combiner un circuito che operi il troncamento del risultato della moltiplicazione. In questo caso una MADD richiede un solo ciclo, ma resta l’inconveniente che MUL e ADD richiedono il transito attraverso tutto il circuito.
Una terza via è quella proposta nella seguente figura
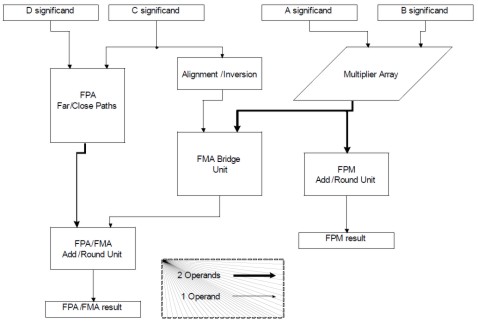
Come si può vedere, questo è un circuito che può eseguire una MUl o una ADD indipendentemente l’una dall’altra e, in ciascuno dei due casi, i dati attraversano solo gli stadi che sono interessati dall’elaborazione; in caso di FMA, il BRIDGE posto al centro dello schema pensa a raccordare l’operazione di MUL senza troncamento con la ADD; per le MADD si deve ricorrere, comunque, a due passate. Questo schema è quello utilizzato nelle cpu AMD per i calcoli fp64 a partire dai core della famiglia Barcelona. Esiste una sua variante che prevede una ulteriore linea di flusso che unisce il blocco indicato come FPM add/round unit a valle del multiplier, che si occupa del troncamento del risultato della moltioplicazione, con il bridge e che permette l’esecuzione di MADD in single pass ed è stato utilizzato su RV870. Questo tipo di soluzione ha il vantaggio di permettere l’esecuzione di tutte le operazioni previste in single pass, presenta una maggior efficienza nell’esecuzione di MUL e ADD (ha latenze inferiori) ma ha latenze leggermente superiori nell’esecuzione delle fused multiply-add rispetto ad una pipeline FMA classica.
Con questo chiudiamo questa parentesi sulle alu, doverosa per una serie di motivi: innanzitutto perchè le operazioni descritte sono, praticamente, la base di tutot ciò che avviene all’interno di una gpu; in secondo luogo, l’argomento mi è stato ispirato dalle discussioni di questi giorni sulla capacità di calcolo vera o presunta dei nuovi chip DX11 usciti e di prossima uscita. Nell’ambito di questa trattazione si è parlato soprattutto dell’architettura delle unità di calcolo vere e proprie e di alcune delle loro funzionalità principali, ma si è trascurata, ad esempio, la modalità con cui esse si interfacciano con i vari livelli id memoria interna ed esterna; o meglio, qualcosa si è visto e detto all’inizio, ma non si è approfondito più di tanto e questo, probabilmente, non ha permesso di cogliere, se non in minima parte, la complessità di una struttura come quella di una alu, che interagisce con migliaia di registri di diverso tipo e elabora decine di istruzioni in simultanea.







