La scorsa settimana avevamo introdotto alcuni tra i più comuni approcci al calcolo parallelo e ci eravamo lasciati con la promessa di tornare sulle architetture presentate, con particolare riguardo alla superscalare ed alla vliw. L’intento di oggi è quello di approfondire alcuni aspetti di queste due architetture e di estendere parte dei concetti già visti. Questo ci permetterà di fare una conoscenza un po’ più approfondita delle architetture grafiche di ultima generazione (e non solo).
Come abbiamo visto, sia l’approccio superscalare che quello vliw hanno lo scopo di aumentare il numero di istruzioni per ciclo di clock (IPC) che nelle architetture di tipo pipelined ideali è pari a 1. L’IPC o, se preferite, il suo inverso CIP (cycle per instruction) è il parametro di riferimento per misurare il livello di parallelismo di una determinata architettura. Sia le superscalari che le vliw permettono di avere un valore di IPC > 1, ovvero un valore di CIP < 1. Nell’esempio visto la scorsa settimana (con 3 operazioni per istruzione nel caso vliw e 3 pipeline in parallelo per il superscalare), si ha un valore teorico di IPC pari a 3 (o di CIP pari a 1/3).
Fatta questa premessa, scendiamo un po’ più nel dettaglio. Per quale motivo, chi cerca di incrementare l’ILP dovrebbe adottare l’una anzìchè l’altra? Si tratta di approcci così differenti tra loro? E se si, in cosa differiscono e come queste differenze si ripercuotono sul loro range di utlizzo e, soprattutto, cosa che immagino interesserà di più chi legge, sulle prestazioni? Insomma, esiste un approccio “migliore” di un altro?
Come nelle peggiori tradizioni della letteratura gialla, partiamo dalla fine, ovvero dal nome dell’assassino: non esiste un approccio migliore di un altro in senso assoluto ma ciascuno dei due ha pregi e difetti che lo fanno preferire a seconda degli ambiti e/o degli obbiettivi che chi progetta un chip si prefigge.
Il motivo per il quale si sta focalizzando l’attenzione su queste due architetture tralasciando le altreè da ricercarsi semplicemente nel fatto che si tratta dei due approcci scelti da ATi e nVidia per i loro chip grafici di ultima generazione. In realtà, parlare di vliw vs superscalare è troppo riduttivo, in quanto i chip ATi non sono “solo vliw” e quelli nVidia sono qualcosa di più di superscalari.
La prima grossa differenza che salta agli occhi è quella vista la scorsa settimana: un’architettura superscalare aumenta l’IPC aumentando il numero di pipeline in parallelo tra loro lasciando invariata l’architettura della singola pipeline. In un’architettura vliw, invece, l’IPC si può incrementare sia aumentando la cosiddetta issue width, ovvero il numero di slot che ogni singola long instruction può contenere, ovvero il numero di unità di calcolo gestite dalla singola istruzione (nell’esempio della scorsa settimana avevamo una issue width pari a 3, mentre R600, RV670 ed RV770 ne hanno una pari a 5), sia aumentando il numero di pipeline in parallelo, al pari di quanto avviene con le architetture superscalari.
Già da queste prime considerazioni emergono alcuni tratti distintivi delle due architetture: la superscalare, in quanto composta da pipeline indipendenti che operano in parallelo tra di loro, mantiene una elevata compatibilità con architetture che presentano un livello di paralellismo differente. Quindi il codice scritto per una può girare senza problemi anche su altre. Nel caso delle architetture vliw statiche, invece, l’issue width (IW) può rappresentare un fattore critico in quanto, ad esempio, codice scritto per un processore con IW pari a 3, sarebbe incompatibile con un chip con IW pari a 2 e poco efficiente su uno con IW pari a 4 (o superiore). Ho sottolineato la parola “statiche” perchè si tende erroneamente a classificare allo stesso modo una serie di architetture che presentano gestione dell’ILP in maniera differente e, di conseguenza, un diverso livello di compatibilità con software scritto per altre architetture (mi riferisco alle EPIC acronimo di explicit parallel instruction computer ed alle vliw dinamiche in particolare).
