La scorsa settimana avevamo assistito alla reazione di nVidia al sorpasso tecnologico e prestazionale subito da parte di ATi con la prima generazione di chip DX9. Se con NV30 (Geforce FX) nVidia aveva conseguito un vantaggio in termini di processo produttivo adottato, con NV40 (aka 6800) se non riconquista la leadership prestazionale, messa in discussione dalle X850XT, si appropria di quella tecnologica con un chip che introduce grandi novità architetturali rispetto alla precedente generazione e può vantare una compatibilità con lo SM3.0 non alla portata della concorrenza.
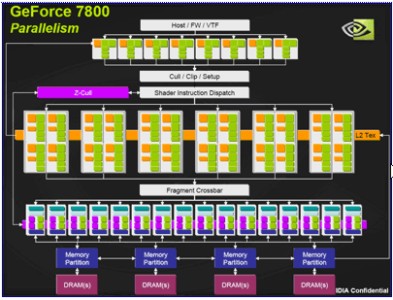
Con G70 si assiste al perfezionamento del già ottimo NV40, con l’adozione di una seconda alu di tipo MADD al posto di una MUL. Una delle novità di G70 è l’adozione di un numero di ROP’s (raster operation pipeline) differente rispetto a quello delle pipeline del pixel shader core
Fino a NV40 e R4x0 avevamo visto chip con n pixel pipeline ed uguale numero di ROP’s. La scelta di nVdia è dettata dalla considerazione che il maggior carico di lavoro si va spostando verso i pixel shader e difficilmente si verifica che questi restino in idle in attesa che le ROP’s terminino il loro lavoro.
Ovvio che se si avesse a disposizione uno spazio illimitato in cui allocare un numero di transistor a piacimento, non si farebbero considerazioni di questa natura. Poichè non è così e i progettisti di hardware (ma non solo loro) si trovano a combattere di frequente con il dilemma della coperta corta, dovendo scegliere lo stadio al quale dedicare più spazio e più transistor, si è deciso di sacrificare sull’altare della maggior potenza di calcolo matematico il floating point qualche pipeline di rasterizzazione.
Tra il pixel shader core e le ROP’s, come pure tra i vertex shader e i pixel shader, sono posizionati due crossbar e dei piccoli buffer; i primi servono a far si che i dati provenienti da uno stadio (ad esempio dai vertex shader) non debbano seguire un percorso obbligato ma possano essere istradati verso la prima pipeline libera dello stadio successivo, i secondi a immagazzinare quei dati provenienti dallo stadio a monte di ciascun buffer che devono essere temporaneamente “parcheggiati” in attesa che si libera una pipeline dello stadio successivo.
Questo serve a ridurre i tempi di idle dei vari stadi e in un’architettura a shader dedicati la cui efficienza può variare notevolmente a seconda di come sono distribuiti i carichi di lavoro soprattutto tra vertex e pixel shader, rivestono una particolare importanza.
Sull’altra sponda, dopo il successo di R300 e derivati (le serie 9700, 9800, ecc), ATi si ritrova con un prodotto tecnologicamente più avanzato e, in DX9, notevolmente più veloce di quello della concorrenza, ma con un processo produttivo di ritardo (R300 è a 150 nm mentre NV30 è a 130 nm).
Con la successiva generazione, si limita, dunque, a modificare in minima misura R300, quel tanto che è sufficiente a rendere il nuovo chip compatibile con lo SM2.0b e ne raddoppia il numero delle pixel pipeline e delle ROP’s. Così facendo, nel cambio generazionale si trova a dover inseguire sul piano delle feature implementate ma, nel contempo, ha visto coronati gli sforzi atti a recuperare il gap in termini di processi produttivi.
Apro una parentesi per commentare situazioni di questo tipo che si sono verificate in passato, si stanno verificando al giorno d’oggi e si verificheranno ancora in futuro. Di fronte a fatti del genere, il commento tipico del forumista medio è:”si sono adagiati sugli allori” con tutto ciò che ne consegue. Di fatto le cose non stanno così.
