Oggi vorrei parlare di un elemento architetturale su cui si focalizza troppo poco l’attenzione rispetto a quella che è la sua reale importanza e la sua incidenza sulle prestazioni di un sistema come, ad esempio, un pc, o di un sottosistema, come quello grafico: il memory controller (MC). Con particolare riferimento alle vga, già nel 2001, alla presentazione della lightspeed memory architecture, nVidia definì, correttamente, il MC “uno dei componenti più critici di un sistema grafico”.
In effetti il MC è uno dei componenti più critici di qualunque sistema e il motivo è presto detto. Si parla tanto di potenze di calcolo, di MHz, di parallelismo, di unità di calcolo, ma si pensi essenzialmente ad una cosa: istruzioni e dati devono essere spostati di continuo dalla ram all’interno di un chip e viceversa; più dispositivi hanno necessità di accedere alle stesse risorse nello stesso tempo; è necessario permettere alle varie unità di cui è composto un sistema (alu, stream processor, core, ecc) di comunicare tra di loro e scambiarsi quanti più dati e istruzioni possibili ad ogni ciclo ed è necessario permettere che ciò avvenga nel più breve tempo possibile ed in maniera tale da minimizzare i colli di bottiglia.
Perchè ciò avvenga, si ha bisogno di “strade” per dati e istruzioni e di una serie di “semafori” di “vigili urbani” che “dirigano il traffico”. Un memory controller si occupa proprio di gestire questo intenso traffico utilizzando dei canali di comunicazione controllati da dispositivi definiti arbiter (con annessi sequencer). In questo articolo mi occuperò di introdurre soltanto alcuni tra i più noti (ed usati) MC che si possono rinvenire su piattaforme di tipo consumer e, in particolare, quelli presenti all’interno di chip quali cpu, gpu e north bridge. Questi tipi di connessioni rientrano tra quelle definite di tipo dinamico che sono contraddistinte dall’utilizzo di switch e strutture a bus, da contrapporre a quelle di tipo statico, in cui i nodi sono direttamente connessi tra di loro (mesh, ipercubi, ring, alberi, ecc).
Iniziamo col dire che il MC può essere interno ad una cpu o ad una gpu, oppure può essere contenuto all’interno di un altro chip. Ad esempio, nelle architetture per pc di tipo classico, il MC è integrato nel northbridge (NB) e si avvale anche di un hub che mette in comunicazione diretta la cpu e la vga con la ram, indirizza e smista le richieste di accesso alla memoria provenienti anche dal southbridge (SB).
Le richieste di accesso alla ram sono di due tipi: il primo coinvolge la cpu per l’intero processo di trasferimento dei dati e, di conseguenza, comporta un notevole impiego di risorse da parte dell’unità centrale di elaborazione; l’altro, su cui mi soffermerò brevemente, definito DMA (direct memory access), tipico di dispositivi più recenti, coinvolge la cpu solo nell’operazione di inizializzazione della rihciesta di accesso alla ram. In pratica, una volta che è stato assegnato uno specifico compito ad un determinato dispositivo, questo inoltra una comunicazione alla cpu attraverso cui informa di essere a disposizione per una nuova elaborazione. La cpu invia gli indirizzi dei blocchi di memoria da cui prelevare i dati necessari a eseguire le istruzioni realtive a quel dispositivo. A questo punto, il dispositivo è pronto ad avviare una richiesta di accesso alla ram per prelevare ciò che gli serve. La richiesta è inoltrata al MC che la mette in coda all’interno di un buffer. Una volta che il buffer è pieno, il MC decide quali richieste evadere per prime. Il MC non è un dispositivo in order ed il suo buffer, di conseguenza, non è di tipo FIFO (first in first out), ma decide secondo criteri ben precisi, in base a come è stato ottimizzato il lavoro del sistema. Ad esempio, le richieste di accesso da parte della VGA potrebbero avere la precedenza rispetto a quelle del controller audio e, di conseguenza, anche se sono arrivate dopo vengono evase prima. Una volta che il dispositivo ha completato il suo lavoro, invia un interrupt alla cpu con cui, in pratica, comunica di essere di nuovo a disposizione per l’assegnazione di un nuovo compito.