L’altro elemento che emerge è che con un’architettura vliw è più semplice ottenere, in hardware, elevati livelli di parallelismo poichè non serve duplicare tutti gli stadi della pipeline ma solo alcune unità. Questo è uno degli elementi che permette di ottenere una più elevata densità di unità di calcolo a parità di superficie, ossia uno dei motivi, ma non l’unico, per cui ATi è riuscita a mettere 800 floating point unit (fpu) in poco meno di 260 mm^2 mentre nVidia, a parità di processo produttivo, ha dovuto adottare un die di circa 480 mm^2 per implementare 240 fpu.
Daun lato, abbiamo quindi un’architettura che permette una più elevata densità di unità funzionali, dall’altra un’architettura le cui prestazioni sono meno dipendenti dall’ottimizzazione del codice. Ma le differenze non si fermano qui. In un’architettura superscalare l’ILP è gestita at run time da un hardware scheduler mentre in un’architettura vliw è gestita at compile time .
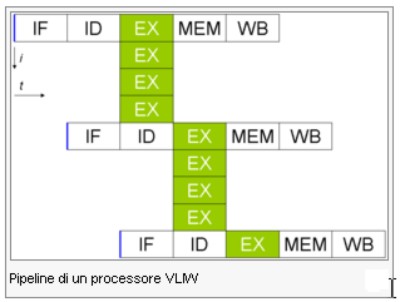
Nella successiva immagine è riportata una pipeline di tipo vliw con una IW pari a 4
Come si può vedere, con un solo stadio di IF (instruction fetch) e ID (instruction decode) è possibile avere un numero variabile di unità di calcolo con conseguente variazione dell’ILP.
In basso è riportata, invece, la differente modalità di gestione dell’ILP tra superscalare (a sinistra) e vliw (a destra)
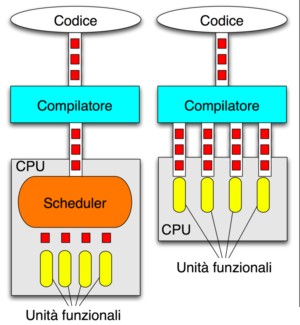
In un’architettura superscalare lo scheduler si occupa delle operazioni di: grouping, ovvero la ricerca delle dipendenze tra le istruzioni da eseguire ed il loro raggruppamento per l’esecuzione in parallelo); fn unit assignement, ossia dell’assegnazione delle istruzioni, individuate durante l’operazione di grouping, alle unità di calcolo; initiation, che consiste nello stabilire e controllare le tempistiche con cui le istruzioni così instradate devono essere eseguite. Per ottenere il massimo dell’efficienza l’hardware scheduler può essere integrato in un’architettura multithreaded che esegue le operazioni in modalità Out of Order con la possibilità di riordinare le istruzioni e rinominare i registri. In tal modo sia la gestione dei carichi di lavoro che quella dell’ILP sono interamente affidate all’hardware.
L’esatto opposto è l’architettura di tipo static vliw , in cui le operazioni di grouping, fn unit assignment e initiation sono gestite interamente dal compilatore. Quali i vantaggi e gli svantaggi di questo approccio rispetto a quello superscalare? Vediamo in breve i principali pro e contro delle due soluzioni.
1) Semplicità circuitale: nettamente in vantaggio la vliw a parità di ILP in quanto, oltre alle considerazioni fatte sul rapporto tra numero di pipeline e di unità funzionali, c’è da tener conto della minor complessità dei circuiti logici e di controllo.
2) Compatibilità con codice preesistente e non ottimizzato: chiaro vantaggio per la superscalare. La vliw presenta troppe limitazioni che le impediscono di raggiungere il massimo ILP teorico possibile con codice non ottimizzato e, in questi casi, la densità di codice è maggiore per l’architettura superscalare.
3) CIP: vantaggio vliw in teoria: meno stadi significa che i dati escono prima dalla pipeline; si tenga conto che ormai gran parte dei cicli di clock sono spesi proprio per i circuiti logici e di controllo. C’è la stessa differenza tra una catena di montaggio in cui ognuno sa quello che deve fare in ogni momento, anche quando non ha niente da fare (NOP) ed una catena di montaggio in cui il lavoro va di volta in volta controllato e riorganizzato. La prima, se e quando tutte le unità sono all’opera presenta degli innegabili vantaggi in termini di velocità di elaborazione; il fatto è che nella stragrande maggioranza dei casi la condizione di massima occupazione non si verificae, di conseguenza, a parità di unità di calcolo e con codice non ottimizzato, finisce col risultare più efficiente, a volte di gran lunga, un’architettura superscalare.
