Nei precedenti due articoli (qui e qui) ho brevemente descritto alcuni schemi di branch prediction, illustrando i punti di forza di ognuno. Alcuni sono facili da costruire e moderatamente efficienti, altri funzionano bene per salti con forte correlazione con la loro storia locale, altri ancora funzionano perfettamente ma solo per alcuni tipi di salti particolari (ad esempio i loop), eccetera.
Visto che ogni programma ha un mix di diversi tipi di salti e diversi programmi hanno un diverso mix, quale di quei predittori scegliere? La soluzione più semplice è quella di scegliere il predittore che fa meglio in media, per un qualche definizione della media: ad esempio, in fase di progettazione, si possono ottenere delle stime dando in pasto dei micro-benchmark al simulatore della CPU (come M5). Benchè la soluzione sia ragionevole vorremmo fare di meglio: vorremmo poter avere a disposizione diversi predittori e usare per ogni salto quello che ne predice meglio il comportamento. Per fare questo dobbiamo usare un predittore ibrido: ci serve cioè un sistema per combinare insieme diversi predittori “base” e generare politiche di aggiornamento sia per i predittori “base” che per il meccanismo di selezione del predittore. Questi sistemi sono ampiamente usati in processori reali.
Tournament predictor
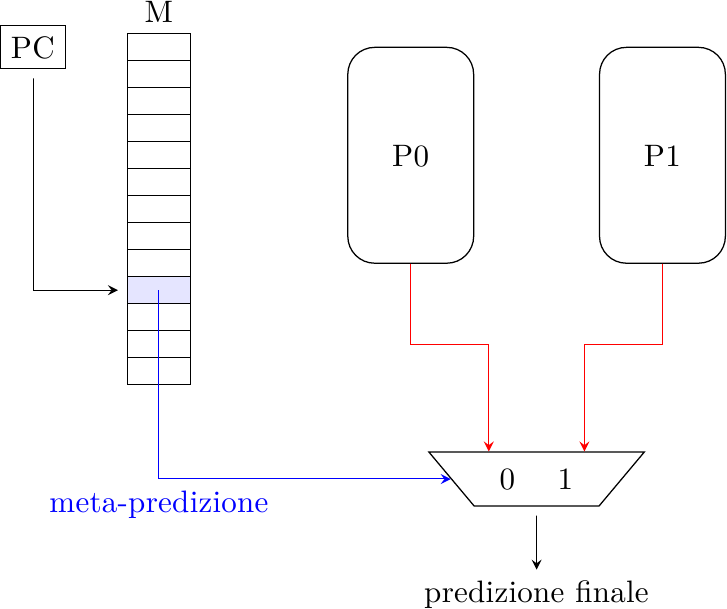
Questo predittore fu proposto dal McFarling (lo stesso del predittore gshare) nel ’93, ed è il primo e il più semplice schema di predittore ibrido. Il predittore consiste di due predittori P0 e P1 (che possono essere un qualsiasi predittore visto nelle puntate precedenti) e un meta-predittore M. Il meta-predittore è una tabella di contatori a 2 bit che funziona come un normale predittore di Smith e dice quale dei predittori, P0 o P1, va usato per generare la predizione di salto; il bit più significativo viene usato per pilotare il mux di selezione:
Quando il salto viene eseguito e la sua direzione è nota, essa viene usata per aggiornare tutte le strutture (P0, P1 e M). I predittori P0 e P1 vengono aggiornati secondo le loro regole. M invece, che è un contatore a saturazione, viene incrementato quando P1 ha predetto correttamente e P0 no, e decrementato nel caso opposto. Se entrambi i predittori hanno predetto correttamente o hanno sbagliato M non cambia, perchè non c’è informazione sufficiente per dire quale dei due si comporta meglio per quel particolare salto.
Una cosa interessante da notare è che P0 e P1 possono essere predittori di qualsiasi tipo, anche un altro predittore ibrido! Ciò significa che è possibile innestare ricorsivamente un predittore tournament dentro un altro, per creare un albero di predittori.
Un predittore di questo tipo è stato usato nell’Alpha 21264 per sfruttare sia la storia locale che quella globale dei salti.