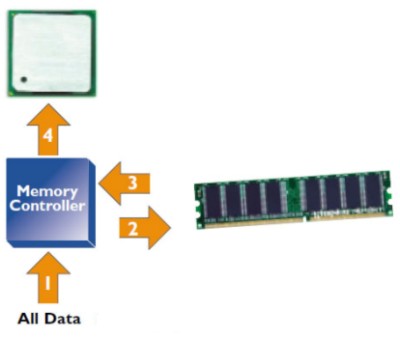
A seconda della tipologia di network (in questo articolo tratteremo esclusivamente quelli a bus), il MC è impegnato per più o meno cicli di clock prima di tornare disponibile per evadere un’altra richiesta di accesso alla memoria. Uno schema tipico che include il MC (in questo caso può essre integrato nel NB ma anche all’interno della cpu) è quello riportato in figura
Il MC illustrato è, chiaramente, di tipo single channel, abbinato ad uno o più bus o crossbar switch e i dati in ingresso possono provenire da tutte le periferiche connesse al SB e, anche, dalla vga; c’è da osservare, però, che le moderne GPU hanno la possibilità di accedere direttamente alla ram di sistema (non solo alla vram), bypassando la cpu e il MC integrato in essa o nel NB.
Dopo questa breve digressione, passiamo brevemente in rassegna i principali tipi di bus con relativi MC che si sono visti sui vari sistemi nel corso di questi anni.
Il più classico è il controller a canale unico a 64 bit, presente sulle piattaforme di tipo single channel visto poco sopra. Il suo funzionamento è schematizzabile con l’esempio in figura
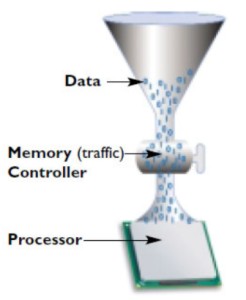
Il canale dei dati (a forma di imbuto) rappresenta il collegamento con la ram di sistema) e l’arbiter è il rubinetto che regola i flussi. In realtà, più che di un rubinetto si può parlare di un semaforo “intelligente”, presente ad un incrocio, in grado di stabilire a chi mostrare il verde e per quanto tempo.
Un’evoluzione del MC single channel è il dual channel
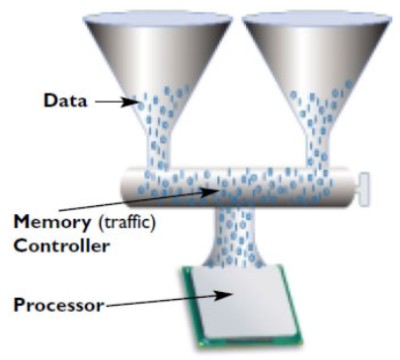
Come si vede, le “strade verso la memoria” diventano due, raddoppiando il traffico dei dati in ingresso e in uscita. Questo tipo di MC è in grado di trasferire 128 bit per cicli di clock. Ulteriore evoluzione, il MC triple channel (192 trasferiti per ciclo). Nell’immagine in basso, è riportato uno schema a blocchi, molto semplificato, di una cpu di tipo opteron, quad core, con MC dual channel integrato
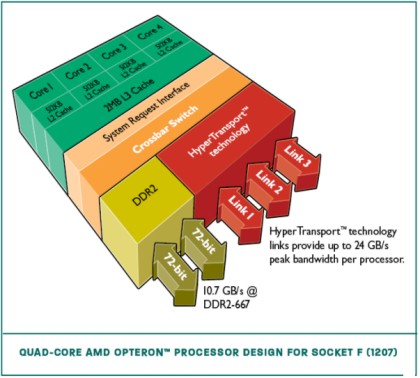
I due canali sono a 72 bit (anzichè 64) per supportare le ram ECC.
Per dovere di cronaca, riporto che un controller multichannel può essere di tipo sincrono o asincrono: il primo offre prestazioni migliori ma pone qualche vincolo in più (le ram utilizzate devono avere stessa velocità stesse latenze e stessa capacità); il secondo ha prestazioni inferiori, ma permette di utilizzare banchi di ram di capacità differente (ma con identiche frequenze e latenze).
Analogamente a quanto visto per le cpu e per i MC integrati nei NB delle schede motherboard, anche all’interno dei chip grafici è integrato uno o più MC. Poichè questa rubrica si occupa principalmente di vga e gpu, presteremo un’attenzione superiore alle tecnologie utilzzate per queste ultime.
