Nelle scorse settimane abbiamo avuto modo di parlare di come sia iniziata questa lotta tra ATi e nVidia per la supremazia in ambito 3D e, in particolare, in ambito gaming. Abbiamo visto come una piccola società sia stata in grado, in pochi anni e grazie a scelte progettuali e di mercato azzeccate, a diventare un colosso in grado di spodestare realtà affermate come 3dfx per le prestazioni ed S3 per la diffusione dei propri chip grafici.. Abbiamo anche visto come, nel corso degli anni, ad arginare l’ascesa apparentemente, almeno nelle sue fasi iniziali, irresistibile di nVidia, sia rimasta una sola realtà capace, sia a livello di risorse economiche che di know how, di contrastare efficacemente la casa di Santa Clara. Abbiamo, infine, visto, come, nel periodo a cavallo tra il 1998 ed il 2005, ATi e nVidia si siano ripetutamente superate, tirando fuori a turno, prodotti superiori, tecnologicamente o prestazionalmente, a quelli della concorrenza.
Abbiamo visto come spesso ATi abbia puntato su architetture più raffinate; mi viene da pensare all’adozione di sistemi di HSR già con la prima Radeon, oppure alla compatibilità di R200 con lo SM1.4 mentre i chip delle serie NV2x supportavano solo lo SM1.3, il ring bus per ottimizzare i trasferimenti di dati da e evrso la ram video e il lavoro del memory controller, o l’utilizzo di texture cache di tipo fully associative, dynamic branching a granularità fine e molto più efficiente, ecc, mentre nVidia abbia puntato, più spesso, ad un approccio di tipo “brute force” con elevato parallelismo, gran numero di pipeline, di unità di calcolo e, soprattutto, di texture unit, ROP’s in grado di raddoppiare prima e quadruplicare, con i chip più recenti, il pixel fillrate con le sole z-ops, e via dicendo.
Una cosa in comune, però, i due contendenti l’avevano sempre mantenuta, ossia la ricerca delle prestazioni assolute, anche a costo di progettare chip molto grandi e costosi. In effetti, se andiamo ad analizzare le caratteristiche delle varie generazioni di chip progettati da ATi e nVidia, notiamo che, ad esempio, a livello di transistor count non c’è mai stata una grande differenza e così pure a livello di complessità architetturale e di die size.
Con la prima generazione DX10, però, le strade iniziano a divergere. Inizialmente la cosa non si nota perchè, in effetti, tra i 681 mln di transistor per un die size di 484 mm^2 a 90 nm ed i 720 mln di transistor di R600 con i 420 mm^2 a 80 nm, non sembra esserci una gran differenza. Con la fine della generazione DX9, ATi aveva recuperato il gap di un processo produttivo e, anzi, si era avvantaggiata di un half node (gli 80 nm rispetto ai 90 sono solo uno shrink ottico) e questo ha permesso ai canadesi di guadagnare qualche mm^2 sulle dimensioni del die. Sia R600 che G80, per motivi diversi, sono chip molto complessi: il primo presenta un ring bus a 512 bit per la gestione degli accessi alla ram, per tutte le operazioni gestite dal chip e non solo per quelle inerenti la grafica. Inoltre, il chip ATi ha un totale di 64 unità di calcolo di tipo VLIW con issue width pari a 5. Dall’altra parte, il chip nVidia, pur con molte meno alu (“solo” 128) ha un’architettura di tipo superscalare che rende i circuiti dedicati al gestione e controllo dei thread molto più complessi ed articolati. Il risultato è: due chip molto simili per complessità architetturale anche se molto differenti per “filosofia progettuale”.
Per un primo commento sulle differenze architetturali, vi rimando all’ultima parte di questo articolo, mentre i questa sede voglio semplicemente soffermarmi sulle conseguenza delle scelte adottate da ATi e nVidia e approfitterò, anche, per fare qualche considerazione sul passaggio dalle architetture a shader dedicati a quelle di tipo unified.