Ad esempio, ATi non si è adagiata sugli allori dopo R300 e dopo R5x0, come non lo ha fatto nVidia dopo G80. L’andamento è fisiologico e tiene conto di diversi elementi che ai non addetti ai lavori spesos sfuggono. Ad esempio, nel passaggio da NV30 a NV40 nVidia ha introdotto tantissime novità architetturali, al punto da poter affermare che NV30 ed NV40 sono solo lontani parenti; però la parentela di NV30 con, ad esempio, NV2x è più stretta.
Questo significa che, finchè ha potuto, nVidia ha “spremuto” un’architettura che si era rivelata vincente. Un progetto deve tener conto, tra le altre cose, dei costi di R&D, di quelli di realizzazione, dei tempi necessari ad ammortizzare questi costi e in questa valutazione entra la complessità del’architettura e la sua flessibilità, le dimensioni del chip e, di riflesso, il processo produttivo adottato (e quindi i costi di tecnologie e materiali).
In quest’ottica, acquisire il vantaggio di un processo produttivo o avere un chip di dimensioni sensibilmente inferiori o più “adattabile” a nuove versioni di API senza grandi rivoluzioni può diventare un elemento determinante, ancora più dell’efficienza stessa del chip. Questo perchè la parte tecnnica o tecnologica non può prescindere da valutazioni di carattere economico (sempre per la storia della coperta corta).
Chiusa questa parentesi, appare dunque chiaro che, se da un lato nVidia era stata costretta a modificare radicalmente la sua architettura per risolvere o aggirare i problemi incontrati con NV3x, dall’altro ATi si trovava per le mani un’architettura eccellente che le permetteva di concentrarsi su due obiettivi: l’azzeramento del gap relativo ai processi produttivi e la progettazione di un’architettura nuova che gettasse le basi per la successiva generazione. In questo contesto nascono, nell’ordine, i chip delle serie R4x0 ed R5x0, i primi come risposta alla prima delle due esigenze i secondi come ponte verso le DX10.
Con queste premesse, ovviamente, la nostra attenzione non sarà focalizzata su R4x0 ma su R5x0 che, per la nostra trattazione riveste un interesse ben maggiore. A ben guardare, forse l’unico motivo di interesse vero relativo a R4x0 risiede nel fatto che, per la prima volta, dopo R100, R200 ed R300, ATi decide di non seguire la numerazione solita ma etichetta i suoi chip con numeri non multipli di 100, ossia R420, R480, ecc.
Di fatto, in casa ATi si è scelto di numerare con multipli di 100 i chip che rappresentano un cambio d’architettura rispetto al passato; quindi R4x0 non rientra, evidentemente, in questa categoria. A questo punto, ci sarebbe da indagare sulla scomparsa di 2 chip capostipiti delle rispettive generazioni e, rispettivamente, R400 ed R500. Il giallo, però, non è degno di Sherlock Holmes e neppure di Hercule Poirot ma è di facile soluzione.
Finita la numerazione della serie 3 (con R380), non avendo titolo, il nuovo chip ad essree considerato un capostipite, si è passati ad R420. C’è, inoltre, da tener conto che, nello stesso periodo in cui in ATi si lavorava su R4x0 prima e su R5x0 (le serie X1xx0), poi, si stava portando avanti anche il progetto noto come C1 o Xenos o, anche, R500, ossia il primo chip a shader unificati, destinato alla nuova console di Microsoft, Xbox360.
R500 ha, al di là dell’unificazione di pixel e vertex shader, a livello di architettura della singola alu, diverse analogie con i chip delle serie PC; in particolare, ha 48 alu ciascuna formata dall’unione di una vect4 con una scalare fp32, sul modello delle unità di vertex shading di R300 e dei chip successivi (vedremo che ATi conserverà anche con i chip a shader unificati le 5 alu fp32 in parallelo).