Anche nelle gpu, fino al 2000, si faceva uso di MC di tipo single channel a 64 o a 128 bit, come quello schematizzato in figura
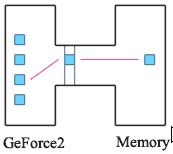 Una simile architettura è estremamente semplice ma presenta alcuni colli di bottiglia: innanzitutto ha una granularità “grossa”, in quanto permette solo il trasferimento di blocchi da n bit per ciclo dove n è l’ampiezza del bus (64, 128, 256 bit, ecc) o, se ad esempio, si utilizzano ram di tipo DDR o DD2, ecc, di 2, 4 o più volte n per ciclo (ad esempio un bus da 128 bit abbinato ad una ram DDR permetterà il rasferimento di 256 bit per ciclo del core clock (le DDR hanno un data rate clock differente rispetto al core clock e multiplo di esso rispetto a potenze del 2). In secondo luogo, il MC di questo tipo di bus, in caso di richiesta di DMA deve eseguire le seguenti operazioni: ricevere la richiesta di accesso
Una simile architettura è estremamente semplice ma presenta alcuni colli di bottiglia: innanzitutto ha una granularità “grossa”, in quanto permette solo il trasferimento di blocchi da n bit per ciclo dove n è l’ampiezza del bus (64, 128, 256 bit, ecc) o, se ad esempio, si utilizzano ram di tipo DDR o DD2, ecc, di 2, 4 o più volte n per ciclo (ad esempio un bus da 128 bit abbinato ad una ram DDR permetterà il rasferimento di 256 bit per ciclo del core clock (le DDR hanno un data rate clock differente rispetto al core clock e multiplo di esso rispetto a potenze del 2). In secondo luogo, il MC di questo tipo di bus, in caso di richiesta di DMA deve eseguire le seguenti operazioni: ricevere la richiesta di accesso
inoltrare la stessa alle locazioni in memoria destinatarie della stessa
ricevere dalla ram i dati richiesti
inoltrare gli stessi alle unità di calcolo che ne hanno fatto richiesta
Dopo di che, può tornare a disposizione per una nuova operazione.
Per ovviare la primo dei due inconvenienti presentati, con la presentazione dell’NV20, noto come Geforce 3 e della lightspeed memory architecture, nVidia introduce un nuovo tipo di controller, definito crossbar, schemattizato qui sotto, per confronto con quello a canale unico
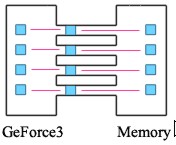 e riportato più in dettaglio nella prossima immagine
e riportato più in dettaglio nella prossima immagine
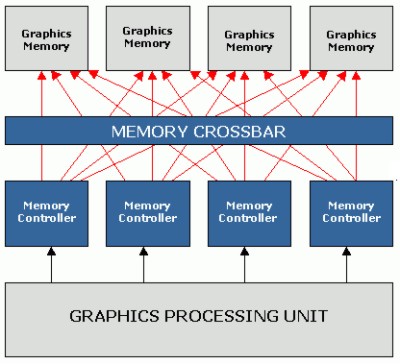
Come si può vedere, in realtà, il crossbar dell’NV20 è composto da 4 MC di tipo single channel, uno per ognuna delle ROP’s; ciascun MC serve un gruppo di unità di calcolo (alu, fpu e tmu) e ha accesso a ciascuno degli n blocchi di chip di vram presenti on board. Questa soluzione permette di ridurre notevolmnte la granularità dei dati in transito attraverso il bus. Il crossbar di NV20, di NV25 e di NV30, nonchè di R200, gestisce 4 canali da 32 bit ciascuno e lavora con chip di ram con interfaccia a 32 bit. Questo significa che, di fatto, ad ogni ciclo, per ogni MC, si ha transito di soli dati in lettura o scrittura, ma non è possibile sfruttare al meglio la peculiarità di ram, come le DDR, che presentano un fronte in lettura ed uno in scrittura all’interno dello stesso ciclo di core clock.
Questa interfaccia aumenta sensibilmente la complessità del MC ma permette una maggior ottimizzazione nel trasferimento dei dati e nell’inoltro delle richieste di accesso (che passano sempre attraverso gli stessi canali).