Classificazione dei salti
Questo algoritmo di meta-predizione è di tipo statico, cioè richiede una fase di analisi del codice tramite un profiler. Il programma viene eseguito e il profiler calcola, per ogni salto, quante volte esso viene preso e quante no. I salti vengono quindi divisi in 3 categorie: quelli fortemente non presi (es. < 5%), quelli fortemente presi (es. > 95%) e gli altri. I salti fortemente polarizzati vengono quindi predetti in modo statico (servono ovviamente dei bit nelle istruzioni di salto per codificare questo suggerimento, detto branch hint, e renderlo noto al predittore in fase di esecuzione) mentre gli altri vengono predetti con un normale predittore dinamico, ad esempio un Tournament:
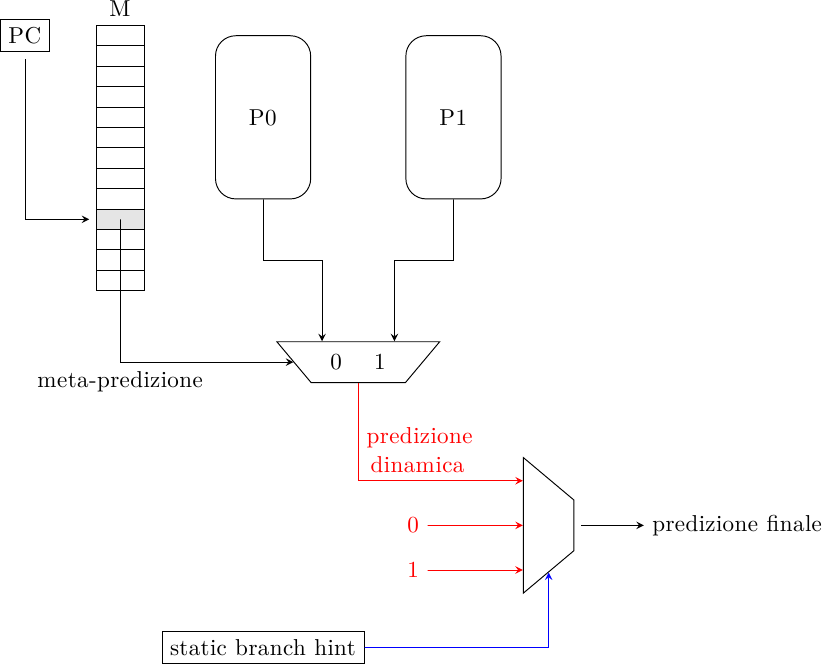
Il vantaggio di questo schema è che i salti fortemente polarizzati, essendo predetti staticamente, non occupano spazio nel predittore dinamico: questo porta ad avere meno aliasing e aumenta le prestazioni del predittore; questo principio è lo stesso del predittore branch filtering. Come tutti i predittori che usano branch hint lo svantaggio è che il “suggerimento” non è disponibile fino a che la decodifica dell’istruzione non è stata completata, il che è un problema perchè il predittore deve generare una nuova predizione ad ogni ciclo di clock per il ciclo successivo, prima che la decodifica sia completata (il problema può essere mitigato tramite pre-decodifica paziale delle istruzioni in cache).
Predittore multi-ibrido
Mentre il predittore tournament è in grado di scegliere tra due diversi predittori di base (a meno di non costruire un albero ricorsivo di predittori) il predittore multi-ibrido può scegliere dinamicamente tra un numero arbitrario di predittori (Evers 1996):
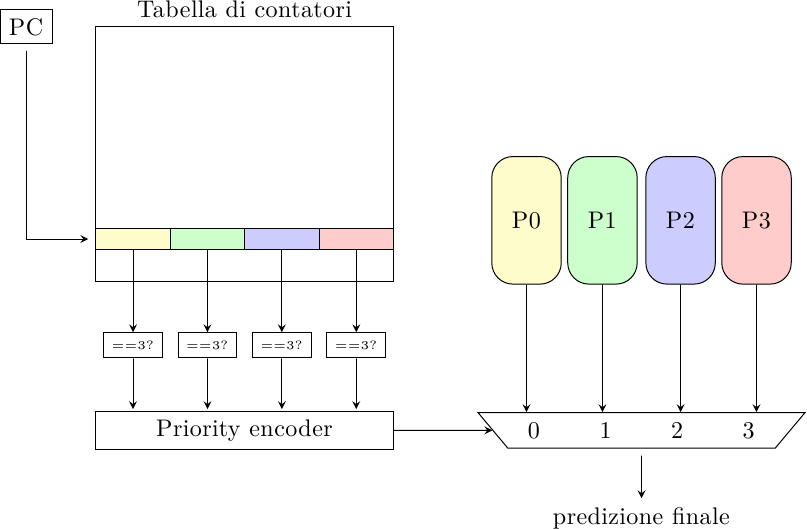
L’indice del salto è usato per accedere ad una tabella di contatori a 2 bit che contiene un contatore per ogni predittore. Il predittore il cui contatore vale 3 (il massimo) viene selezionato per generare la predizione di salto; in caso due o più contatori valgano 3, un priority encoder viene usato per decidere quale scegliere. Tutti i contatori sono inizializzati a 3 e le regole di aggiornamento dei contatori della tabella sono congegnate in modo tale che almeno un contatore abbia sempre il valore massimo, semplificando il problema della selezione.