4) Ammortizzamento costi: vantaggio vliw. E’ possibile modificare l’ILP agendo sulla IW con modifiche hardware di poco conto, così come modifiche del compilatore possono essere implementate a costo zero su tutti i chip della stessa famiglia.
5) flessibilità: vantaggio vliw. Una modifica del compilatore è più semplice di una modifica dell’hardware. Ad esempio, nel passaggio da R600 a RV670 è bastato intervenire in misura minima sull’HW per ottenere una piena compatibilità con le DX10.1. Allo stesso modo, è possibile utilizzare le 4 fpu (floating point unit) fp32 di ogni unità vliw di R600 e chip successivi per implementare la precisione di calcolo fp64 mentre sui chip nVidia è stato necessario adottare alu fp64 native. Ancora più flessibile, nei piani di Intel, potrebbe essere Larrabee dal momento che dovrebbe far uso di fixed function solo nelle TMU e non anche nelle ROP’s, come fanno, invece, gli attuali chip. Qui si potrebbe aprire una distriba su unità dedicate ed unità generiche ed efficienza delle une e delle altre. In linea di principio, si può dire che unità dedicate sono più veloci nell’esecuzione dello specifico task ma unità generiche rendono più efficiente l’intera architettura, a parità di modello.
Si può aggiungere che in un’architettura superscalare esiste una distinzione tra physical register, quelli realmente presenti nel chip, e architectural register, quelli visibili a livello di ISA. In un’architettura vliw tutti i registri presenti devono anche essere visibili poichè, in caso contrario, risultano inutilizzati. Il compilatore deve avere l’esatta conoscenza dell’architettura interna del chip e di tutti i parametri, comprese le latenze delle singole operazioni, per poter mettere a punto un POE (plan of execution) corretto, non potendo ricorrere ad operazioni di register renaming e reordering. D’altro canto, questo può essere un vantaggio in quanto il compiler ha una visione completa del problema (microarchitettura del chip più codice) la dove l’hardware scheduler ha una visione solo parziale e ciò può portare a problemi di data dependencies.
Uno dei limiti all’ILP è dato dalla dipendenza dei dati e uno dei casi emblematici è quello dei salti condizionali. Un’architettura vliw statica, al contrario di una superscalare, non applica un controllo dinamico sui flussi, motivo per cui può risolvere il problema solo facendo uso di istruzioni di tipo predicated . Non mi dilungo sull’argomento, ma detto in parole povere, davanti ad un salto condizionato, ossia dinanzi ad un bivio, si sceglie di schedulare entrambi i rami dell’albero. Si fa uso di registri booleani ad 1 bit, uno per ogni ramo, con un’istruzione di tipo IF. Se il registro restituisce il vapore 1 allora l’istruzione viene eseguita, altrimenti si manda in esecuzione una NOP (no operation) e al successivo ciclo si manda in esecuzione l’altro ramo. Questo è uno dei motivi per cui un’architettura vliw necessita di un numero di registri dedicati alla singola alu, superiore rispetto a quelli di un’architettura superscalare.
A metà strada tra le due, ci sono altre architettura note come: dynamic vliw e EPIC.
La prima prevede che le operazioni di grouping e fn unit assignment siano a carico del compilatore mentre quella di initiation avvenga in hardware. In questo caso, si ha un parziale controllo in hardware delle operazioni di scheduling. Questo tipo di architettura è quello utilizzato dai chip ATi della famiglia HD. La complessità circuitale è superiore rispetto a quella di una vliw statica ma si ha la possibilità di meglio integrare le funzionalità dell’hardware dispatch processor, che gestisce il bilanciamento automatico dei carichi di lavoro, con l’architettura vliw delle singole unità funzionali.
La EPIC, invece, prevede che soltanto l’operazione di grouping sia demandata al compiler e tutto il resto sia gestito in hardware. Un esempio di architettura EPIC è dato dalle cpu della famiglia Itanium mentre, ad esempio, i crusoe di Transmeta sono vliw.