Un ulteriore passo in avanti lo fa ATi con R300, portando l’ampiezza del bus a 256 bit. L’architettura è formalmente identica a quella vista per il MC dell’NV20; il vantaggio consiste nel fatto che ogni canale permette il passaggio di un maggior quantitativo di dati anche se si perde in termini di granularità (nelle gpu, però, non si ha necessità di granularità particolarmente fine come nelle cpu, quindi , nel complesso, 4 canali da 64 bit si comportano meglio di 4 da 32). Questa soluzione ha, comunque, dei limiti: intanto non risolve il problema relativo all’utilizzo dell’arbiter che gestisce il singolo canale, che continua ad essere coinvolto in tutte e 4 le operazioni necessarie al trasferimento di dati da e verso la ram. Inoltre, benchè il crossbar sia un tipo di interconnessione studiato, in particolare, per i casi in cui il numero dei banchi o dei chip di ram sia superiore a quello delle unità di calcolo, qualora lo si fa lavorare con più di due chip per canale si ha un aumento delle latenze col risultato che, in elaborazioni che non risultino frame buffer limited, ovvero tali da richiedere più ram di quella presente sulla vga, un maggior quantitativo di chip per canale ram porta ad un degrado delle prestazioni. Inoltre, la complessità di un crossbar cresce con il quadrato del numero di processori o, in alternativa, di MC utilizzati (nel caso delle gpu col quadrato del numero di MC controller presenti a valle delle ROP’s), ciascuno dei quali deve essere connesso a tutti i cluster di alu ed a tutti i gruppi di chip di ram. Risulta evidente che il vantaggio del crossbar è che si riduce al minimo il rischio che più utilizzatori debbano concorrere per accedere alle stesse risorse, a patto di dimensionare correttamente il numero di nodi in relazione a quello delle unità di calcolo e dei chip di ram, ma la scalabilità, dal punto di vista dell’hardware, è pessima, poichè la complessità tende ad aumentare molto più rapidamente dei benefici ottenibili.
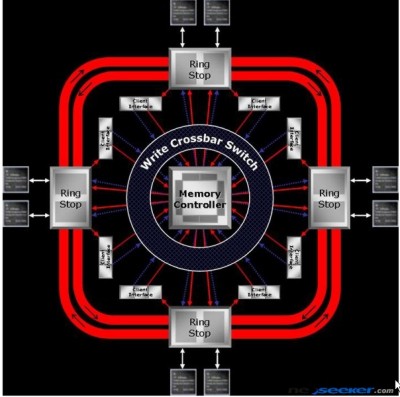
Un passo in una direzione diversa lo fanno ATi, con R520 prima ed R600 poi, e IBM con il CELL, adottando un bus ad anello. In una connessione a bus, la complessità delle interconnessioni resta costante all’aumentare del numero degli utilizzatori. Il risultato è un’ottima scalabilità sul piano dei costi e della complessità dell’hardware. Le prossime immagini riportano il ring bus di R580
e di R600
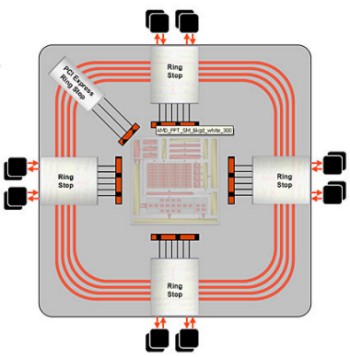
La prima differenza che salta all’occhio è che in R580 si ha un doppio anello con un MC centrale collegato con un crossbar. Tecnicamente non si può, quindi, parlare di ring bus fully distributed ma di ring bus di tipo ibrido, con le richieste di accesso che viaggiano lungo i canali del crossbar e i dati che sono messi in circolo lungo l’anello (anzi i due anelli, uno percorso in un verso e l’altro in verso opposto). Con R520 prima ed R580 poi, ATi abbandona la soluzione dei 4 canali a 64 bit per optare per 8 canali a 32 bit, in modo da ridurre la granularità ma, all’occorrenza, poter contare ancora su una via di comunicazione ampia 64 verso ciscun gruppo di chip di vram. Il ring bus di R580 presenta anche un altro vantaggio rispetto al crossbar: il MC è impegnato per un numero di operazioni minore e torna, quindi, più rapidamente a disposizione per le operazioni successive. Infatti, il gruppo di 4 MC centrali si occupa solo di ricevere le richieste di accesso alla ram e di inoltrarle alle locazioni interessate. Una volta giunta la richiesta, i dati sono inviati all’anello e, una volta giunti all’altezza del ring stop corrispondente al gruppo di alu che ne hanno fatto richiesta, vengono istradati. Con R520, per la prima volta, ATi fa uso anche di un bus di tipo asimmetrico, ampio 256 bit verso la ram (8 canali da 32) e 512 bit verso i 4 cluster di alu (8 canali da 64 bit). Se questa soluzione risolve il porblema delle elevate latenze del MC di tipo crossbar tradizionale, non risolve quello relativo alla complessità dell’architettura del bus e del relativo sistema di MC.