I 4 gruppi, da 12 alu ognuno, è dotato di 4 tmu ma, come in R5x0, le tmu sono fuori dallo shader core e sono raggruppate in 4 cluster da 4 unità ciascuno. Con la serie R5x0, C1 condivide anche la presenza di un thread dispatch processor e le funzionalità di memexport che permette l’accesso diretto, per operazioni di lettura, alla ram di sistema da parte dello shader core.
Quindi, da queste poche righe, appare chiaro che le analogie, architetturali sono molteplici, soprattutto in riferimento ad R5x0. R500 rappresenta sicuramente una nuova architettura mentre R5x0 si può considerare, alla luce della sua parentela con Xenos e con R3x0, una sorta di ponte tra il vecchio, rappresentato dall’ultima generazione ashader dedicati e il nuovo, ossia la prima generazione a shader unificati per PC.
Passiamo, quindi, a dare un’occhiata a R5x0, la vera risposta di ATi a NV40 e G70. Ad una prim aocchiata, il pixel shader core, in versione R580 (1900 e 1950), la parte più interessante del chip, si presenta in questo modo
![]()
Da questa immagine si vede chiaramente il gruppo delle texture unit poste fuori dallo shader core. R5x0 ha 16 unità di texture filtering e altrettante di texture addressing, esattamente come R500, ma, al contrario di quello che avevamo visto la settimana scorsa per i chip nVidia, non ha texture unit nelle vertex pipeline e ciò impedisce ai chip ATi di questa serie di fare vertex texturing nella maniera prevista dallo SM3.0.
La scelta di mettere le tmu fuori dallo shader core e la mancanza di testure unit nelle unità di vertex shading è un chiaro segno di quanto questo chip sia stato ideato, in realtà, pensando al suo successore; infatti nei chip a shader unificati non ha senso pensare ad una divisione tra unità di vertex e pixel shading ed una tmu che fa texture fetch può mettere la texture a disposizione sia delle operazioni di vertex che di pixel shading, indifferentemente. Come vedremo, anche in R600 le tmu sono fuori dallo shader core.
Nel disegno precedente, si vedono chiaramente 12 gruppi di 4 alu ciascuno (come in R500); ogni alu ha un’architettura come quella mostrata nella successiva immagine
![]()
da cui si vede che ognuna delle 48 alu è, di fatto, composta da una ADD vect3 + fp32 scalar seguita da una MADD vect3 + fp32 scalar. Contrariamente a quanto visto nei chip nVidia, l’unità di branching in parallelo con le alu e non in serie. Ogni alu così composta è in grado di eseguire un massimo di 4 istruzioni (2 ADD co-issue più 2 MADD co-issue) oltre ad un accesso a texture ed una istruzione di branching in parallelo.
Le alu sono, di fatto, raggruppate in cluster di 12, in modo da formare solo 4 gruppi gestiti da un MC dotato di bus ibrido, per metà di tipo ring e per metà di tipo crossbar, come indicato in figura
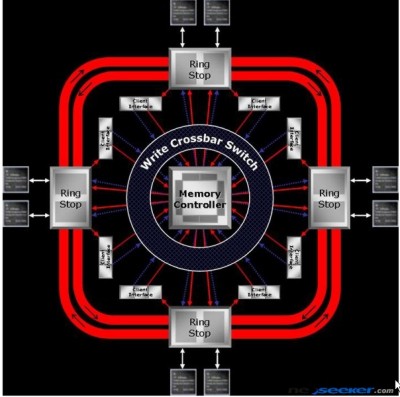
dove le richieste di accesso alla ram e le istruzioni viaggiano sui bracci del crossbar mentre i dati si muovono lungo i due anelli del ring bus.
Il bus verso la memoria è a 256 bit, di tipo crossbar, con 4 bracci da 64 bit ciascuno (32 da e 32 verso la ram) ognuno dei quali ottimizzato per gestire l’accesso a 2 banchi di ram.
Le cache interne sono di tipo fully associative per ridurre al minimo il rischio di cache miss.