Con un approccio di tipo vliw o EPIC è possibile superare il limite di compatibilità intrinseco in architetutre con differente IW grazie alla possibilità di esplorare in maniera dinamica il reale livello di parallelismo di una determinata architettura. Allo steso modo, con una superscalare si può tentare di ovviare all’inconveniente della visione “parziale” del problema da parte delle unità preposte ad organizzare il lavoro del chip anche se ciò introduce un aumento ulteriore della complessità a livello circuitale.
Riassumendo, potremmo dire che l’architettura superscalare garantisce una migliore compatibilità con codice generico che si traduce, sul piano prestazionale, in una maggior efficienza dell’architettura del chip ma presenta una minor flessibilità ed adattabilità ai cambi di specifiche di rigerimento. La vliw, invece, permette di ridurre i costi e di avere una maggior densità di unità di calcolo a parità di superficie, che compensa la minor efficienza complessiva. Da un lato si spostano le difficoltà a livello hardware, dall’altro a livello software.
In pratica, i chip nVidia delle serie G8x e Gt2x0 non sono “semplicemente” superscalari e quelli ATi delle serie HD non sono “solo” vliw.
La definizione che nVidia ha dato dei suoi chip è simultaneous multithreading o SMT che è una sorta di trasposizione dal parallelismo delle istruzioni a quello dei thread. In pratica, come in un chip di tipo superpipelined per ogni ciclo, ad ogni stadio della pipeline è possibile che sia in esecuzione una differente istruzione, in un chip SMT è possibile che, ad ogni ciclo, differenti stadi lavorino su diversi thread. Quindi si potrebbe parlare di TLP (thread level parallelism) piuttosto che di ILP.
Come detto la scorsa settimana, a livello macroscopico, sia l’architettura di GT200 che quella di RV770 è schematizzabile con 10 cluster di alu organizzati come MIMD; ogni cluster di RV770 è composto da 16 unità funzionali operanti in modalità SIMD, ciascuna composta da 5 unità scalari (4 fp32 ed una SFU fp40 in grado di eseguire un’addizione di tipo INTEGER in un solo ciclo contro le 4 richieste per unità fp32) e da una unità di branching in parallelo, che possono operare su differenti istruzioni indipendenti tra di loro e facenti parte dello stesso thread (vliw).
Anche i cluster di GT200 sono organizzati come SIMD a gruppi di 8; quindi ogni cluster, composto da 24 alu fp32, è suddiviso in 3 gruppi di fpu ciascuno dei quali esegue lo stesso tipo di istruzione anche se su dati differenti. La singola alu è ottimizzata per il lavoro di tipo seriale ed è formata da una MADD (moltiplicazione + addizione) con in serie una MUL (moltiplicazione) ed una unità di branching; ogni 4 alu c’è una SFU (special function unit); ogni gruppo di 24 alu è preceduto da una icache, un MT issue e una Ccache che sono rispettivamente la instruction cache, un controller e una compiler cache.
In entrambi i casi si può parlare di architetture SMT poichè quelle che, all’atto pratico, sono le pipeline dei chip (i due chip hanno 10 nodi di ingresso dei dati e delle istruzioni ed altrettanti nodi d’uscita), di fatto possono lavorare su più thread indipendenti simultaneamente.
In futuro ci sarà modo di tornare sulle architetture di GT200 e RV770 e non solo, con considerazioni di carattere generale, qualche analisi più specifica mirata ad alcuni aspetti particolari delle varie architetture e, magari una nostalgica retrospettiva per gli amanti del retrogaming e gli archeologi dell’hardware (come il sottoscritto).
Per il momento, spero di aver iniziato a chiarire il dubbio sollevato da più di qualcuno su qualche forum sul come facesse nVidia con “soli” 240 stream processor (termine quanto mai improprio, visto che si tratta di semplici fpu più registri) a competere e a battere, in molti casi, gli 800 stream processor (idem come la riga precedente) di ATi, al di là delle frequenze elevate dello shader core dei chip di Santa Clara. Come spero di aver iniziato a rispondere alla domanda: come fa ATi con una superficie che è quasi la metà di quella di nVidia a parità di processo produttivo (il chip NVIO esterno mentre per i chip NV) a competere e, talvolta, a battere i prodotti della concorrenza? Entrambe le domande sono legittime ed entrambe trovano una risposta comune nell’analisi dei pregi e dei difetti delle differenti scelte architetturali.