Con G80, nVidia abbandona, almeno in parte e relativamente alle unità di shading, l’approccio “brute force”. I chip della serie 8, infatti, sono caratterizzati da un basso numero di alu inserite in un’architettira estremamente efficiente. Facciamo un veloce paragone con l’architettura di G70, in cui sono presenti 24 pixel pipeline e 8 vertex pipeline, tutte dotate di unità vettoriali 4+1 in grado di eseguire operazioni di tipo MADD. Le pixel pipeline hanno 2 alu ciascuna, per un totale di 2 MADD e 20 flops (ogni MADD equivale a una MUL e una ADD su un vettore a 4 componenti e su uno scalare). Quindi, le pixel pipeline di G70, escludendo le normalizzazioni a fp16, hanno un potenziale teorico di 480 flops per ciclo a cui vanno aggiunte le 80 flops delle unità di vertex shading. Le 128 alu di G80, tutte scalari, sono di tipo MADD+MUL, quindi, ognuna è in grado di eseguire un massimo di 3 flops per ciclo, per un totale di 384 flops per ciclo. SE ci limitiamo alle sole MADD (il tipo di alu più utilizzato), vediamo che, a fp32, le flops per ciclo di G80 scendono a 256 contro le 560 (teoriche) di G70.
Tutte queste chiacchiere e numeri, per dimostrare che il numero di alu complessivo di G80 è piuttosto “esiguo” anche rispetto alla vecchia generazione di chip nVidia. Le cose che fanno la differenza a vantaggio del nuovo nato sono essenzialmente tre: il passaggio alle DX10 che si traduce in un maggior numero di registri in cache e buffer più numerosi e spaziosi che, all’atto pratico, significano maggior possibilità di fare thread switching e miglior mascheramemto delle latenze; la maggior efficienza complessiva dell’architettura; la frequenza dello shader core, sensibilmente più alta di quella del resto del chip che significa più operazioni al secondo per ogni alu.
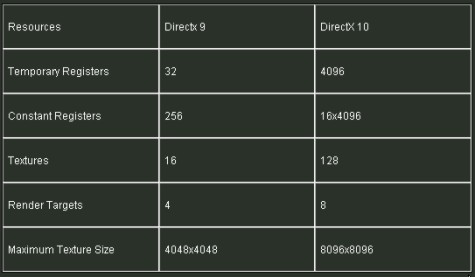
Riguardo al primo punto, per dare una vaga idea di come aumenti la complessità dei circuiti interni nel passaggio dallo SM3.0 allo SM4.0, mostro questa tabella riassuntiva, piuttosto scarna e decisamente incompleta ma che serve semplicemente a fornire un termine di paragone tra le due differenti versioni di API
La tabella, nello specifico, è riferita alle specifiche delle unità di vertex shading per le DX9 (per i pixel shader il numero minimo di constant register è pari a 224) mentre, come tutti sanno (almeno spero), con le DX10 non ha più senso parlare di distinzione tra differenti tipi di alu.
A questo aumento di complesità delle istruzioni deve far riscontro un comparabile aumento della capacità di gestire questa maggior complessità e, di conseguenza, un’adeguata potenza di calcolo.
E qui veniamo al secondo punto: abbiamo visto che il numero equivalente di alu è diminuito (va ricordato che quelle di G80 sono scalari) . Quindi, dove prende il chip, questa maggior potenza di calcolo? Solo nelle maggiori frequenze dello shader core? In parte si, ma, per lo più, la maggior potenza va cercata nella maggior efficienza di un’architettura a shader unificati. Nella successiva figura è mostrata la media dei carichi di lavoro distribuiti tra vertex e pixel shader.
![]()
Da questa immagine si vede che, mediamente, sono i pixel shader a sopportare la maggior mole di lavoro ma che spesso accade che quando uno dei due blocchi di unità ha un “picco” l’altro presenta un “ventre”. Il che significa che in un’architettura a shader dedicati è pressoche impossibile avere tutte le unità contemporaneamente occupate ad eseguire calcoli. Questo si ripercuote in una inefficienza generale dell’intera architettura.
Infine, la maggior frequenza dello shader core; scelta dettata dalla necessità di avere più raw power nei calcoli matematici ed equilibrare l’elevato numero di altre unità funzionali interne al chip (tmu e ROP’s su tutte).