Al pari di G70 ed NV40, anche R5x0 è in grado di utilizzare 4 color buffer e 1 z-buffer ma, al contrario di quanto visto per i chip nVidia, quelli ATi sono in grado di superare le limitazione che prevede per tutti i color buffer la stessa modalità di blending e che di fatto impedisce l’utilizzo di HDR (il cui blending prevede l’utilizzo di fp16 o INT10 per i tre canali RGB e 2 bit per il canale alpha, ecc) e il MSAA che prevede l’uso di INT8 nello z-buffer.
Infatti, con la limitazione della medesima modalità di blending non è possibile, una volta calcolati separatamente i valori dello z-buffer e quelli di un color buffer, utilizzare un altra porzione del frame buffer per fare downsampling del color buffer e successivo blending con i valori dello z-buffer.
Molto buona sia rispetto alla concorrenza che agli stessi chip ATi della precedente generazione, la qualità dei filtri, in particolare dell’anisotropico che risulta molto meno dipendente dagli angoli multipli di 45° come avviene sui chip nVidia e su R4x0 (al filtro anisotropico sarà dedicato un capitolo a parte).
A livello prestazionale, soprattutto in versione R580, i nuovi chip permettono alla casa canadese di salire di nuovo sul gradino più alto del podio, si a livello prestazionale che tecnologico. In particolare, grazie all’adozione del semi ring bus e al suo MC di tipo programmabile (come il thread dispatch processor) la GPU ATi mostrano un hit prestazionale, con i filtri attivi e in condizioni di lavoro pesanti (shader complessi e gran mole di calcoli), decisamente inferiore rispetto a quanto fatto vedere dalla concorrenza.
Un altro vantaggio di R520 in particolare ma anche di R580 rispetto alla controparte verde è nella gestione del dynamic branching: i chip ATi fanno, infatti, uso di una granularità dei thread molto più fine: 16 pixel e 64 (come Xenos) rispettivamente per la X1800 e la X1900 contro, ad esempio, i 1024 di NV40 e i circa 800 di G70. In effetti il dynamic branching dei chip nVidia, fino a G80 escluso, non è affatto gestito in maniera efficiente poichè l’uso di batch di pixel di grandi dimensioni rende più difficili le “previsioni” dei salti condizionali, come mostra la sottostante figura
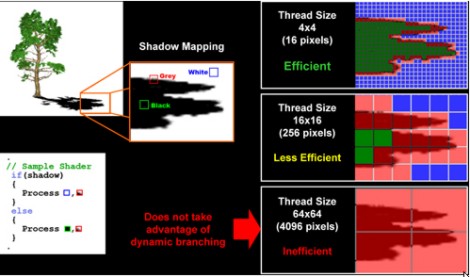
La granularità molto fine dei chip di ATi li rende anche particolarmente adatti per il GPGPU che proprio in questo periodo inizia a suscitare un certo interesse e non poca curiosità.
Poichè lo scopo di questo articolo non è quello di fare un’analisi architetturale approfondita dei chip in esame ma solo di raccontarli per cercare di capire la situazione determinatasi ai nostri giorni, mi fermo qui con l’analisi delle architetture.
Siamo arrivati al punto in cui, dopo essere passata una prima volta in vantaggio per un breve periodo, ATi si è vista superare di nuovo da nVidia ma, con R5x0, torna a prendersi la leadership e, oltre a ciò, dopo aver recuperato un processo rpoduttivo di ritardo si porta in vantaggio anche in quel campo, adottando, con gli ultimi chip della serie R5x0 il pp a 80 nm mnetre nVidia è ancora ferma a 90 nm.
A questo punto tocca di nuovo a nVidia inseguire e, come vedremo, la rincorsa porterà a quel gioiellino noto come G80, un chip dall’efficienza molto elevata grazie alla scelta dell’architettura superscalare. Ma, pur riprendendosi la leadership a livello prestazionale, nVidia non riuscirà a recuperare il gap sul processo produttivo che anzi, ad un certo punto, finirà con l’allargarsi. Con la generazione DX10 appare evidente che nVidia e ATi, ormai assorbita da AMD, stanno prendendo strade differenti a livello progettuale; percorsi destinati sempre più a divergere.







