
Perché fare analisi sull’evoluzione e struttura di una cultura è sempre stato difficile? Perché non si può semplicemente usare un approccio scientifico per studiare i trend culturali di una popolazione? Semplice, per mancanza di dati. Finora non si è mai riusciti a fare un’analisi veramente quantitativa dello sviluppo culturale della società, per la semplice ragione che non vi sono dei dati oggettivi e in grande quantità da poter analizzare.
Grazie a Google, è invece oggi possibile. Ed è esattamente quello che hanno fatto un gruppo di ricercatori dell‘Harvard University del Massachusetts nella pubblicazione del 16 Dicembre sulla rivista Science. L’idea è stata quella di analizzare, per un periodo di circa 4 anni, un’insieme di dati generato tramite le ricerche di Google Books.
Il dataset è disponibile per il download pubblico, ed è basato sul testo completo di più di 5.2 milioni di libri, per un totale di 500 miliardi di parole, scritte dall’inizio del 1800 fino ai giorni nostri. La maggior parte dell’insieme dei dati è in inglese, ma parte è anche scritto in francese, russo, spagnolo, tedesco e cinese. Questo studio è estremamente nuovo ed importante, perché può tracciare lo sviluppo delle parole in un set di date che copre circa il 4% di tutti i libri mai scritti, utilizzando per la prima volta un approccio quantitativo.
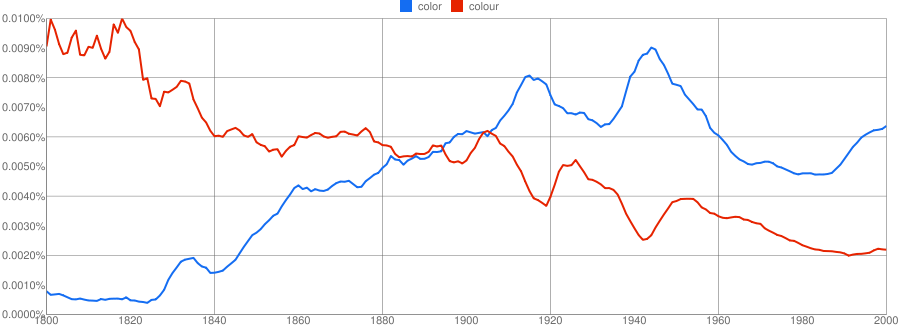
A dimostrazione di ciò, la squadra di ricerca ha anche coniato un nuovo nome per questa “scienza”, chiamandola culturomics, analogamente a genomics. Contando la frequenza con cui appaiono le parole è possibile seguire i trend culturali dell’epoca, e si può anche analizzare lo sviluppo della grammatica, per esempio osservando lo spelling delle parole inglesi e americane (per esempio “colour” o”color”, nel plot a inizio pagina).
I risultati e le nuove opportunità di studio ottenuti da questa analisi sono straordinari. Per esempio, è stato osservato che nella lingua inglese nascono circa 8500 nuove parole ogni anno, ma moltissime di esse non sono presenti nei dizionari. L’universo delle parole è forma da circa il 52% di “materia oscura”, parole usate in letteratura ma non presenti nella documentazione della lingua.
Allo stesso tempo, se le parole aumentano ogni anno, è anche vero che l’umanità si dimentica del proprio passato più velocemente di anno in anno: ogni referenza al passato, in letteratura, diminuisce drasticamente con l’avanzare del tempo. Nel 1912 si parlava ancora spesso del 1880, ma nel 1983 ci si era già dimenticati del 1973.
D’altro canto, e questa non è certo una sorpresa, la diffusione delle novità e delle nuove invenzioni avviene molto più rapidamente. Si parla di nuovi oggetti appena inventati molto più rapidamente ora di quanto non si facesse un secolo fa. Novità anche per quanto riguarda le “star”. Oggi le celebrità sono molto più giovani di quanto lo erano e il secolo scorso e anche molto più famose in giro per il mondo. La loro fama è però molto più breve, in quanto la popolazione tende a dimenticarsi di loro molto più velocemente di quanto non facesse una volta.
La “culturomica” (mia traduzione del termine culturomics) può essere utilizzata anche per individuare censure o tabù culturali. La mancanza nell’utilizzo di certe parole o di citazioni di certi pensatori può infatti farci capire cosa la società sta cercando di nascondere.
Questo studio è stato fatto con la collaborazione di varie aziende linguistiche, come l’Encyclopaedia Britannica e l’American Heritage Dictionary, ma ovviamente Google ha dato un contributo non indifferente. Il centro di ricerca di Google è stato così interessato a questo studio che ha messo addirittura a disposizione un tool, attualmente usufruibile da chiunque, che permette di creare dei grafici come quello che ho fatto all’inizio di questo post. Il tool è a disposizione qui. Divertitevi!