Lo schema venne proposto per risolvere un problema che si ha nei context switch. Quando si cambia processo, i predittori devono ripartire da zero ed essere riaddestrati da capo; predittori più complessi (e più precisi) richiedono sempre un periodo di addestramento superiore, per cui nelle fasi iniziali dell’addestramento un contatore più semplice può fornire predizioni migliori. Un predittore multi-ibrido può avere un mix di predittori semplici (che generano predizioni abbastanza precise nelle prime fasi dopo il context switch) e complessi (che generano predizioni molto precise una volta che hanno raccolto abbastanza informazioni sui pattern dei salti).
Questo algoritmo è quindi diverso da tutti gli altri visti finora perchè cerca non solo di associare predittori diversi a salti diversi, ma anche predittori diversi allo stesso salto, evolvendo da uno all’altro man mano che maggiori informazioni sul salto diventano disponibili.
Fusione delle predizioni
I predittori ibridi visti finora usano un meccanismo di selezione per scegliere un predittore tra N. Così facendo, però, essi scartano l’eventuale informazione utile contenuta negli altri predittori.
Questa classe di predittori cerca di fondere insieme le predizioni di tutti di N predittori individuali nella speranza di estrarre maggiore informazione sui salti. Uno di questi schemi è chiamato fusion table:
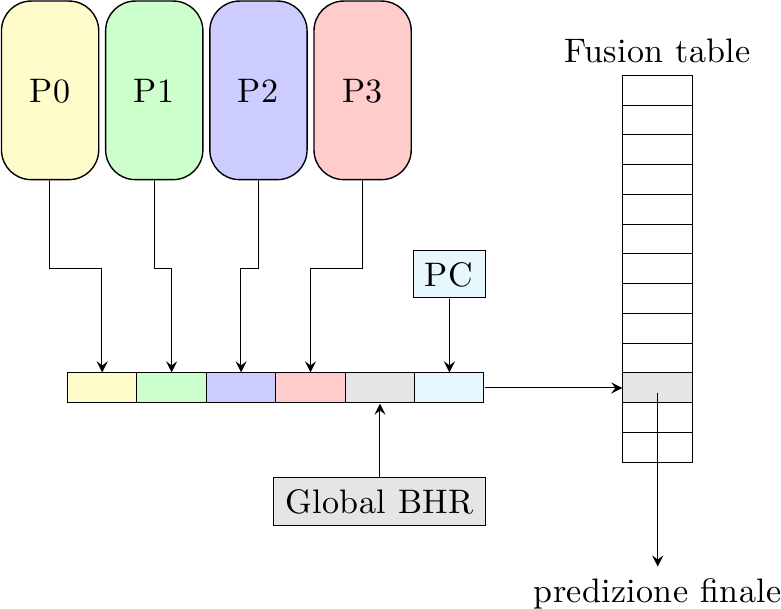
Le predizioni degli N predittori vengono concatenate all’indirizzo del salto e alla storia globale del salto; questo indice viene usato per accedere ad una normale tabella di contatori a saturazione a 2 bit.
Questo predittore è molto flessibile e può essere molto efficace perchè riesce a catturare salti con comportamenti molto diversi. Come sempre, la dimensione dell’indice deve essere tenuta sotto controllo: indici troppo lunghi risultano in tabelle molto grandi e quindi lente, con effetti deleteri sul funzionamento del circuito nel suo complesso.