Chi, invece, fa la scelta opposta. è ATi che decide di adottare un approccio “brute force” per le alu e uno molto più raffinato per il resto del chip. R600 e, ancora di più, RV770 ed RV870, hanno, infatti, un gran numero di alu di tipo VLIW e un numero decisamente più limitato, in proporzione, di tmu e ROP’s, con architettura interna e del Memory controller di tipo asimmetrica, con enorme bus verso l’interno del chip e bus ridotto (solo 256 bit) verso l’esterno. Se da un lato nVidia propone ben 32 texture unit, ciascuna dotata di altrettante TAU (texture addressing unit) e TSU (texture sampling unit) e con ben 64 texture filtering unit, in modo tale che operazioni come l’applicazione del trilinear filtering avvengano “for free”, dall’altro ATi tende a ridurre le latenze nelle operazioni di texturing con texture cache di tipo fully associative e con le TMu organizzate come si vede in figura
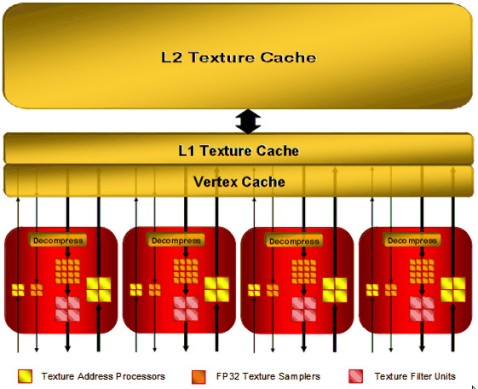
con 4 TMU dotate ciascuna di 4 TAU e altrettante TFU ma con ben 16 TSU (per un totale di 64). Inoltre, come si vede dalla figura, in caso di vertex texturing, le tmu possono campionare altre 16 texture non filtrate ed arrivare ad un totale di 32 (come nVidia). Questo significa che quando si effettuano contemporanemente accessi a texture sia per le operazioni geometriche che per quelle di pixel shading, lo svantaggio di avere meno unità di filtraggio delle texture si riduce in quanto i chip ATi hanno unità dedicate agli accessi a texture per le operazioni geometriche, mentre quelli nVidia ne sono sprovvisti e utilizzano le stesse tmu sia per texture filtrate che per texture non filtrate. Ovviamente, al contrario, quando si ha necessità di operare solo su texture filtrate, il maggior numero di TFU dei chip nVdia è in grado di fare la differenza, nonostante le minori frequenze di funzionamento del core di G80 rispetto a quello di R600 (e quindi anche delle rispettive TMU).
Scendendo un po’ più nel dettaglio, cerchiamo di capire cosa c’è alla base delle rispettive scelte architetturali. Da un lato, nVidia ha puntato su un’architettura in grado di trovare in automatico, sia l’ILP che il bilanciamento ottimale dei carichi di lavoro. Questo permette di raggiungere un’elevata efficienza del chip e una notevolmente minore dipendenza dal codice che il chip stesso si trova ad elaborare. Il contro è che questo tipo di scelta comporta una notevole complessità a livello di circuiti preposti a organizzare, distribuire e controllare il lavoro tra le varie unità funzionali e, di conseguenza, molto meno spazio nel die, a disposizione delle unità funzionali. Inoltre, c’è da sottolineare che i suddetti circuiti di controllo, scheduling, ecc, sono anche quelli più soggetti a disturbi di qualsivoglia tipo. Questo non permette il raggiungimento di elevatissime densità circuitali e abbassa anche le rese produttive dei chip.
Al contrario, la scelta di ATi, pur considerando l’efficenza complessiva dei chip a shader unificati rispetto a quelli a shader dedicati, si potrebbe, paradossalmente, definire, una scelta che “premia l’inefficenza” a vantaggio della possibilità di implementare un elevato numero di unità funzionali in uno spazio ridotto e di aumentare le rese produttive. Inoltre, l’aver affidato le operazioni di raggruppamento e assegnazione delle istruzioni al compilatore, se da un alto rende il chip molto più dipendente dal tipo di codice da elaborare e richiede continue ottimizzazioni del compiler, dall’altro rende l’architettura più flessibile e adattabile, ad esempio, ad un cambio di API.
Insomma, da una parte c’è nVidia che dice: “ok, tiriamo fuori un’architettura che renda al meglio, da subito, senza troppi sbattimenti, non ha importanza che sia poco flessibile e che, al cambio di API mi costringerà ad una profonda revisione e non mi importa quanto sia grossa e complessa” (insomma, continuando a perseguire le filosofia che sia ATi che la stessa nVidia avevano seguito fino alla generazione DX9), dall’altro c’è ATi che dice: “la nostra architettura deve essere, in primo luogo, economica da produrre, deve avere rese elevate, non particolarmente complessa e facilmente adattabile al cambio di API; per le prestazioni ci affidiamo al gran numero di ALU”. Questo perchè, con il passaggio agli shader unificati, l’importanza dello shader core è aumentata ancora di più rispetto al passato, in quanto adesso, non solo deve occuparsi delle classiche operazioni di pixel e vertex shading; ad essi sono stati aggiunti il geometry shader, i compute shader, fino alla definizione delle caratteristiche del tessellator delle DX11, vertex e geometry shader si occupavano anche di fornire al tessellator vero e proprio le indicazioni su numero e posizione dei nuovi vertici da “aggiungere” e, infine, lo shader core deve occuparsi anche di implementare tipologie di antialiasing custom e di effettuare texture filtering (feature inclusa nelle DX11). Quindi, shader core sempre più centrale nell’architettura di una GPU e due scelte diametralmente opposte, una che mira a renderlo sempre più efficiente e l’altra sempre più affollato.