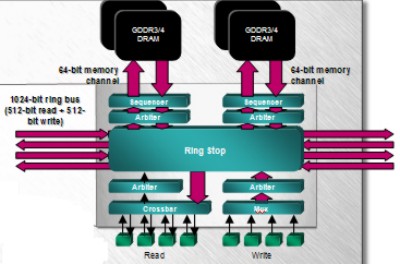
Con R600 si cerca di far fronte anche all’altro problema, ovvero quello della elevata complessità del crossbar e della sua pessima scalabilità a livello HW e di costi. Si pensa ad una soluzione con MC distribuiti e un gruppo di 4 anelli (2 per i dati e 2 per le richieste) con un sistema di ring stop ciascuno dei quali comprendente 2 MC e 2 canali da 64 bit verso le ram e da 128 verso le alu. In tal modo si elimina il crossbar centrale e si riduce la complessità dell’architettura, migliorandone la scalabilità. Inoltre, ciascun MC si limita a ricevere soltanto le richieste di accesso; qundi le mette in circolo all’interno di uno dei due anelli deputati al trasporto delle stesse. Ogni richiesta è “etichettata” in base alla locazione di memoria a cui è indirizzata; una volta giunta a destinazione, il MC del ring stop corrispondente a quel gruppo di ram si occupa di istradarla. Così il numero delle operazioni di cui si deve far carico ogni MC è ridotto a una. In realtà, le connessioni di tipo crossbar non spariscono del tutto dai MC ma appaiono notevolmente semplificate e ridotte a servire un numero imitato di nodi: sono infatti presenti all’altezza di ogni ring stop, come illustrato mnella successiva figura
Anche il ring bus presenta, comunque, difetti e criticità. Una di queste è da ricercarsi nel numero di processori o di cluster di alu destinati ad utilizzare una connessione ad anello di questo tipo. Se è vero che dal punto di vista della scalabilità HW si tratta di una soluzione ottima, è altrattanto vero che, all’aumentare del numero di utilizzatori, peggiora la scalabilità delle performance, al punto che l’ottimizzazione di questo tipo di architettura può diventare un fattore critico. Ad esempio, nel cell, di cui riporto l’immagine,
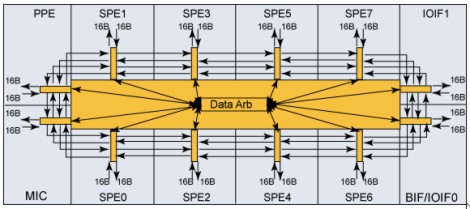
il fatto di avere 8 SPE più il PPE e il traffico di dati verso l’esterno del chip da gestire, rende l’ottimizzazione dell’arbiter centrale dell’EIB piuttosto complessa e permette il trasferimento dei dati da un SPE all’altro secondo modalità ben precise, pena un forte decadimento delle prestazioni complessive (che possono arrivare anche a dimezzarsi rispetto al picco massimo raggiungibile). Una delle raccomandazioni è quella, ad esempio, di limitare il trasferimento di dati tra processori molto distanti tra loro lungo i 4 anelli, oppure di limitare il numero di accessi contemporanei alla ram di sistema o i trafserimenti, lungo l’anello, che seguano tutti lo stesso verso (orario o antiorario); questo perchè nell’EIB (element interconnect bus) del cell 2 anelli sono percorsi in un verso e 2 in verso opposto (quindi la raccomandazione è quella di intasare una strada lasciando sgombra l’altra). Una curiosità che riguarda l’EIB è questa: inizialmente, IBM aveva pensato di utilizzare un crossbar e solo in un secondo tempo, per tentare di risparmiare transistor, ha optato per il ring.