Nel breve periodo, la scelta migliore è sembrata quella di nVidia, con G80 apparso decisamente superiore ad R600. Gia con RV670, però, si andava delineando la strategia di ATi: chip piccoli che puntano all’ottenimento di yeld molto elevati e con la possibilità di includere tanti cluster di alu (addirittura in numero ridondante) per aumentare le rese, pur mantenendo contenute le dimensioni del die. Inoltre, il vantaggio di un processo produttivo ha permesso ai canadesi di programmare con tutta calma la transizione ai successivi step, ovvero RV770 ed RV870.
Al contrario, nVidia, dopo aver mietuto consensì e successi con G80, si ritrovava tra le mani un prodotto il cui sviluppo si presentava piuttosto problematico: troppo poco flessibile e troppo complesso per adattarsi senza troppa fatica alle DX10.1 e, successivamente, alle DX11; addirittura troppo poco flessibile per implementare la doppia precisione senza il ricorso ad alu dedicate (che, però, sottraggono, in GT200, altro spazio nel die a quelle di tipo fp32 dedicato al mercato gaming).
Dalla posizione di vantaggio prestazionale piuttosto consistente conseguita con G80, nVdia si è, dunque, ritrovata a fronteggiare una situazione in cui era costretta ad inseguire perchè in ritardo sull’adozione di nuovi processi produttivi, con un’architettura nuova come quella di GT200 costosa e che mal si prestava a fare esperimenti di sorta e, di conseguenza, si è vista costretta a sperimentare i nuovi processi produttivi con l’unica architettura collaudata che aveva a disposizione, ovvero quella di G80. Questo ha generato una certa confusione dovuta alla sovrapposizione potenziale di prodotti derivanti dagli scarti di G80 e di GT200. La conseguenza più immediata è stata la mancata commercializzazione dell’intera linea di scarti di GT200 a 65 nm e a 55 nm se si escludono le 260 GTX e le 275 GTX, sostituite, in fascia media e bassa, da derivati di G8x e G9x (ovvero, sostanzialmente, la stessa architettura). Ovviamente, questa situazione ha creato una gran confusione anche a livello di nomenclature con continui renaming motivati dalla necessità, presunta, di non lasciare scoperte alcune fasce di prodotti. Di fatto, però, ad esempio, i chip derivanti da G8x, come tutti quelli con sigle da 250 in giù, non hanno la stessa architettura dei chip di fascia superiore, derivanti, invece, da GT200 e, quindi, è differente il rapporto tra alu e tmu e non sono in grado di fare calcoli a fp64.
Nel lungo periodo, ancora una volta G8x si è rivelato prezioso nella sperimentazione del processo produttivo a 40 nm, per evitare di dover effettuare il salto nel buio costituito dall’adozione di una nuova architettura (Fermi) abbinata ad una transizione di tipo full node tra processi produttivi.
Anche le scelte operate con GT300 indicano che nVidia ha deciso di proseguire sulla strada fin qui tracciata, tentando di aumentare ulteriormente l’efficienza del chip a scapito delle dimensioni e delle rese produttive, almeno in determinati ambiti, ma puntando, questa volta, alla possibilità di far uso delle stesse unità fp32 per i calcoli in double precision, come avviene già con i chip ATi e come dovrebbe avvenire con Larrabee di Intel che, invece, sembra aver scelto di percorrere la stessa strada tracciata da ATi, con un chip addirittura quasi del tutto privo di fixed function pipeline (i chip ATi e nVidia ne hanno a livello di ROP’s, TMU e, con le DX11, a livello di tessellator) se si escludono le operazioni di texture sampling e addressing e che, ancora di più dei chip canadesi, di affiderà al compilatore. Intel ha fatto esperienza di architetture EPIC con gli Itanium e punta sul fatto di avere i migliori compilatori in circolazione ma sarà comunque non facile inserirsi in questa lotta che va avanti, ormai, con alterne fortune, da circa un decennio.