Con le gpu di ultima generazione, da un lato nVidia ha continuato con il tradizionale crossbar, aumentandone l’ampiezza e portandolo, nelle sue versioni di punta, a 512 bit verso la ram (8 canali da 64 bit ciascuno con altrettanti MC) ma adottando una soluzione asimmetrica, con un’ampiezza di 1024 bit verso il chip (16 canali da 64 bit, ciascuno dei quali serve 15 delle 240 alu di GT200), mentre ATi ha abbandonato il ring bus per tornare ad una sorta di crossbar distribuito, con ampiezza pari a 256 bit verso le ram e 2048 (32 canali da 64 bit) bit verso le alu. In tal modo, ogni canale serve un gruppo di 5 unità vliw, per un totale di 25 alu. L’adozione di ram GDDR5 ha permesso anche di svincolarsi dal limite dei 64 MB per banco (ram GDDR da 128 MB esistono ma sono piuttosto rare e costose) e ha permesso di adottare soluzioni con 1 GB di ram continuando a rispettare la regola dei due chip per canale. In figura, il MC di RV770
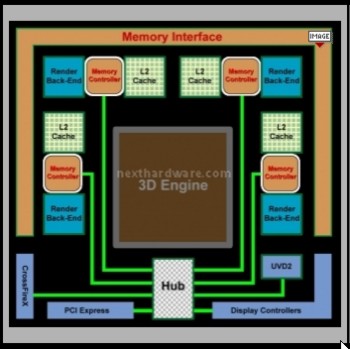
in cui si notano due cose, in particolare: la presenza di un hub attraverso cui passano tutti i segnali che non riguardano l’elaborazione 3D che in R600 erano gestiti dai MC del ring bus e che in RV770 hanno un canale dedicato a parte (in modo da non interferire negativamente con le elaborazioni grafiche); la presenza di 4 cache, per un totale di poco più di 5 MB, dedicate ai 4 MC e utilizzate per immagazzinare i dati più frequentemente utilizzati, ottimizzando l’occupazione della banda passante verso la ram.
Sulle tipologie di MC e di ram utilizzate ci sarebbero tante cose da aggiungere; ci si potrebbe soffermare sul cell per capire, magari, come sono gestiti i DMA con i SPE che fanno uso di memoria non cached, oppure come si interfaccia con le XDR. O magari si potrebbe parlare delle RDRAM e dei relativi MC. Poichè, però, lo spazio è limitato (e credo di averne abusato già a sufficienza) e l’argomento principale di questa rubrica sono le gpu, mi fermo qui, con una considerazione su quanto visto oggi. I problemi da affrontare sono noti: ci sono sempre più utilizzatori potenziali che devono essere messi in condizione di fruire delle risorse disponibili senza colli di bottiglia. Ciò ha spinto alla ricerca di una serie di soluzioni, nel corso degli anni e se nVidia è stata la prima ad innovare con l’introduzione del crossbar, in seguito si è seduta, puntando sulla forza bruta, ovvero sull’utilizzo di un tipo di connessione verso la ram molto complesso e che non le ha permesso, però, di adottare ram ad elevato bit rate come le GDDR5. Sicuramente, in futuro, anche in vista dell’aumento del numero di alu, sarà costretta a modificare l’architettura del MC. Dall’altra parte ATi ha due strade: aumentare ancora il numero di alu (e di cluster) e, in tal caso, sarà da vedere se un crossbar distribuito di soli 256 bit e con 4 MC sarà sufficiente e che tipo di ottimizzazioni si renderanno, eventualmente, necessarie, oppure limitare l’aumento del numero di alu su singolo chip e tentare la strada del multicore. In tal caso, il problema si sposterebbe sull’ottimizzazione del lavoro delle 2 o più gpu che intende mettere nello stesso package o sullo stesso die.
Nello stesso tempo, vediamo che Intel pare intenzionata, con Larrabee, a rilanciare l’idea del ring bus, come mostrato in figura
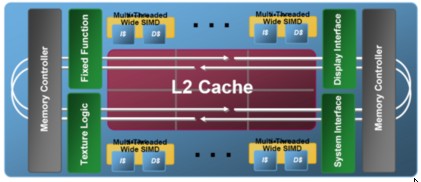
Quello che è certo è che la prossima generazione di GPU, sotto il profilo delle architetture dei MC vedrà ancora delle novità, poichè, all’aumentare delle potenze di calcolo e del parallelismo, la sfida si sposta sempre più sul campo delle architetture preposte al trasferimento ed alla sincronizzazione di questa enorme mole di dati che i futuri chip dovrebbero essere in grado di elaborare.