Di certo, al momento, Larrabee appare ancora lontano e, dopo la presentazione dei chip ATi DX11, tutte le attenzioni sono concentrate sulla nuova creatura di casa nVidia di cui, giornalmente, si legge tutto e il contrario di tutto e che, di certo, rappresenta un progetto molto ambizioso ma che sta incontrando notevoli difficoltà di realizzazione a causa, soprattutto, della sua complessità architetturale.
Da quanto trapelato nella presentazione dell’architettura di GT300, ci si dovrebbe trovare di fronte ad un chip con grandi potenzialità nel campo del GPGPU, grazie all’elevata potenza di calcolo in doppia precisione, con un’efficienza maggiore di quella di GT200 nella gestione del multithreading e la possibilità di fare MUL di tipo INT a fp32 (sia GT200 che i chip ATi, compreso RV870, si fermano a fp24); unica incognita sembrerebbero proprio le performance nel segmento gaming, per tutta una serie di ragioni tra cui le modalità di implementazione delle operazioni di tessellation e il numero di MADD a fp32 reali di cui la nuova architettura è capace. Alcune speculazioni, infatti, riportano che le 512 alu di Fermi siano in grado di eseguire un massimo teprico di 512 FMA per ciclo, ma solo 256 MADD a fp32 (che sono, poi, quelle utilizzate nei giochi); per curiosità, riporto questa tabella presa da un articolo di hardware.fr che mostra le capacità di calcolo di RV870, GT200 e Fermi a confronto
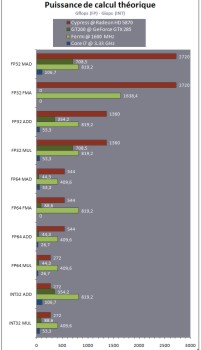
Mi scuso per le ridotte dimensioni (la tabella ingrandita è alla fine dell’articolo); quello che volevo puntualizzare è che, anche da questa tabella si deduce quanto la nuova architettura di nVidia sia votata al GPGPU, con la notevole potenza nei calcoli di tipo INT e un certo margine di vantaggio anche in fp64 rispetto a RV870. Ovviamente si tratta di speculazioni basate sui dati forniti dalla stessa nVidia, in cui si teorizza un funzionamento dello shader core di Fermi a 1600 MHz; in realtà, al momento, non c’è nulla di concreto a livello di bench reali, quindi non siamo in grado neppure di sapere se sia vera o meno la tesi sulla diversa capacità di calcolo tra operazioni senza arrotondamento intermedio (FMA) e con arrotondamento dopo la moltiplicazione (MADD).
Il motivo di questa scelta, credo sia piuttosto palese: nVidia, tra i grandi produttori e progettisti di chip per il mercato consumer, è l’unica priva delle licenze x86 (e, soprattutto, estensioni varie) ed è l’unica, al momento, non in grado di avere una piattaforma tutta sua che integri cpu e gpu per la fascia desktop o workstation. E’ ovvio, quindi, che tenda a spingere per far affermare il gpu computing e, spostare, così, gran parte della mole di lavoro di un pc o di una workstation su ciò che sa fare meglio ma anche sull’unica cosa che può, in effetti, fare; per ottenere ciò, ha bisogno di gpu che sappiano fare, il più possibile, le cpu e sta investendo ingenti risorse per raggiungere questo obiettivo. Sul versante opposto c’è Intel che, invece, spinge per far si che la cpu resti centrale all’interno di un pc e segue un approccio antitetico rispetto a quello di nVidia: ossia si avvicina al mondo delle gpu con un chip che, di fatto, è una cpu a cui sono state aggiunte unità funzionali tipiche delle gpu.
Insomma, dopo dieci anni e quattro capitoli di questo blog, siamo al punto di partenza: di nuovo ATi contro nVidia ma questa volta con due nuovi protagonisti; da una parte AMD di cui ATi fa ormai parte, che si trova nella situazione di chi rischia di farsi concorrenza in casa, qualora il GPGPU dovesse decollare e dall’altra Intel che rappresenta, per il potenziale a livello economico, di know how e di “influenza” sugli sviluppatori, nello stesso tempo, un’incognita e una minaccia.







